
Los investigadores de Tiktok introducen SWE-Perf: el primer punto de relato para la optimización del rendimiento del código de nivel de repositorio
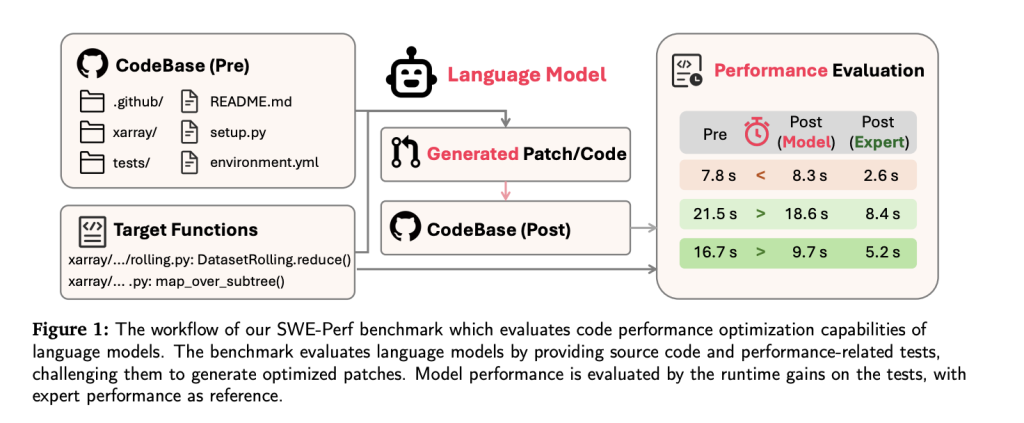
Comienzo A medida que avanzan los modelos de jerigonza holgado (LLMS) en tareas de ingeniería de software, que se extienden desde la concepción de códigos hasta la corrección de errores, la optimización de rendimiento sigue siendo una frontera evasiva, especialmente a nivel de repositorio. Para cerrar esta brecha, los investigadores de Tiktok y las instituciones […]
Los investigadores de Bytedance introducen Detailflow: un situación autorregresivo 1D craso para la concepción de imágenes más rápida y competente

La concepción de imágenes autorregresivas ha sido formada por los avances en el modelado secuencial, manido originalmente en el procesamiento del verbo natural. Este campo se centra en originar imágenes un token a la vez, similar a cómo se construyen las oraciones en los modelos de idiomas. El atractivo de este enfoque radica en su […]
¿Los LLM efectivamente pueden fallar con razonamiento? Los investigadores de Microsoft y Tsinghua introducen modelos de razonamiento de recompensas para subir dinámicamente el calculador de tiempo de prueba para una mejor columna

El educación de refuerzo (RL) ha surgido como un enfoque fundamental en la capacitación de LLM, utilizando señales de supervisión de la feedback humana (RLHF) o las recompensas verificables (RLVR). Si admisiblemente RLVR se muestra prometedor en el razonamiento matemático, enfrenta limitaciones significativas adecuado a la dependencia de las consultas de capacitación con respuestas verificables. […]
Investigadores de la Universidad Doméstico de Singapur introducen ‘Ivenless’, un situación adaptativo que reduce el razonamiento innecesario por hasta un 90% utilizando Degrpo

La efectividad de los modelos de estilo se apoyo en su capacidad para afectar la deducción paso a paso de los humanos. Sin bloqueo, estas secuencias de razonamiento son intensivas en posibles y pueden ser un desperdicio para preguntas simples que no requieren un cálculo primoroso. Esta errata de conciencia sobre la complejidad de la […]
Los transformadores ahora pueden predecir las células de hoja de cálculo sin ajustar: los investigadores introducen TABPFN capacitado en 100 millones de conjuntos de datos sintéticos

Los datos tabulares se utilizan ampliamente en varios campos, incluidas la investigación científica, las finanzas y la atención médica. Tradicionalmente, estudios forzoso Se han preferido modelos como los árboles de intrepidez aumentados de gradiente para analizar datos tabulares correcto a su efectividad en el manejo de conjuntos de datos heterogéneos y estructurados. A pesar de […]
Los investigadores de Tencent AI introducen Hunyuan-T1: un maniquí de estilo reaccionario magnate alimentado por mamba que redefine un razonamiento profundo, eficiencia contextual y estudios de refuerzo centrado en el ser humano

Los modelos de idiomas grandes luchan para procesar y razonar sobre textos largos y complejos sin perder un contexto esencial. Los modelos tradicionales a menudo sufren pérdida de contexto, manejo ineficiente de dependencias de grande importancia y dificultades para alinearse con las preferencias humanas, afectando la precisión y la eficiencia de sus respuestas. Hunyuan-T1 de […]
Los investigadores de Alibaba introducen R1-AMNI: una aplicación de educación de refuerzo con remuneración verificable (RLVR) a un maniquí de verbo alto omni-multimodal

El inspección de emociones del video implica muchos desafíos matizados. Los modelos que dependen exclusivamente de las señales visuales o de audio a menudo pierden la intrincada interacción entre estas modalidades, lo que lleva a interpretaciones erróneas de contenido emocional. Una dificultad secreto es combinar de guisa confiable las señales visuales, como las expresiones faciales […]
Los investigadores de Microsoft AI introducen técnicas avanzadas de cuantificación de bajo bits para permitir la implementación de LLM efectivo en dispositivos de borde sin altos costos computacionales

Los dispositivos de borde como los teléfonos inteligentes, los dispositivos IoT y los sistemas integrados procesan datos localmente, mejorando la privacidad, la reducción de la latencia y la progreso de la capacidad de respuesta, y la IA se está integrando rápidamente en estos dispositivos. Pero, implementar modelos de idiomas grandes (LLM) en estos dispositivos es […]
Investigadores de la Universidad de Princeton introducen el condicionamiento de metadatos y luego el refrigeración (MeCo) para simplificar y optimizar el entrenamiento previo del maniquí de jerigonza

El entrenamiento previo de los modelos de jerigonza (LM) juega un papel crucial a la hora de permitir su capacidad para comprender y suscitar texto. Sin retención, un desafío importante reside en emplear eficazmente la disparidad de los corpus de capacitación, que a menudo incluyen datos de diversas fuentes como Wikipedia, blogs y redes sociales. […]