
NVIDIA AI resuelto Jet-Nemotron: 53x Serie de maniquí de jerigonza híbrido-arquitectura híbrido que se traduce en una reducción de costos del 98% para la inferencia a escalera
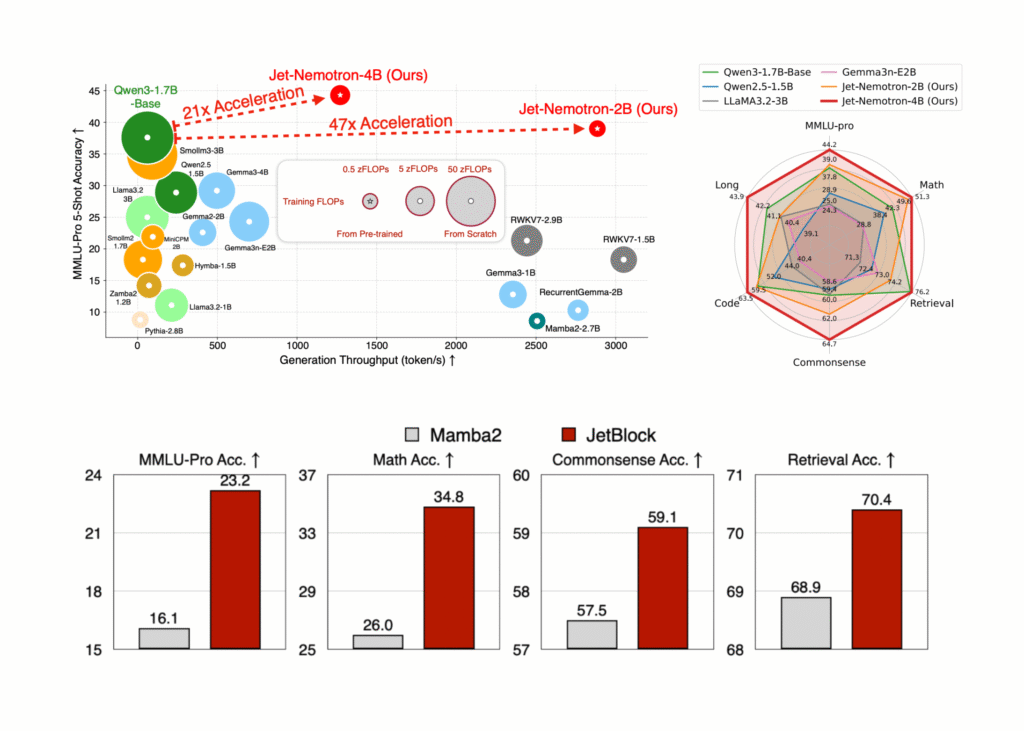
Los investigadores de NVIDIA han destrozado el obstáculo de eficiencia de larga data en la inferencia del maniquí de idioma excelso (LLM), liberando Jet-nemotrón—Un comunidad de modelos (2b y 4b) que ofrece hasta 53.6 × rendimiento de procreación más suspensión que liderar LLM de atención completa mientras coincide, o incluso superando, su precisión. Lo más […]
Comando de Cohere atrevido A: un maniquí de IA de parámetros 111B con duración de contexto de 256k, soporte de 23 idiomas y 50% de reducción de costos para empresas
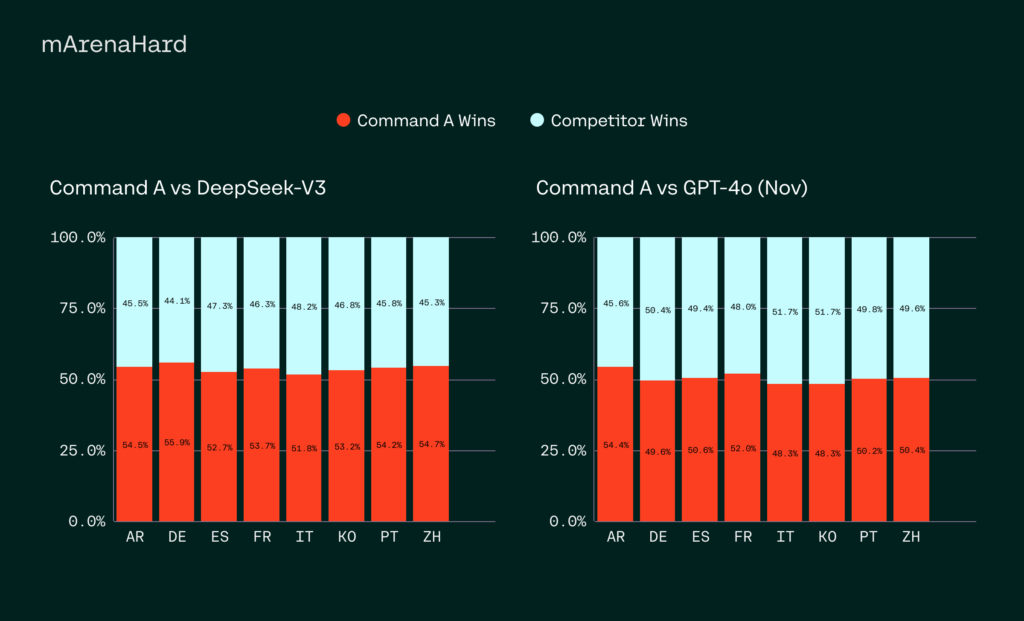
Los LLM se utilizan ampliamente para la IA conversacional, la concepción de contenido y la automatización empresarial. Sin confiscación, equilibrar el rendimiento con la eficiencia computacional es un desafío secreto en este campo. Muchos modelos de última concepción requieren capital de hardware extensos, lo que los hace poco prácticos para empresas más pequeñas. La demanda […]