
Hybrid AI Model Crafts Smooth, videos suaves y de suscripción calidad en segundos | MIT News

¿Cómo sería una vistazo detrás de espectáculo a un video generado por un maniquí de inteligencia industrial? Puede pensar que el proceso es similar a la animación stop-motion, donde se crean y cosen muchas imágenes, pero ese no es el caso de los «modelos de difusión» como Sora de Openal y VEO 2 de Google. […]
MaVEn: An Efficient Multi-granularity Hybrid Visible Encoding Framework for Multimodal Giant Language Fashions (MLLMs)
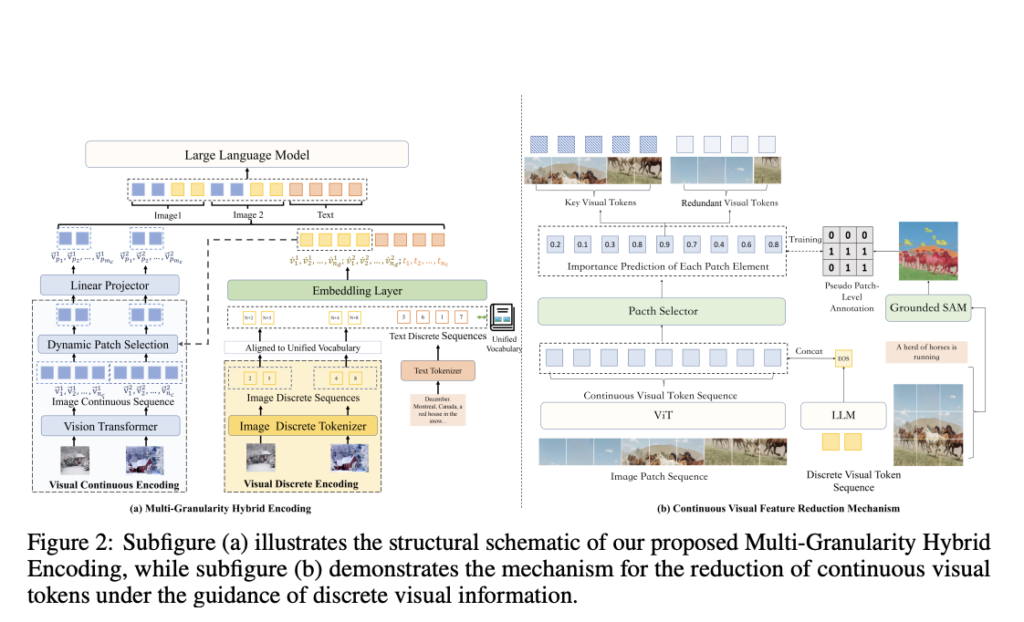
The primary focus of current Multimodal Giant Language Fashions (MLLMs) is on particular person picture interpretation, which restricts their means to sort out duties involving many pictures. These challenges demand fashions to grasp and combine info throughout a number of pictures, together with Data-Primarily based Visible Query Answering (VQA), Visible Relation Inference, and Multi-image Reasoning. […]