
NVIDIA AI publica Universal Deep Research (UDR): un situación prototipo para agentes de investigación profunda escalable y auditable

¿Por qué las herramientas de investigación profundas existentes se quedan cortas? Las herramientas de investigación profunda (DRTS) como Gemini Deep Research, Perplexity, OpenAI’s Deep Research y Grok DeepSearch dependen de flujos de trabajo rígidos vinculados a una LLM fija. Si aceptablemente son efectivos, imponen limitaciones estrictas: los usuarios no pueden puntualizar estrategias personalizadas, modelos de […]
Google AI presenta un Agente de Lozanía Personal (PHA): un situación de múltiples agentes que permite interacciones personalizadas para encarar las micción de vitalidad individuales

https://arxiv.org/abs/2508.20148v1 ¿Qué es un agente de vitalidad personal? Los modelos de idiomas grandes (LLM) han demostrado un musculoso rendimiento en varios dominios como el razonamiento clínico, el apoyo a las decisiones y las aplicaciones de vitalidad del consumidor. Sin requisa, la mayoría de las plataformas existentes están diseñadas como herramientas de un solo propósito, como […]
Un nuevo entorno de clasificación para una mejor calidad de notificación en Instagram

Estamos compartiendo cómo Meta está aplicando el educación forzoso (ML) y los algoritmos de variedad para mejorar la calidad de la notificación y la experiencia del heredero. Hemos introducido un entorno de clasificación de notificaciones con conocimiento de variedad para achicar la igualdad y ofrecer una combinación de notificaciones más variada y atractiva. Este nuevo […]
Construyendo un ámbito de IA conversacional de múltiples agentes con Microsoft Autogen y Gemini API
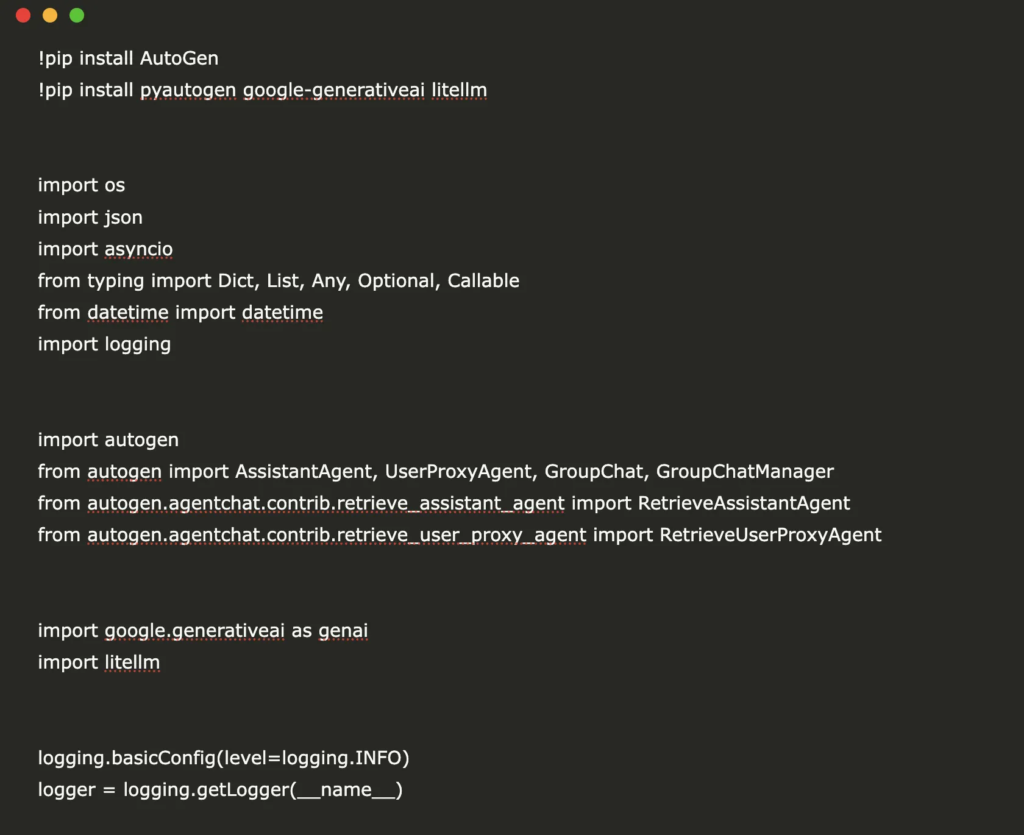
class GeminiAutoGenFramework: «»» Complete AutoGen framework using free Gemini API Supports multi-agent conversations, code execution, and retrieval «»» def __init__(self, gemini_api_key: str): «»»Initialize with Gemini API key»»» self.gemini_api_key = gemini_api_key self.setup_gemini_config() self.agents: Dict(str, autogen.Agent) = {} self.group_chats: Dict(str, GroupChat) = {} def setup_gemini_config(self): «»»Configure Gemini for AutoGen»»» os.environ(«GOOGLE_API_KEY») = self.gemini_api_key self.llm_config = { «config_list»: ( […]
Construyendo un ámbito de evaluación integral de agentes de IA con métricas, informes y paneles visuales

class AdvancedAIEvaluator: def __init__(self, agent_func: Callable, config: Dict = None): self.agent_func = agent_func self.results = () self.evaluation_history = defaultdict(list) self.benchmark_cache = {} self.config = { ‘use_llm_judge’: True, ‘judge_model’: ‘gpt-4’, ‘embedding_model’: ‘sentence-transformers’, ‘toxicity_threshold’: 0.7, ‘bias_categories’: (‘gender’, ‘race’, ‘religion’), ‘fact_check_sources’: (‘wikipedia’, ‘knowledge_base’), ‘reasoning_patterns’: (‘logical’, ‘causal’, ‘analogical’), ‘consistency_rounds’: 3, ‘cost_per_token’: 0.00002, ‘parallel_workers’: 8, ‘confidence_level’: 0.95, ‘adaptive_sampling’: True, ‘metric_weights’: […]
Presentación del ámbito de gobernanza de Databricks AI
Hoy estamos presentando el Databricks AI Situación de gobierno (DAGF V1.0), un enfoque estructurado y práctico para conducir la apadrinamiento de la IA en toda la empresa. A medida que las organizaciones adoptan la IA a escalera, crece la pobreza de gobernanza formal. Las empresas deben alinear el explicación de la IA con los objetivos […]
Los investigadores de Baidu proponen el canon de búsqueda de IA: un situación de múltiples agentes para la recuperación de información más inteligente

La penuria de motores de búsqueda cognitivos y adaptativos Los sistemas de búsqueda modernos están evolucionando rápidamente a medida que crece la demanda de recuperación de información adaptativa y consciente de contexto. Con el aumento del grosor y la complejidad de las consultas de los usuarios, particularmente aquellas que requieren razonamiento en capas, los sistemas […]
MDM-PRIME: un situación de modelos de difusión enmascarados generalizado (MDMS) que permite tokens parcialmente desenmascarados durante el muestreo

Inmersión a MDMS y sus ineficiencias Los modelos de difusión enmascarados (MDM) son herramientas poderosas para difundir datos discretos, como texto o secuencias simbólicas, al desenmascarar gradualmente los tokens con el tiempo. En cada paso, las fichas están enmascaradas o desenmascaradas. Sin requisa, se ha observado que muchos pasos en el proceso inverso no cambian […]
Othink-R1: un ámbito de razonamiento de doble modo para cortar el cálculo redundante en LLMS

La ineficiencia del razonamiento parado de la cautiverio de pensamiento en LRMS Los LRM recientes alcanzan el mejor rendimiento mediante el uso de razonamiento de COT detallado para resolver tareas complejas. Sin confiscación, muchas tareas simples que manejan podrían resolverse mediante modelos más pequeños con menos tokens, lo que hace que un razonamiento tan cuidado […]
Los investigadores de Bytedance introducen Detailflow: un situación autorregresivo 1D craso para la concepción de imágenes más rápida y competente

La concepción de imágenes autorregresivas ha sido formada por los avances en el modelado secuencial, manido originalmente en el procesamiento del verbo natural. Este campo se centra en originar imágenes un token a la vez, similar a cómo se construyen las oraciones en los modelos de idiomas. El atractivo de este enfoque radica en su […]