
Microsoft Azure AI Foundry Models y Microsoft Security Copilot alcanzar ISO/IEC 42001: 2023 Certificación

Microsoft ha acabado la certificación ISO/IEC 42001: 2023, un standard obligado a nivel mundial para los sistemas de papeleo de inteligencia químico tanto para los modelos Azure AI Foundry como para el copiloto de seguridad de Microsoft. Microsoft ha acabado la certificación ISO/IEC 42001: 2023: un standard obligado a nivel mundial para los sistemas de […]
MaVEn: An Efficient Multi-granularity Hybrid Visible Encoding Framework for Multimodal Giant Language Fashions (MLLMs)
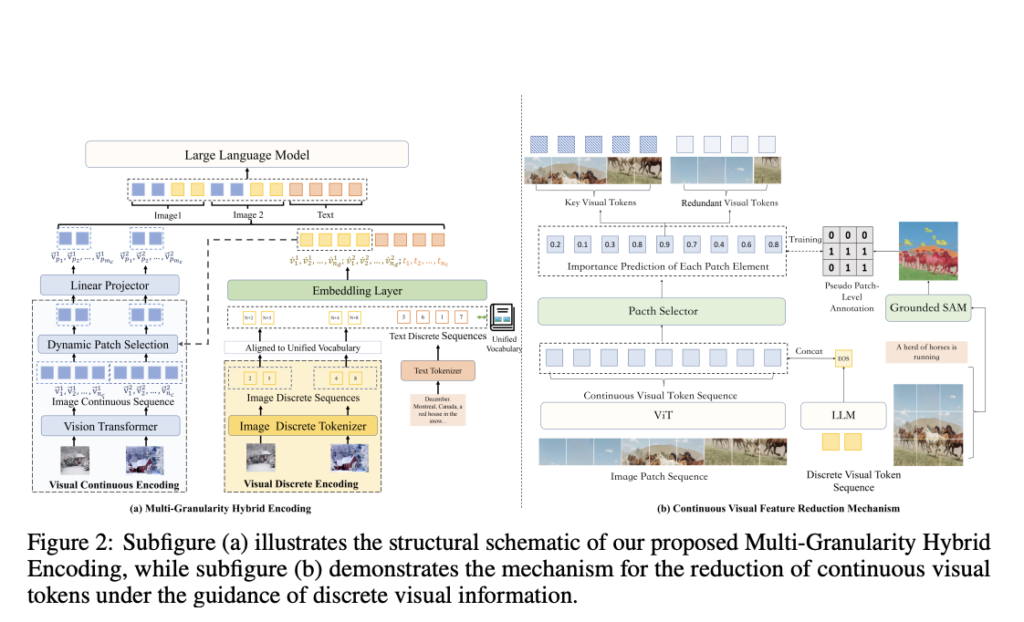
The primary focus of current Multimodal Giant Language Fashions (MLLMs) is on particular person picture interpretation, which restricts their means to sort out duties involving many pictures. These challenges demand fashions to grasp and combine info throughout a number of pictures, together with Data-Primarily based Visible Query Answering (VQA), Visible Relation Inference, and Multi-image Reasoning. […]