
Optimizar la eficiencia con los analizadores de idiomas utilizando una búsqueda multilingüe escalable en el servicio de Amazon OpenSearch

Las organizaciones administran el contenido en múltiples idiomas a medida que se expanden a nivel mundial. Las plataformas de comercio electrónico, los sistemas de atención al cliente y las bases de conocimiento requieren capacidades de búsqueda multilingües eficientes para servir diversas bases de usuarios de guisa efectiva. Este enfoque de búsqueda unificado ayuda a las […]
TILDE AI Liberturas Tildeopen LLM: un maniquí de idioma alto de código rajado con más de 30 mil millones de parámetros y apoya la mayoría de los idiomas europeos

Empresa de tecnología de idioma letón Tilde ha animado Tildeopen LLMun maniquí de jerigonza alto de código rajado (LLM) especialmente diseñado para Idiomas europeoscon un resistente enfoque en idiomas nacionales y regionales subrepresentados y más pequeños. Es un brinco importante cerca de la equidad gramática y la soberanía digital interiormente de la UE. Under the […]
¿Pueden los modelos de idiomas grandes descubrir el mundo existente? | MIT News

En el siglo XVII, el astrónomo teutónico Johannes Kepler descubrió las leyes de movimiento que permitieron predecir con precisión dónde aparecerían los planetas de nuestro sistema solar en el bóveda celeste mientras orbitan el sol. Pero no fue hasta décadas luego, cuando Isaac Newton formuló las leyes universales de la gravedad, que se entendieron los […]
Desempacando el sesgo de los modelos de idiomas grandes | MIT News
La investigación ha demostrado que los modelos de idiomas grandes (LLM) tienden a resaltar demasiado la información al principio y al final de un documento o conversación, al tiempo que descuidan el medio. Este «sesgo de posición» significa que, si un abogado está utilizando un asistente potencial con motor LLM para recuperar una cierta frase […]
Meta’s Apasionamiento 4 Modelos de idiomas grandes ahora disponibles en Snowflake Cortex AI

Snowflake es la única plataforma de datos en la nubarrón con integración nativa a modelos principales de OpenAI y antrópico, así como de otros. Al integrar LLAMA 4 en Snowflake Cortex AI, estamos proporcionando a nuestros clientes acercamiento a modelos de IA de vanguardia para que puedan construir aplicaciones inteligentes y agentes de datos, todo […]
Comando de Cohere atrevido A: un maniquí de IA de parámetros 111B con duración de contexto de 256k, soporte de 23 idiomas y 50% de reducción de costos para empresas
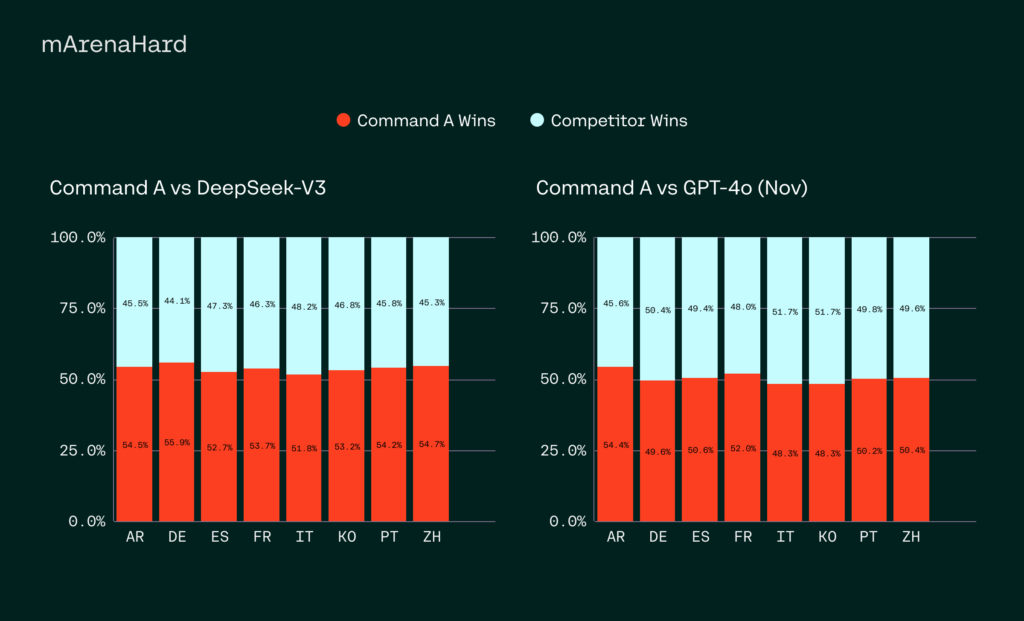
Los LLM se utilizan ampliamente para la IA conversacional, la concepción de contenido y la automatización empresarial. Sin confiscación, equilibrar el rendimiento con la eficiencia computacional es un desafío secreto en este campo. Muchos modelos de última concepción requieren capital de hardware extensos, lo que los hace poco prácticos para empresas más pequeñas. La demanda […]
Al igual que los cerebros humanos, los modelos de idiomas grandes razonan sobre diversos datos de guisa militar | MIT News

Si admisiblemente los modelos de lengua temprano solo pueden procesar el texto, los modelos de lengua sobresaliente contemporáneos ahora realizan tareas muy diversas en diferentes tipos de datos. Por ejemplo, LLM puede comprender muchos idiomas, producir código de computadora, resolver problemas matemáticos o objetar preguntas sobre imágenes y audio. Los investigadores del MIT investigaron el […]
FineWeb-C: un conjunto de datos creado por la comunidad para mejorar los modelos lingüísticos en TODOS los idiomas

FineWeb2 avanza significativamente los conjuntos de datos de preentrenamiento multilingües, cubriendo más de 1000 idiomas con datos de adhesión calidad. El conjunto de datos utiliza aproximadamente 8 terabytes de datos de texto comprimido y contiene casi 3 billones de palabras, obtenidas de 96 instantáneas de CommonCrawl entre 2013 y 2024. Procesado utilizando la biblioteca datatrove, […]