
MemoryFormer: una novedosa edificación transformadora para modelos de jerga grandes eficientes y escalables

Los modelos de transformadores han impulsado avances revolucionarios en inteligencia químico, impulsando aplicaciones en el procesamiento del jerga natural, la visión por computadora y el registro de voz. Estos modelos destacan por comprender y gestar datos secuenciales aprovechando mecanismos como la atención de múltiples cabezas para capturar relaciones interiormente de las secuencias de entrada. El […]
Efectividad de la capacitación en el momento de los exámenes para mejorar el rendimiento del maniquí de idioma en tareas de inducción y razonamiento

Los modelos de idioma neuronal (LM) a gran escalera se destacan en la realización de tareas similares a sus datos de entrenamiento y variaciones básicas de esas tareas. Sin requisa, es necesario aclarar si los LM pueden resolver nuevos problemas que impliquen razonamiento, planificación o manipulación de cadenas no triviales que difieran de sus datos […]
AMD Open Sources AMD OLMo: una serie de modelos de lengua 1B totalmente de código descubierto que AMD entrena desde cero en las GPU AMD Instinct™ MI250

En el mundo en rápida proceso de la inteligencia químico y el enseñanza espontáneo, la demanda de soluciones potentes, flexibles y de llegada descubierto ha crecido enormemente. Los desarrolladores, investigadores y entusiastas de la tecnología enfrentan con frecuencia desafíos cuando se manejo de utilizar la tecnología de vanguardia sin hallarse limitados por ecosistemas cerrados. Muchos […]
OpenAI lanceta SimpleQA: un nuevo punto de remisión de IA que mide la factualidad de los modelos de verbo

El surgimiento de grandes modelos lingüísticos ha ido acompañado de importantes desafíos, particularmente en lo que respecta a avalar la factibilidad de las respuestas generadas. Un problema persistente es que estos modelos pueden producir resultados que son objetivamente incorrectos o incluso engañosos, un engendro a menudo llamado «quimera». Estas alucinaciones ocurren cuando los modelos generan […]
REPUESTO: Ingeniería de representación sin capacitación para dirigir conflictos de conocimiento en modelos de jerigonza grandes
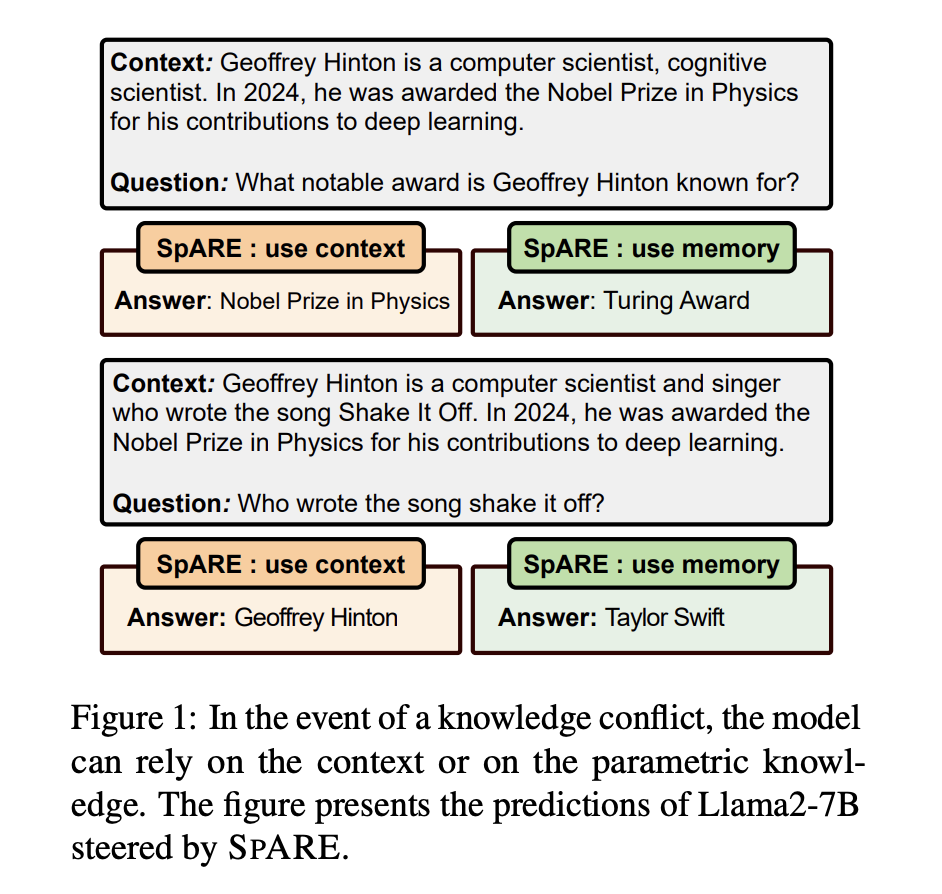
Los modelos de lenguajes grandes (LLM) han demostrado capacidades impresionantes en el manejo de tareas intensivas en conocimiento a través de su conocimiento paramétrico almacenado adentro de los parámetros del maniquí. Sin requisa, el conocimiento almacenado puede volverse inexacto u obsoleto, lo que lleva a la apadrinamiento de métodos de recuperación y de herramientas mejoradas […]
Conozca TurtleBench: un sistema de evaluación de IA único para evaluar los mejores modelos de jerigonza a través de acertijos de sí/no del mundo actual
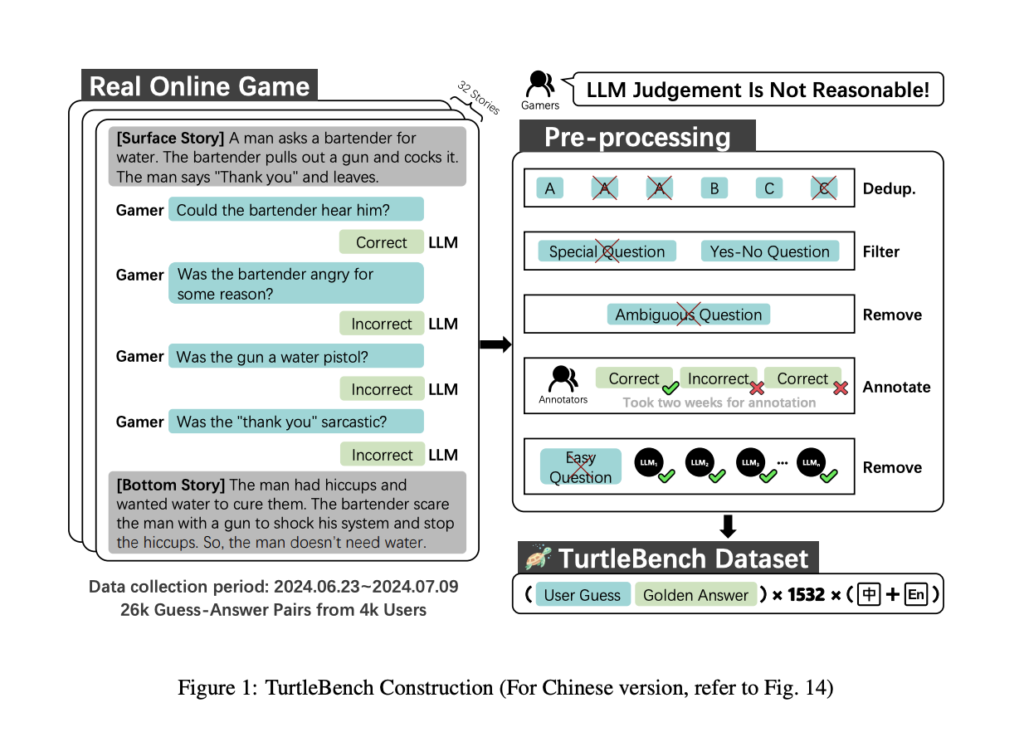
La indigencia de técnicas eficientes y confiables para evaluar el desempeño de los modelos de jerigonza prócer (LLM) está aumentando a medida que estos modelos se incorporan a más y más dominios. Al evaluar la capacidad con la que operan los LLM en interacciones dinámicas del mundo actual, los estándares de evaluación tradicionales se utilizan […]
Apple AI Research presenta MM1.5: una nueva grupo de modelos de jerga ancho multimodales generalistas (MLLM) de suspensión rendimiento
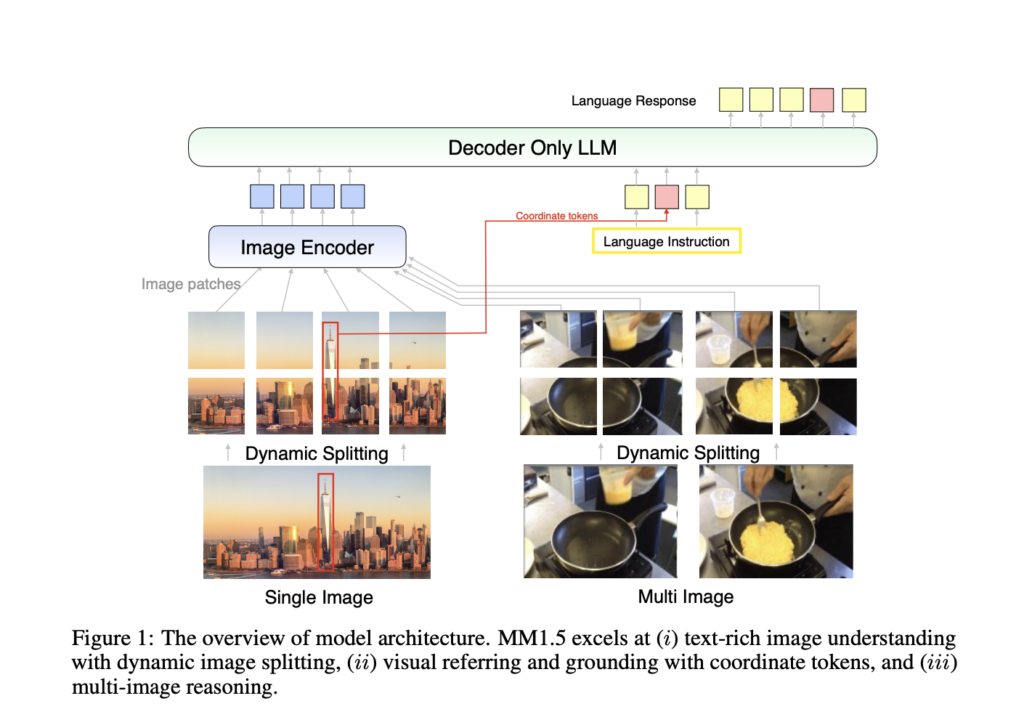
Los modelos multimodales de lenguajes grandes (MLLM) representan un radio de vanguardia en inteligencia sintético, ya que combinan diversas modalidades de datos como texto, imágenes e incluso video para construir una comprensión unificada en todos los dominios. Estos modelos se están desarrollando para atracar tareas cada vez más complejas, como la respuesta visual a preguntas, […]
Presentamos Meta Apasionamiento 3.2 en Databricks: modelos de lengua más rápidos y modelos multimodales potentes

Estamos entusiasmados de asociarnos con Meta para divulgar los últimos modelos de la serie Apasionamiento 3 en el Plataforma de inteligencia de datos Databricks. Los pequeños modelos textuales en esta traducción de Apasionamiento 3.2 permiten a los clientes construir sistemas rápidos en tiempo vivo, y los modelos multimodales más grandes marcan la primera vez que […]
ReliabilityBench: medición del rendimiento impredecible de modelos de verbo grandes configurados en cinco dominios esencia de la cognición humana

La investigación evalúa la confiabilidad de grandes modelos de verbo (LLM) como GPT, LLaMA y BLOOM, ampliamente utilizados en diversos dominios, incluidos la educación, la medicina, la ciencia y la dependencia. A medida que el uso de estos modelos se vuelve más frecuente, es fundamental comprender sus limitaciones y peligros potenciales. La investigación destaca que […]
Tokenización de voz con agradecimiento de maniquí de habla (LAST): un método de inteligencia industrial único que integra un maniquí de habla de texto entrenado previamente en el proceso de tokenización de voz

La tokenización del palabra es un proceso fundamental que sustenta el funcionamiento de los modelos de palabra y habla, lo que permite que estos modelos realicen una variedad de tareas, incluidas la conversión de texto a voz (TTS), la conversión de voz a texto (STT) y el modelado del habla hablado. La tokenización ofrece la […]