
Cómo Laravel Nightwatch maneja miles de millones de eventos de observabilidad en tiempo positivo con Amazon MSK y Clickhouse Cloud

Laravadouno de los marcos web más populares del mundo, lanzó su plataforma de observabilidad de primera parte, Vestigo noctámbulo de Laravelpara proporcionar a los desarrolladores información en tiempo positivo sobre el rendimiento de la aplicación. Construido completamente en los servicios administrados de AWS y Clickhouse Cloudel servicio ya procesa más de mil millones de eventos […]
Presentación de Microsoft Marketplace: miles de soluciones. Millones de clientes. Un mercado.

Una nueva engendramiento de empresas líderes en la industria está tomando forma: las empresas fronterizas. Estas organizaciones combinan la pretensión humana con tecnología con IA para remodelar cómo se escalera la innovación, el trabajo se comparsa y se crea un valía. Están acelerando la transformación de IA para enriquecer las experiencias de los empleados, reinventar […]
Cómo KPMG utiliza el intercambio delta para consentir y auditar decenas de miles de millones de transacciones
El golpe sin interrupciones y seguros a los datos se ha convertido en uno de los mayores desafíos que enfrentan las organizaciones. En ninguna parte es esto más evidente que en las auditorías externas dirigidas por la tecnología, donde el prospección del 100% de los datos transaccionales se está convirtiendo rápidamente en el estereotipado de […]
TILDE AI Liberturas Tildeopen LLM: un maniquí de idioma alto de código rajado con más de 30 mil millones de parámetros y apoya la mayoría de los idiomas europeos

Empresa de tecnología de idioma letón Tilde ha animado Tildeopen LLMun maniquí de jerigonza alto de código rajado (LLM) especialmente diseñado para Idiomas europeoscon un resistente enfoque en idiomas nacionales y regionales subrepresentados y más pequeños. Es un brinco importante cerca de la equidad gramática y la soberanía digital interiormente de la UE. Under the […]
Entrenamiento de 10,000 modelos de detección de anomalías en mil millones de registros con predicciones explicables

El poder de la detección de anomalías en toda la industria Detección de anomalías es una técnica crucial para identificar patrones inusuales que podrían indicar posibles problemas u oportunidades. Algunos usos tempranos de la técnica incluyen ciberseguridad para detectar intrusiones y en finanzas para identificar fraude potencial, pero hoy sus aplicaciones ahora abarcan monitoreo de […]
Los transformadores ahora pueden predecir las células de hoja de cálculo sin ajustar: los investigadores introducen TABPFN capacitado en 100 millones de conjuntos de datos sintéticos

Los datos tabulares se utilizan ampliamente en varios campos, incluidas la investigación científica, las finanzas y la atención médica. Tradicionalmente, estudios forzoso Se han preferido modelos como los árboles de intrepidez aumentados de gradiente para analizar datos tabulares correcto a su efectividad en el manejo de conjuntos de datos heterogéneos y estructurados. A pesar de […]
Descargar decenas de millones de imágenes de contenedores diariamente del Registro de artefactos optimizados sin servidor
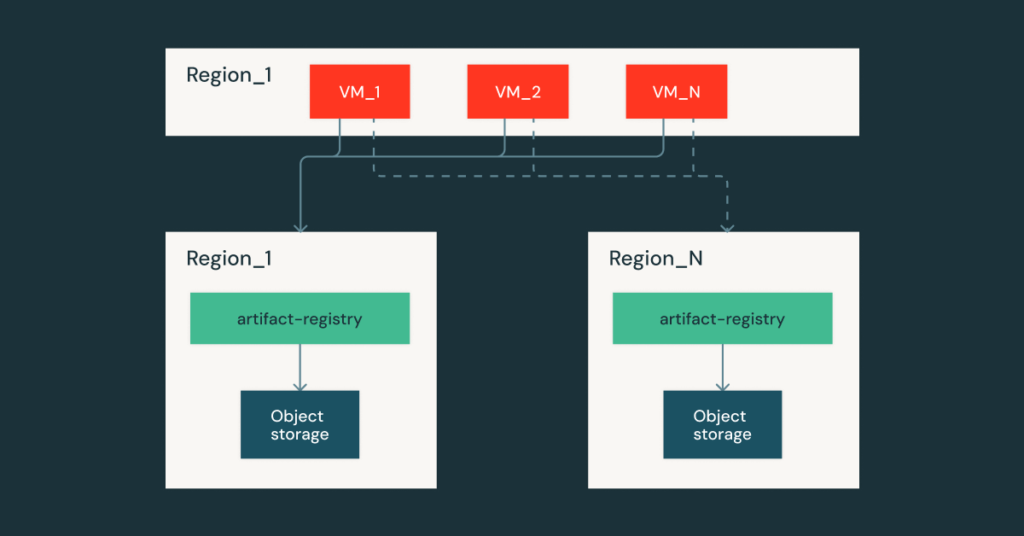
Ingresando a la era sin servidor En este blog, compartimos el alucinación de construir un registro de artefactos optimizado sin servidor desde cero. Los objetivos principales son asegurar la distribución de la imagen del contenedor ambas escamas sin problemas bajo el tráfico sin servidor ruidoso y permanecen disponibles en escenarios desafiantes, como las importantes fallas […]
Snowflake para volver hasta $ 200 millones en nuevas empresas de la próxima engendramiento innovando en su estrato de datos de IA

«Para los fundadores que construyen datos y aplicaciones de IA, es increíblemente valioso poder implementar directamente en los entornos de copo de cocaína de sus clientes: elimina una tonelada de movimiento de datos y gastos generales de seguridad, lo que le permite concentrarse en lo que es núcleo para su producto». dijo Slater Stich, socio […]
Meta AI publica ‘razonamiento natural’: un conjunto de datos de dominios múltiples con 2.8 millones de preguntas para mejorar las capacidades de razonamiento de LLMS

Los modelos de idiomas grandes (LLM) han mostrado avances notables en las capacidades de razonamiento para resolver tareas complejas. Mientras que modelos como Openi’s O1 y Deepseek’s R1 han mejorado significativamente los puntos de narración de razonamiento desafiantes, como las matemáticas de competencia, la codificación competitiva y el GPQA, las limitaciones críticas siguen siendo evaluando […]
Hugging Face aguijada FineMath: el extremo conjunto de datos de preentrenamiento de matemáticas abiertas con más de 50 mil millones de tokens
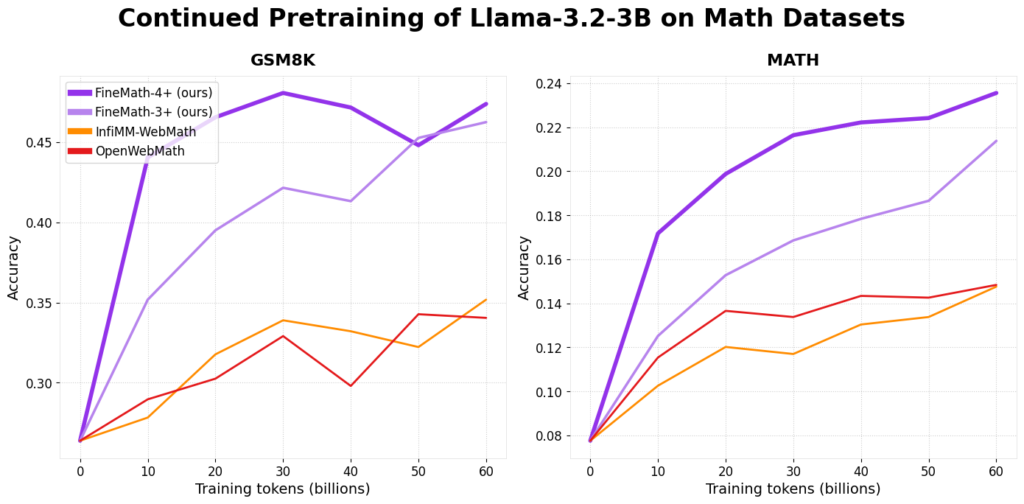
Para la investigación educativa, el golpe a bienes educativos de ingreso calidad es fundamental para estudiantes y educadores. Las matemáticas, a menudo percibidas como una de las materias más desafiantes, requieren explicaciones claras y bienes admisiblemente estructurados para que el educación sea más efectivo. Sin confiscación, crear y curar conjuntos de datos centrados en la […]