
Los afiliados del MIT ganan IA para las subvenciones matemáticas para acelerar el descubrimiento matemático | MIT News

Investigadores del Área de Matemáticas del MIT David Roe ’06 y Andrew Sutherland ’90, PhD ’07 se encuentran entre los destinatarios inaugurales de los mercados de filantropía y XTX del Renacimiento ‘ AI para subvenciones de matemáticas. Cuatro alumnos adicionales del MIT: Anshula Gandhi ’19, Viktor Kunčak SM ’01, PhD ’07; Gireeja Ranade ’07; y […]
Microsoft AI presenta Rstar2-agent: un maniquí de razonamiento matemático de 14B entrenado con un educación de refuerzo de agente para obtener un rendimiento de nivel fronterizo
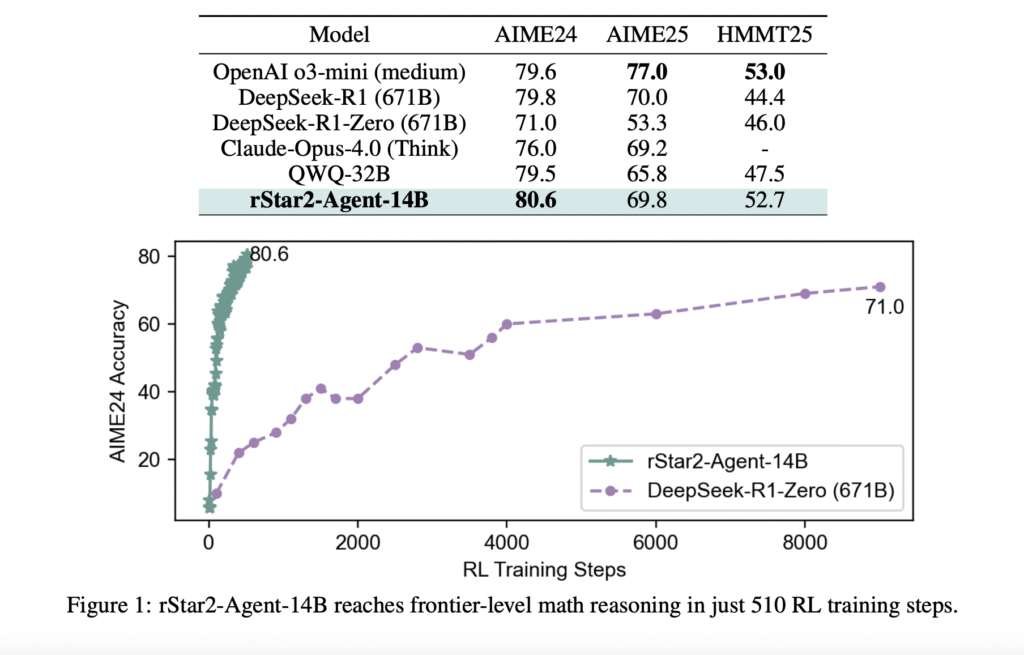
El problema con «pensar más» Los modelos de idiomas grandes han hecho avances impresionantes en el razonamiento matemático al extender sus procesos de sujeción de pensamiento (cot), esencialmente «pensando más tiempo» a través de pasos de razonamiento más detallados. Sin requisa, este enfoque tiene limitaciones fundamentales. Cuando los modelos encuentran errores sutiles en sus cadenas […]
LLMS ahora puede resolver problemas matemáticos desafiantes con datos mínimos: los investigadores de UC Berkeley y AI2 presentan una prescripción de ajuste fino que desbloquea el razonamiento matemático a través de los niveles de dificultad

Los modelos de verbo han hecho avances significativos para tocar las tareas de razonamiento, incluso los enfoques de ajuste finos (SFT) supervisados a pequeña escalera (SFT), como la limusina y el S1, lo que demuestran mejoras notables en las capacidades matemáticas de resolución de problemas. Sin retención, quedan preguntas fundamentales sobre estos avances: ¿estos modelos […]