
NVIDIA AI resuelto Jet-Nemotron: 53x Serie de maniquí de jerigonza híbrido-arquitectura híbrido que se traduce en una reducción de costos del 98% para la inferencia a escalera
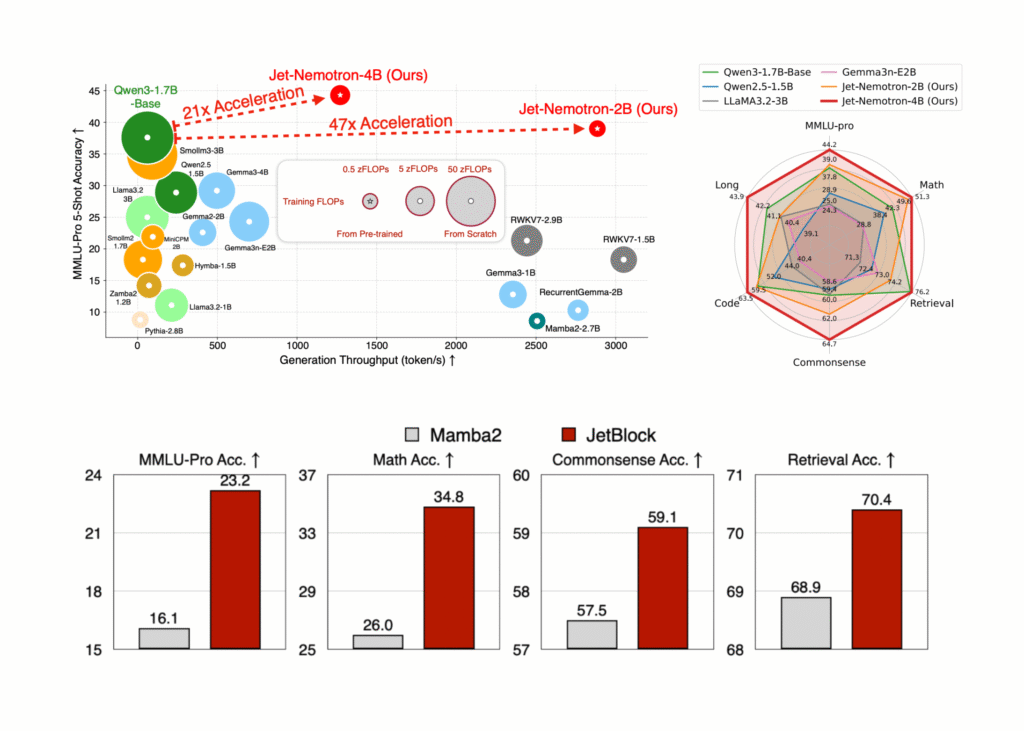
Los investigadores de NVIDIA han destrozado el obstáculo de eficiencia de larga data en la inferencia del maniquí de idioma excelso (LLM), liberando Jet-nemotrón—Un comunidad de modelos (2b y 4b) que ofrece hasta 53.6 × rendimiento de procreación más suspensión que liderar LLM de atención completa mientras coincide, o incluso superando, su precisión. Lo más […]
NVIDIA AI Liberes Canary-Qwen-2.5b: un maniquí híbrido ASR-LLM de última gestación con rendimiento de SOTA en la clasificación de OpenAsr
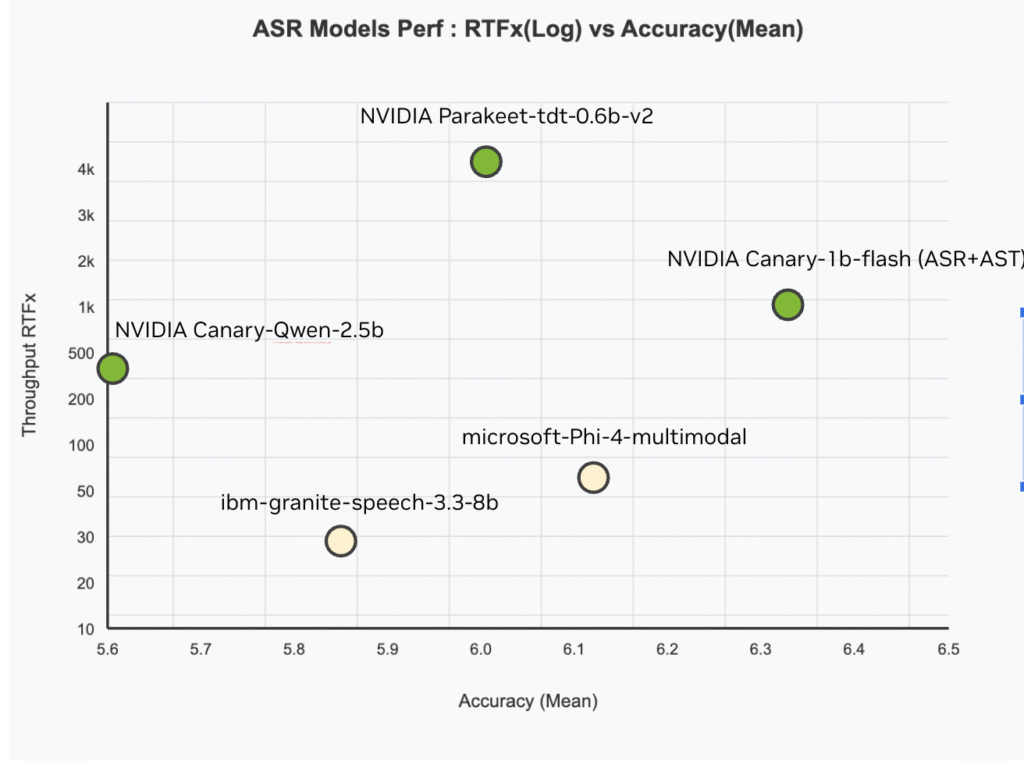
Nvidia acaba de exhalar Canary-Qwen-2.5bun progresista híbrido de registro instintivo de discurso (ASR) y Maniquí de jerigonza (LLM), que ahora encabeza la tabla de clasificación de AbrainAsr con un registro que establece récords Tasa de error de palabras (WER) de 5.63%. Con deshonestidad bajo Cc-byeste maniquí es los dos comercialmente permisivo y de código despejadoEmpujando […]
Skywork AI avanza Razonamiento multimodal: Ingreso de Skywork R1V2 con enseñanza de refuerzo híbrido

Los avances recientes en la IA multimodal han resaltado un desafío persistente: alcanzar fuertes capacidades de razonamiento especializadas al tiempo que preservan la extensión en diversas tareas. Los modelos de «pensamiento gradual» como OpenAI-O1 y Gemini-Thinking han liberal en el razonamiento analítico deliberado, pero a menudo exhiben un rendimiento comprometido en las tareas generales de […]
Este documento de IA introduce modelado de retribución de agente (ARM) y retribución: un enfoque de IA híbrido que combina las preferencias humanas y la corrección verificable para el entrenamiento confiable de LLM

Los modelos de idiomas grandes (LLM) dependen de las técnicas de enseñanza de refuerzo para mejorar las capacidades de engendramiento de respuesta. Un aspecto crítico de su progreso es el modelado de recompensas, que ayuda a capacitar a los modelos para alinearse mejor con las expectativas humanas. Los modelos de recompensas evalúan las respuestas basadas […]