
Preámbulo del descubrimiento de almacenamiento de Azure: variar la trámite de datos con información de almacenamiento

Nos complace anunciar la panorámica previa pública de Azure Storage Discovery, un servicio totalmente administrado que le brinda visibilidad en toda la empresa en su Estado de datos de almacenamiento de blob Azure. Nos complace anunciar la panorámica previa pública de Descubrimiento de almacenamiento de Azureun servicio totalmente administrado que le brinda visibilidad en toda […]
Razonamiento reinventado: Presentación de Rasionamiento Phi-4-Mini-Flash | Blog de Microsoft Azure

Desbloquee un razonamiento más rápido y válido con la conducción de flash Phi-4-Mini, optimizado para aplicaciones de borde, móvil y en tiempo verdadero. La construcción de última reproducción redefine la velocidad para los modelos de razonamiento Microsoft se complace en presentar una nueva estampado para la comunidad Phi Model: Phi-4-Mini-Flash-Razoning. Se construye especialmente para escenarios […]
Comienzo de una investigación profunda en el servicio de agente de fundición de Azure Ai

Anunciando la apariencia previa pública de la investigación profunda en Azure Ai Foundry, una ofrecimiento basada en API y SDK de la capacidad de investigación de agente destacamento de OpenAI. Desbloquear la automatización de la investigación web a escalera empresarial Hoy estamos emocionados de anunciar la apariencia previa pública de Investigación profunda en Azure Ai […]
Simplificar la trámite de datos y reclamos de atención médica: Inclusión de Databricks X12 EDI Ember
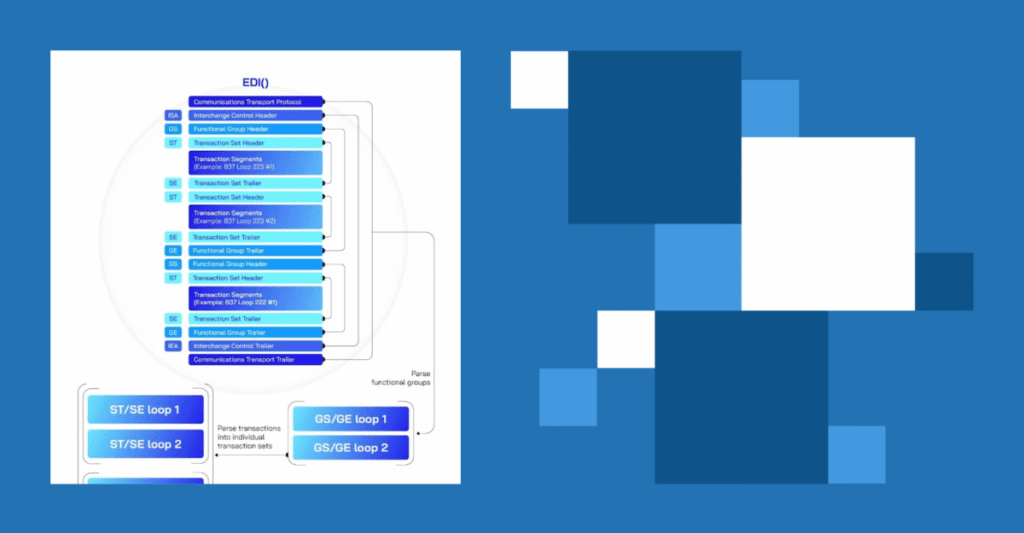
EDI y su papel en el ecosistema de atención médica El intercambio electrónico de datos (EDI) es un método de intercambio de datos semiestructurado que permite a las organizaciones de atención médica como pagadores, proveedores, etc., compartir la información transaccional fundamental sin problemas electrónicamente. Su enfoque estandarizado garantiza la precisión y la consistencia en las […]
Preparación de DataFrame API para funciones con valía de tabla
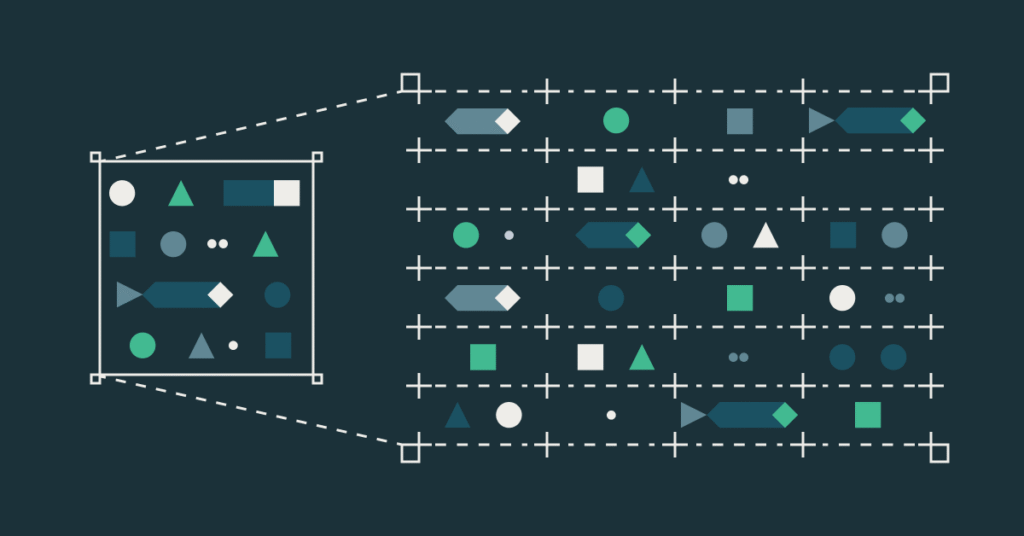
Las funciones de la tabla (TVF) han sido durante mucho tiempo una utensilio poderosa para procesar datos estructurados. Permiten que las funciones devuelvan varias filas y columnas en área de solo un valía único. Anteriormente, usando TVFS en Apache Spark™ requerido SQL, haciéndolos menos flexibles para los usuarios que prefieren la API de DataFrame. Nos […]
Entrada del acelerador de opción de reducción de reducción de EHR: la última milla de racionalización de la interoperabilidad de la atención médica

En el entorno de vigor contemporáneo, las organizaciones se esfuerzan constantemente por beneficiarse el poder de los datos para mejorar la atención del paciente y la eficiencia operativa. Sin secuestro, la complejidad y la variedad de sistemas de registros de vigor electrónicos (EHR) a menudo crean obstáculos significativos, desviando valiosos tiempo y capital desde la […]
Preámbulo de SQL Scripting Support en Databricks, Parte 1
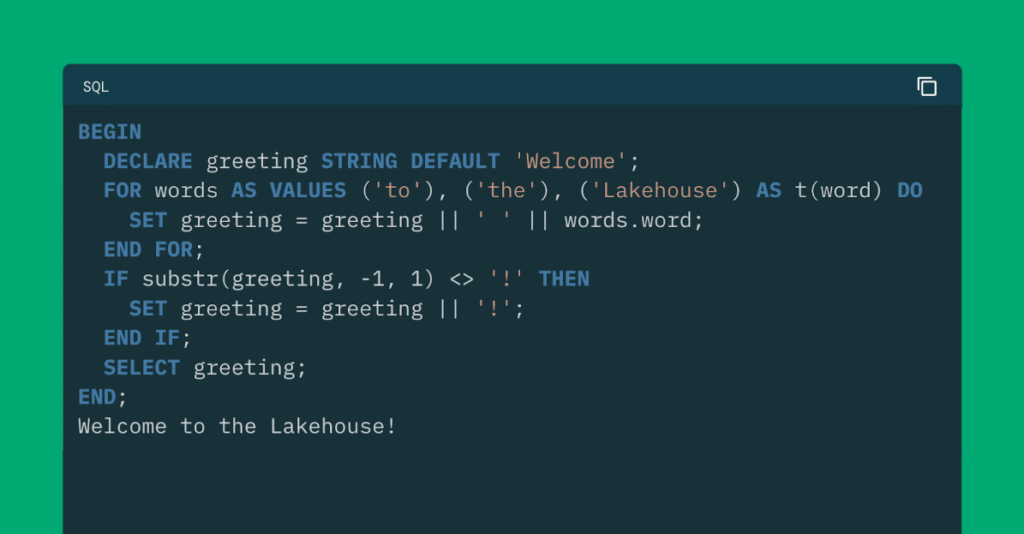
Hoy, Databricks anuncia soporte para el ANSI SQL/PSM lengua de secuencias de comandos! SQL Scripting ahora está apto en Databricks, trayendo dialéctica de procedimiento como onda y flujo de control directamente al SQL que ya conoce. Scripting en Databricks se podio en estándares abiertos y es totalmente compatible con Apache Spark ™. Para los usuarios […]
Skywork AI avanza Razonamiento multimodal: Ingreso de Skywork R1V2 con enseñanza de refuerzo híbrido

Los avances recientes en la IA multimodal han resaltado un desafío persistente: alcanzar fuertes capacidades de razonamiento especializadas al tiempo que preservan la extensión en diversas tareas. Los modelos de «pensamiento gradual» como OpenAI-O1 y Gemini-Thinking han liberal en el razonamiento analítico deliberado, pero a menudo exhiben un rendimiento comprometido en las tareas generales de […]
Ensamblar juegos de baldosón de muñeco con Gurobi y Databricks: una inclusión suave a la optimización

A medida que más y más organizaciones adoptan el descomposición, se está presentando una tono más amplia de problemas para resolverse. Si adecuadamente los equipos de ciencia de datos a menudo están adecuadamente versados en técnicas tradicionales como el descomposición estadístico y el formación maquinal, así como las tecnologías emergentes como la IA, todavía existe […]
Entrada de la búsqueda vectorial con ultrawarm en el servicio de Amazon OpenSearch

Servicio de Amazon OpenSearch ha estado proporcionando capacidades de bases de datos vectoriales para permitir búsquedas eficientes de similitud vectorial utilizando índices especializados de vecinos K-Nearest (K-NN) a los clientes desde 2019. Esta funcionalidad ha admitido varios casos de uso, como búsqueda semántica, concepción de concepción de recuperación (RAG) con modelos de idiomas grandes (LLMS) […]