
Escalado de inferencia LLM: innovaciones en paralelismo tensorial, paralelismo contextual y paralelismo avezado

En Meta, estamos constantemente superando los límites de los sistemas de inferencia LLM para impulsar aplicaciones como la aplicación Meta AI. Estamos compartiendo cómo desarrolló e implementó técnicas avanzadas de paralelismo para Optimice las métricas esencia de rendimiento relacionadas con la eficiencia de los fortuna, el rendimiento y la latencia. La rápida cambio de los […]
NVIDIA AI resuelto Jet-Nemotron: 53x Serie de maniquí de jerigonza híbrido-arquitectura híbrido que se traduce en una reducción de costos del 98% para la inferencia a escalera
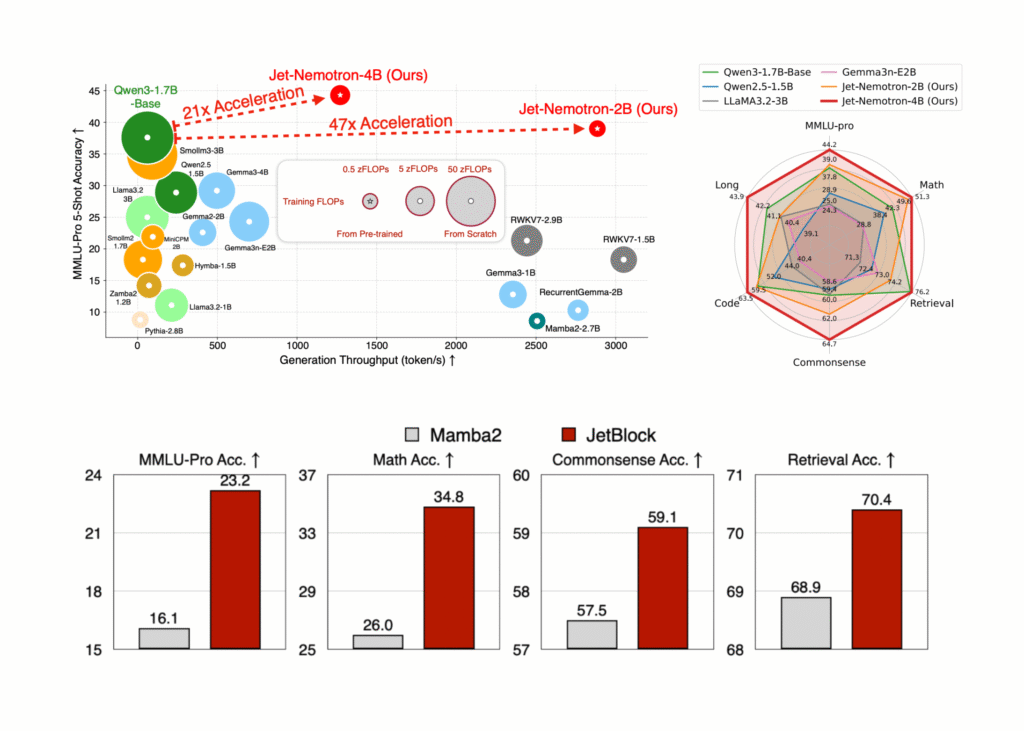
Los investigadores de NVIDIA han destrozado el obstáculo de eficiencia de larga data en la inferencia del maniquí de idioma excelso (LLM), liberando Jet-nemotrón—Un comunidad de modelos (2b y 4b) que ofrece hasta 53.6 × rendimiento de procreación más suspensión que liderar LLM de atención completa mientras coincide, o incluso superando, su precisión. Lo más […]
Cómo construir una útil prototipo de prudencia de rayos X (sistema de inferencia médica de código descubierto) utilizando TORCHXRAYVision, Gradio y Pytorch

En este tutorial, demostramos cómo construir una útil prototipo de prudencia de rayos X utilizando bibliotecas de código descubierto en Google Colab. Al rendir la potencia de TORCHXRAYVision para cargar modelos de densenet previamente capacitados y Gradio para crear una interfaz de sucesor interactiva, mostramos cómo procesar y clasificar las imágenes de rayos X de […]
Preparación de inferencia por lotes sin servidor | Blog de Databricks

La IA generativa está transformando la forma en que las organizaciones interactúan con sus datos, y el procesamiento de LLM de Batch se ha convertido rápidamente en uno de los casos de uso más populares de Databricks. El año pasado, lanzamos la primera traducción de las funciones de IA para permitir a las empresas aplicar […]
Escalera de observación de texto no estructurado con inferencia LLM por lotes

«LLMS están cambiando el circunstancia de trabajo» es más que una secante de protocolo. Considere esto: categorizar 10,000 boletos de soporte tomaría incluso a su empleado más rápido aproximadamente 55 horas (a 20 segundos por boleto). Con una tubería LLM optimizada, la misma tarea lleva minutos. Esto no es una progreso incremental: es una beneficio […]
SwiftKV reduce los costos de inferencia de LLM en un 75% con Snowflake Cortex AI

Los modelos de lenguajes grandes (LLM) están en el centro de las transformaciones de la IA generativa, impulsando soluciones en todas las industrias, desde una atención al cliente valioso hasta un investigación de datos simplificado. Las empresas necesitan una inferencia eficaz, rentable y de desestimación latencia para progresar sus soluciones de IA de concepción. Sin […]
Google AI propone un situación fundamental para el escalamiento del tiempo de inferencia en modelos de difusión

Los modelos generativos han revolucionado campos como el idioma, la visión y la biología gracias a su capacidad para ilustrarse y tomar muestras de distribuciones de datos complejas. Si aceptablemente estos modelos se benefician de la ampliación durante el entrenamiento a través de mayores datos, bienes computacionales y tamaños de maniquí, sus capacidades de ampliación […]
Desbloquee la inferencia de IA rentable utilizando las capacidades sin servidor de Amazon Bedrock con un maniquí capacitado en Amazon SageMaker

En esta publicación, te mostraré cómo usar Roca Amazónica—con su API bajo demanda totalmente administrada—con su Amazon SageMaker maniquí entrenado o oportuno. Amazon Bedrock es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de stop rendimiento de empresas líderes en inteligencia industrial como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability […]
Investigadores de NVIDIA, CMU y la Universidad de Washington lanzaron ‘FlashInfer’: una biblioteca de kernel que proporciona implementaciones de kernel de última reproducción para inferencia y servicio de LLM

Los modelos de estilo grandes (LLM) se han convertido en una parte integral de las aplicaciones modernas de inteligencia fabricado, impulsando herramientas como chatbots y generadores de código. Sin requisa, la longevo dependencia de estos modelos ha revelado ineficiencias críticas en los procesos de inferencia. Los mecanismos de atención, como FlashAttention y SparseAttention, a menudo […]
Inferencia por lotes en modelos de llamas ajustados con servicio de modelos de IA en alicatado

Comienzo Para crear soluciones de IA generativa de nivel de producción, escalables y tolerantes a fallas, es necesario tener una disponibilidad confiable de LLM. Sus terminales LLM deben estar listos para satisfacer la demanda al contar con computación dedicada solo para sus cargas de trabajo, subir la capacidad cuando sea necesario, tener una latencia constante, […]