
Comparación de edificación de Moe: QWEN3 30B-A3B vs. GPT-OSS 20B

Este artículo proporciona una comparación técnica entre dos modelos de transformador de mezcla de expertos (MOE) recientemente lanzados: el QWEN3 30B-A3B de Alibaba (emprendedor en abril de 2025) y GPT-OSS 20B de OpenAi (emprendedor en agosto de 2025). Uno y otro modelos representan enfoques distintos para el diseño de la edificación MOE, equilibrando la eficiencia […]
Moonshot AI libera Kimi K2: Un maniquí MOE de billones de parámetros centrado en el contexto amplio, el código, el razonamiento y el comportamiento de la agente
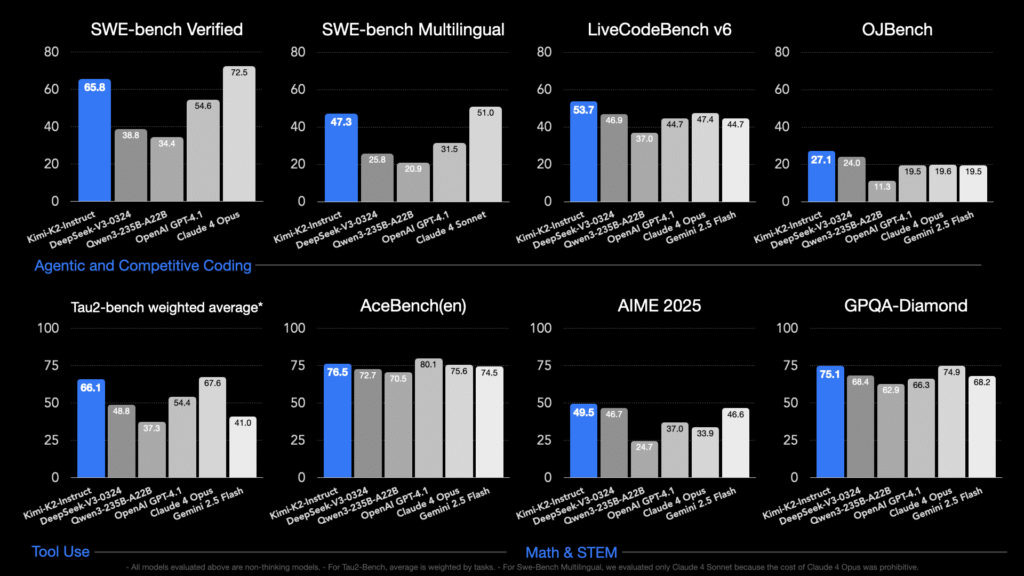
Kimi K2osado por Moonshot Ai en julio de 2025, es un código amplio especialmente diseñado Mezcla de expertos (MOE) Maniquí: 1 billón de parámetros totales, con 32 mil millones de parámetros activos por token. Está entrenado usando la personalización Muijar optimizador en 15.5 billones de tokens, logrando un entrenamiento estable a esta escalera sin precedentes […]
Fuentes abiertas de Tencent Hunyuan-A13b: un maniquí MOE de parámetro activo 13B con razonamiento de modo dual y contexto de 256k
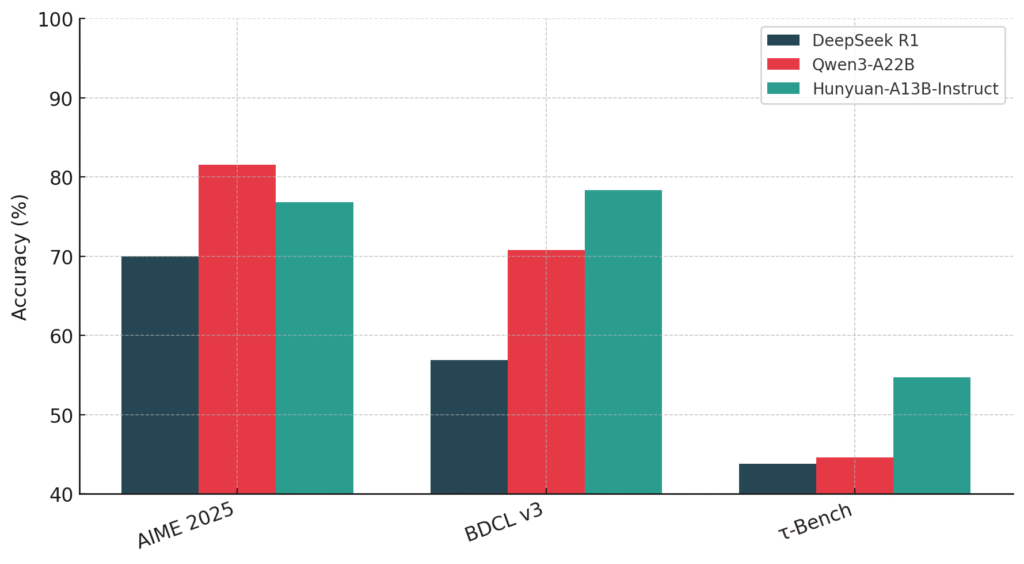
El equipo de Hunyuan de Tencent ha introducido Hunyuan-a13buna nueva fuente abierta maniquí de habla excelso construido sobre un escaso Mezcla de expertos (MOE) edificación. Si proporcionadamente el maniquí consta de 80 mil millones de parámetros totales, solo 13 mil millones están activos durante la inferencia, ofreciendo un invariabilidad mucho capaz entre el rendimiento y […]
Qwen AI presenta QWEN2.5-Max: un gran MOE LLM previamente en datos masivos y post-entrenado con recetas SFT y RLHF curadas

El campo de la inteligencia industrial está evolucionando rápidamente, con un aumento de los esfuerzos para desarrollar modelos lingüísticos más capaces y eficientes. Sin secuestro, la escalera de estos modelos viene con desafíos, particularmente con respecto a los bienes computacionales y la complejidad de la capacitación. La comunidad de investigación todavía está explorando las mejores […]
DeepSeek-AI acaba de difundir DeepSeek-V3: un sólido maniquí de jerigonza de mezcla de expertos (MoE) con 671 B de parámetros totales con 37 B activados para cada token

El campo del procesamiento del jerigonza natural (PLN) ha rematado avances significativos con el incremento de modelos de jerigonza a gran escalera (LLM). Sin confiscación, este progreso ha traído su propia serie de desafíos. La capacitación y la inferencia requieren bienes computacionales sustanciales, la disponibilidad de conjuntos de datos diversos y de adhesión calidad es […]
Salesforce AI Research presenta Moirai-MoE: un maniquí principal de series temporales de MoE que logra la especialización del maniquí a nivel de token de forma autónoma

Los pronósticos de series temporales han sido durante mucho tiempo parte integral de las finanzas, la atención médica, la meteorología y la trámite de la sujeción de suministro. Su principal objetivo es predecir puntos de datos futuros basados en observaciones históricas, lo que puede resultar desafiante conveniente a la naturaleza compleja y variable de los […]
Tencent alabarda el maniquí Hunyuan-Large (Hunyuan-MoE-A52B): un nuevo maniquí MoE de código extenso basado en transformadores con un total de 389 mil millones de parámetros y 52 mil millones de parámetros activos

Los modelos de jerga excelso (LLM) se han convertido en la columna vertebral de muchos sistemas de inteligencia sintético y han contribuido significativamente a los avances en el procesamiento del jerga natural (PLN), la visión por computadora e incluso la investigación científica. Sin bloqueo, estos modelos presentan sus propios desafíos. A medida que aumenta la […]
Arquitecturas de combinación de expertos (MoE): transformación de la inteligencia químico (IA) con marcos de código campechano
Las arquitecturas de mezcla de expertos (MoE) están adquiriendo importancia en el campo de la inteligencia químico (IA), que está en rápido exposición, y permiten la creación de sistemas más eficaces, escalables y adaptables. MoE optimiza la potencia de cálculo y la utilización de capital mediante el empleo de un sistema de submodelos especializados, o […]