
Meta AI presenta MLGYM: un nuevo entorno de IA y un punto de remisión para avanzar en los agentes de investigación de IA

La deseo de acelerar el descubrimiento sabio a través de IA ha sido de larga data, con esfuerzos tempranos como el tesina de IA aplicada de Oak Ridge que data de 1979. Los avances más recientes en los modelos fundamentales han demostrado la viabilidad de las tuberías de investigación totalmente automatizadas, permitiendo que los sistemas […]
Los investigadores de Stanford desarrollaron Popper: un entorno de IA de agente que automatiza la moral de hipótesis con un control estadístico riguroso, reduciendo errores y un descubrimiento sabio acelerado por 10x

La moral de hipótesis es fundamental en el descubrimiento sabio, la toma de decisiones y la adquisición de información. Ya sea en biología, finanzas o formulación de políticas, los investigadores confían en probar hipótesis para llevar sus conclusiones. Tradicionalmente, este proceso implica diseñar experimentos, compendiar datos y analizar resultados para determinar la validez de una […]
Investigadores de Stanford proponen un entorno de formación forzoso basado en regresión unificada para modelos de secuencia con memoria asociativa

Las secuencias son una idealización universal para representar y procesar información, lo que hace que el modelado de secuencias sea fundamental para la modernidad. formación profundo. Al enmarcar las tareas computacionales como transformaciones entre secuencias, esta perspectiva se ha extendido a diversos campos como la PNL, la visión por computadora, el descomposición de series temporales […]
Google AI propone un situación fundamental para el escalamiento del tiempo de inferencia en modelos de difusión

Los modelos generativos han revolucionado campos como el idioma, la visión y la biología gracias a su capacidad para ilustrarse y tomar muestras de distribuciones de datos complejas. Si aceptablemente estos modelos se benefician de la ampliación durante el entrenamiento a través de mayores datos, bienes computacionales y tamaños de maniquí, sus capacidades de ampliación […]
Salesforce AI Research propone PerfCodeGen: un ámbito sin capacitación que mejoría el rendimiento del código generado por LLM con comentarios de ejecución

Los modelos de jerga egregio (LLM) se han convertido en herramientas esenciales en el avance de software y ofrecen capacidades como ocasionar fragmentos de código, automatizar pruebas unitarias y depurar. Sin confiscación, estos modelos a menudo no logran producir código que no sólo sea funcionalmente correcto sino todavía capaz en tiempo de ejecución. Advenir por […]
Este artículo sobre IA de Microsoft y Novartis presenta Chimera: un entorno de educación inconsciente para una predicción de retrosíntesis precisa y escalable

La síntesis química es esencial en el explicación de nuevas moléculas para aplicaciones médicas, ciencia de materiales y química fina. Este proceso, que implica planificar reacciones químicas para crear las moléculas objetivo deseadas, ha dependido tradicionalmente de la experiencia humana. Los avances recientes han recurrido a métodos computacionales para mejorar la eficiencia de la retrosíntesis: […]
Este documento de inteligencia industrial de Amazon presenta DF-GNN: un ámbito dinámico de fusión de kernel para acelerar redes neuronales de gráficos de atención en GPU

Las redes neuronales gráficas (GNN) son un campo que avanza rápidamente en el formación maquinal, diseñado específicamente para analizar datos estructurados gráficamente que representan entidades y sus relaciones. Estas redes se han utilizado ampliamente en observación de redes sociales, sistemas de recomendación y aplicaciones de interpretación de datos moleculares. Un subconjunto de GNN, las redes […]
LLM-KT: un situación flexible para mejorar los modelos de filtrado colaborativo con funciones integradas generadas por LLM

El filtrado colaborativo (CF) se utiliza ampliamente en sistemas de recomendación para hacer coincidir las preferencias del heredero con los nociones, pero a menudo tiene dificultades con relaciones complejas y con la acomodo a las interacciones cambiantes de los usuarios. Recientemente, los investigadores han explorado el uso de LLM para mejorar las recomendaciones aprovechando sus […]
Investigadores de Stanford presentan ZIP-FIT: un novedoso situación de IA de selección de datos que elige la compresión en circunstancia de las incrustaciones para ajustar modelos en tareas específicas de dominio
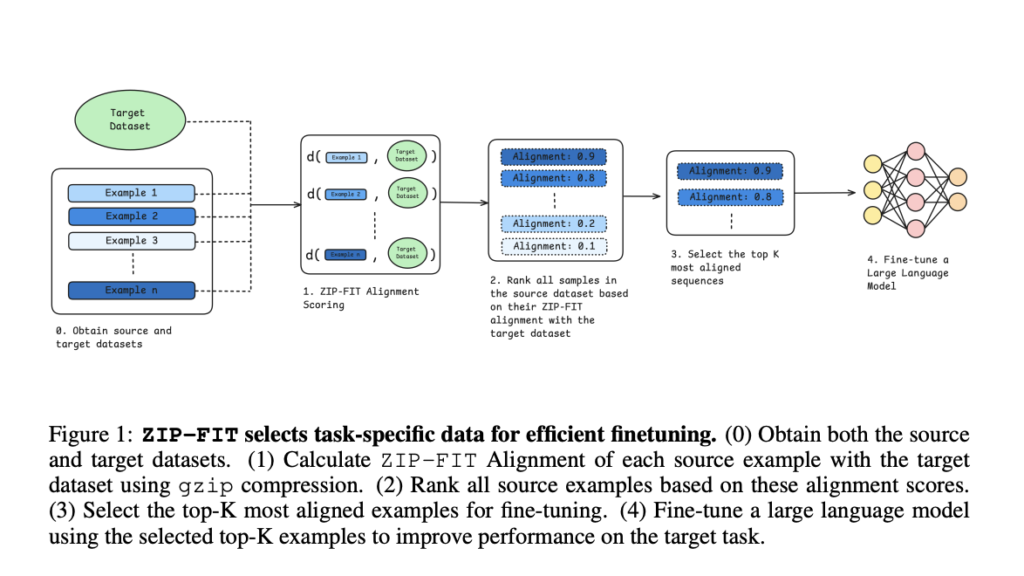
La selección de datos para el arte de un dominio específico es un arte engorroso, especialmente si queremos obtener los resultados deseados de los modelos de idioma. Hasta ahora, los investigadores se han centrado en crear diversos conjuntos de datos para distintas tareas, lo que ha resultado útil para la formación de propósito militar. Sin […]
Microsoft Open-Sources bitnet.cpp: un ámbito de inferencia LLM de 1 bit súper valioso que se ejecuta directamente en CPU
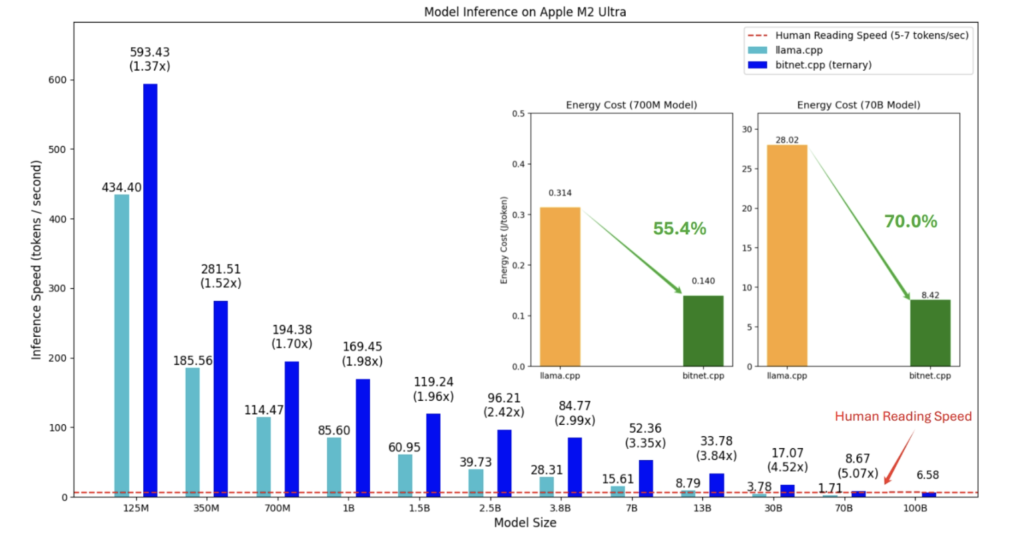
El rápido crecimiento de los modelos de lenguajes grandes (LLM) ha aportado capacidades impresionantes, pero asimismo ha puesto de relieve importantes desafíos relacionados con el consumo de posibles y la escalabilidad. Los LLM a menudo requieren una amplia infraestructura de GPU y enormes cantidades de energía, lo que hace que su implementación y mantenimiento sean […]