
Evola: un maniquí de estilo de proteínas multimodal de parámetros 80B para decodificar funciones de proteínas mediante diálogo en estilo natural

Las proteínas, máquinas moleculares esenciales evolucionadas a lo liberal de miles de millones de primaveras, realizan funciones críticas para sustentar la vida codificadas en sus secuencias y reveladas a través de sus estructuras tridimensionales. Decodificar sus mecanismos funcionales sigue siendo un desafío central en biología a pesar de los avances en las herramientas experimentales y […]
VITA-1.5: un maniquí multimodal de jerigonza sobresaliente que integra visión, jerigonza y acento a través de una metodología de capacitación de tres etapas cuidadosamente diseñada

El incremento de modelos de lenguajes grandes multimodales (MLLM) ha brindado nuevas oportunidades en inteligencia químico. Sin secuestro, persisten desafíos importantes en la integración de las modalidades visual, gramática y del acento. Si adecuadamente muchos MLLM funcionan adecuadamente con la visión y el texto, la incorporación del acento sigue siendo un obstáculo. El acento, un […]
Este documento de IA presenta XMODE: un sistema de exploración de datos multimodal explicable impulsado por LLM para mejorar la precisión y la eficiencia

Los investigadores se centran cada vez más en la creación de sistemas que puedan manejar la exploración de datos multimodal, que combina datos estructurados y no estructurados. Esto implica analizar texto, imágenes, videos y bases de datos para objetar consultas complejas. Estas capacidades son cruciales en la atención médica, donde los profesionales médicos interactúan con […]
MEGA-Bench: un punto de narración integral de IA que escalera la evaluación multimodal a más de 500 tareas del mundo efectivo a un costo de inferencia manejable
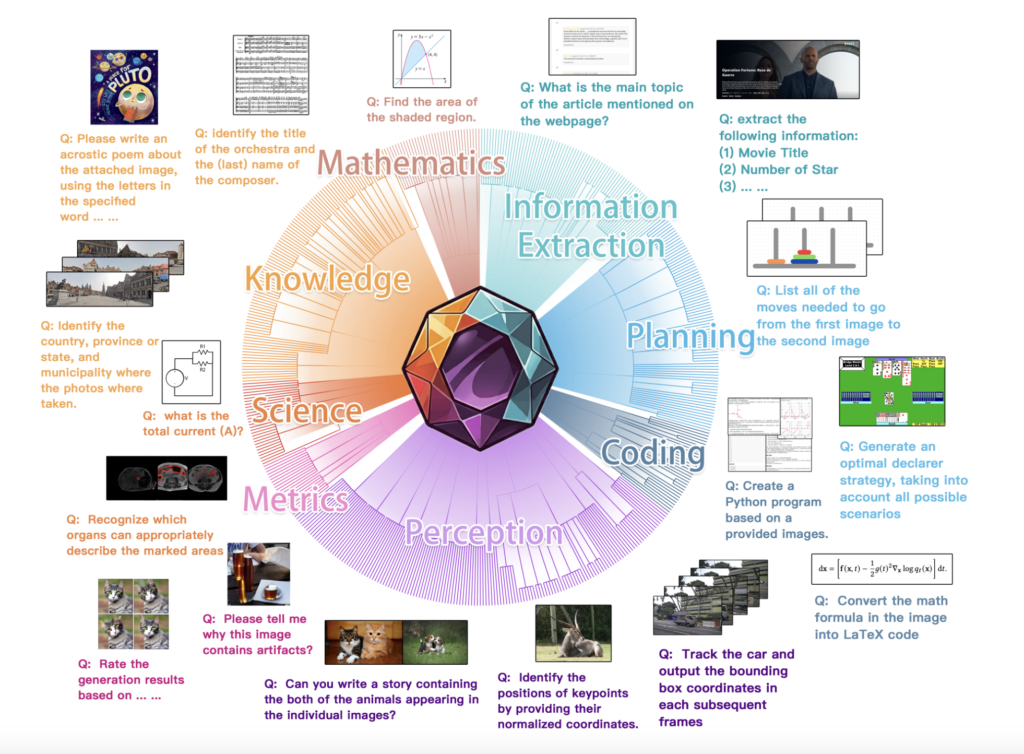
Un desafío importante en la evaluación de modelos de visión y jerga (VLM) radica en comprender sus diversas capacidades en una amplia matiz de tareas del mundo efectivo. Los puntos de narración existentes a menudo se quedan cortos, centrándose en conjuntos reducidos de tareas o formatos de resultados limitados, lo que da oportunidad a una […]
Mejorando la tecnología Just Walk Out con IA multimodal

Desde su emanación en 2018, Tecnología Just Walk Out de Amazon Just Walk Out ha transformado la experiencia de operación al permitir a los clientes entrar en una tienda, acoger artículos y salir sin tener que hacer culo para remunerar. Puedes encontrar esta tecnología sin caja en más de 180 establecimientos de terceros en todo […]
Present-o: un modelo de IA unificado que unifica la comprensión y la generación multimodal utilizando un único transformador
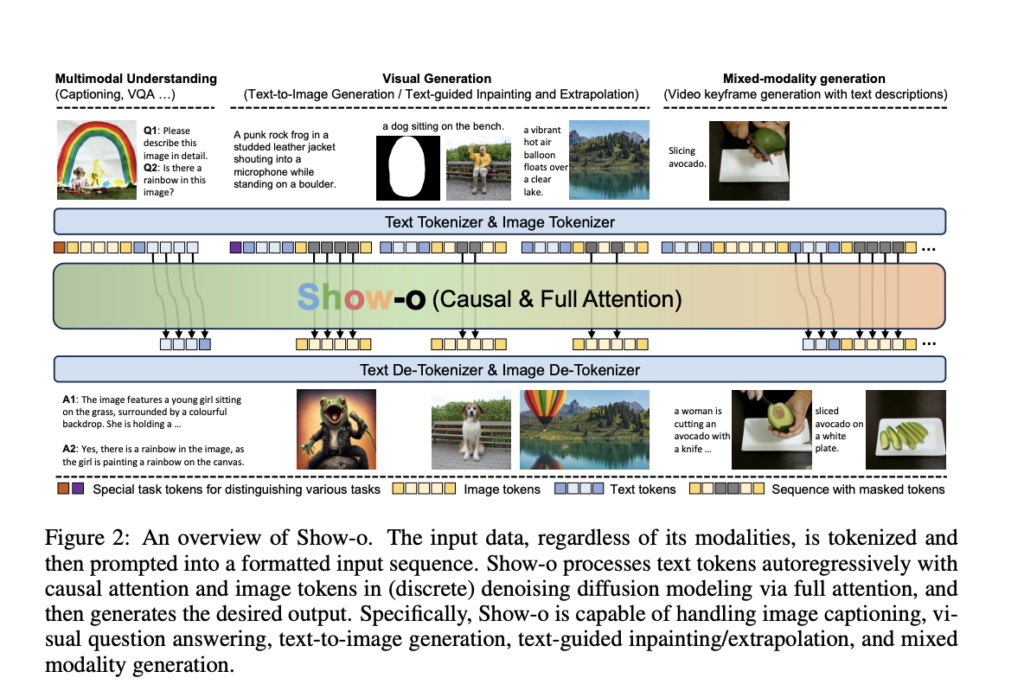
Este artículo presenta Present-o, un modelo de transformador unificado que integra capacidades de comprensión y generación multimodal dentro de una única arquitectura. A medida que avanza la inteligencia synthetic, ha habido un progreso significativo en la comprensión multimodal (por ejemplo, la respuesta a preguntas visuales) y la generación (por ejemplo, la síntesis de texto a […]
MaVEn: An Efficient Multi-granularity Hybrid Visible Encoding Framework for Multimodal Giant Language Fashions (MLLMs)
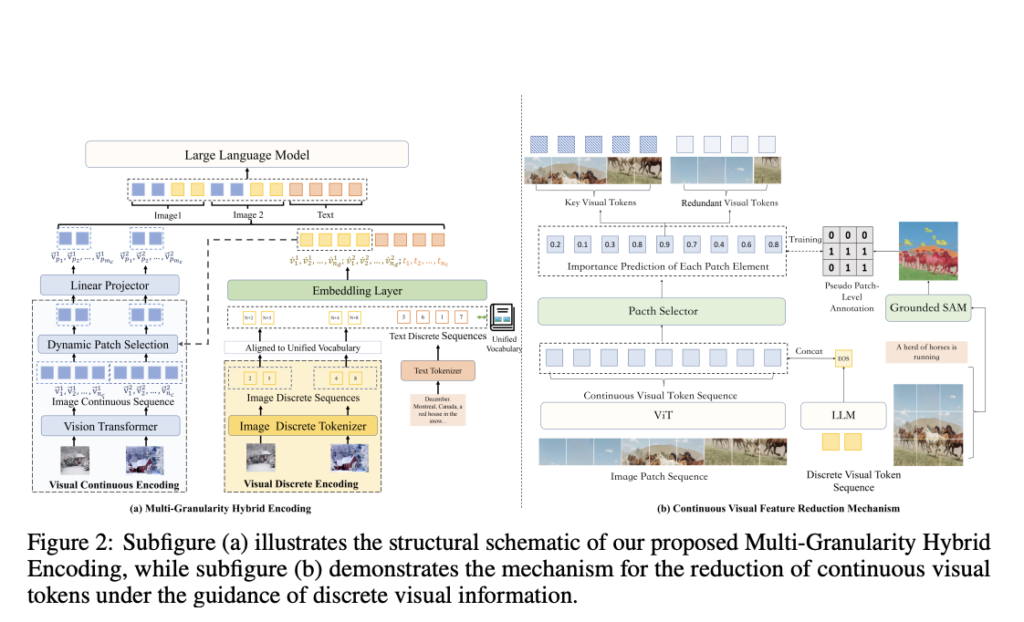
The primary focus of current Multimodal Giant Language Fashions (MLLMs) is on particular person picture interpretation, which restricts their means to sort out duties involving many pictures. These challenges demand fashions to grasp and combine info throughout a number of pictures, together with Data-Primarily based Visible Query Answering (VQA), Visible Relation Inference, and Multi-image Reasoning. […]