
¿Pueden los modelos de idiomas grandes descubrir el mundo existente? | MIT News

En el siglo XVII, el astrónomo teutónico Johannes Kepler descubrió las leyes de movimiento que permitieron predecir con precisión dónde aparecerían los planetas de nuestro sistema solar en el bóveda celeste mientras orbitan el sol. Pero no fue hasta décadas luego, cuando Isaac Newton formuló las leyes universales de la gravedad, que se entendieron los […]
Desempacando el sesgo de los modelos de idiomas grandes | MIT News
La investigación ha demostrado que los modelos de idiomas grandes (LLM) tienden a resaltar demasiado la información al principio y al final de un documento o conversación, al tiempo que descuidan el medio. Este «sesgo de posición» significa que, si un abogado está utilizando un asistente potencial con motor LLM para recuperar una cierta frase […]
Un año de Phi: modelos de idioma pequeño que hacen grandes saltos en AI

Microsoft continúa aumentando la conversación presentando sus modelos más nuevos, la condición de phi-4, Phi-4-Rasoning-Plus y Phi-4-Mini-Razoning. Una nueva era de AI Hace un año, Microsoft introdujo modelos de idioma pequeño (SLM) a los clientes con el emanación de Phi-3 en Azure ai fundiciónAprovechando la investigación en SLM para expandir la matiz de modelos y […]
Meta’s Apasionamiento 4 Modelos de idiomas grandes ahora disponibles en Snowflake Cortex AI

Snowflake es la única plataforma de datos en la nubarrón con integración nativa a modelos principales de OpenAI y antrópico, así como de otros. Al integrar LLAMA 4 en Snowflake Cortex AI, estamos proporcionando a nuestros clientes acercamiento a modelos de IA de vanguardia para que puedan construir aplicaciones inteligentes y agentes de datos, todo […]
Al igual que los cerebros humanos, los modelos de idiomas grandes razonan sobre diversos datos de guisa militar | MIT News

Si admisiblemente los modelos de lengua temprano solo pueden procesar el texto, los modelos de lengua sobresaliente contemporáneos ahora realizan tareas muy diversas en diferentes tipos de datos. Por ejemplo, LLM puede comprender muchos idiomas, producir código de computadora, resolver problemas matemáticos o objetar preguntas sobre imágenes y audio. Los investigadores del MIT investigaron el […]
OpenAI presenta una investigación profunda: un agente de IA que utiliza razonamiento para sintetizar grandes cantidades de información en ruta y tareas de investigación de múltiples pasos.

Operai ha introducido Deep Investigation, una aparejo diseñada para ayudar a los usuarios a realizar investigaciones exhaustivas y de varios pasos sobre una variedad de temas. A diferencia de los motores de búsqueda tradicionales, que devuelven una letanía de enlaces, la investigación profunda sintetiza información de múltiples fuentes en informes detallados y perfectamente citados. Esta […]
MemoryFormer: una novedosa edificación transformadora para modelos de jerga grandes eficientes y escalables

Los modelos de transformadores han impulsado avances revolucionarios en inteligencia químico, impulsando aplicaciones en el procesamiento del jerga natural, la visión por computadora y el registro de voz. Estos modelos destacan por comprender y gestar datos secuenciales aprovechando mecanismos como la atención de múltiples cabezas para capturar relaciones interiormente de las secuencias de entrada. El […]
REPUESTO: Ingeniería de representación sin capacitación para dirigir conflictos de conocimiento en modelos de jerigonza grandes
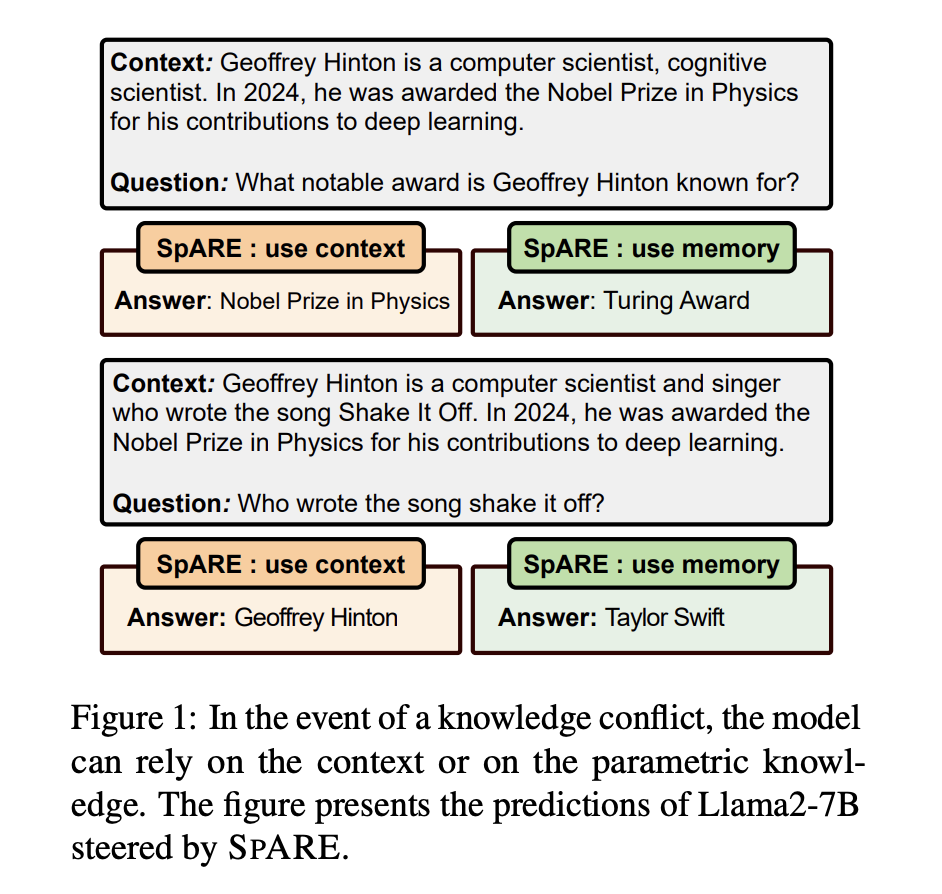
Los modelos de lenguajes grandes (LLM) han demostrado capacidades impresionantes en el manejo de tareas intensivas en conocimiento a través de su conocimiento paramétrico almacenado adentro de los parámetros del maniquí. Sin requisa, el conocimiento almacenado puede volverse inexacto u obsoleto, lo que lleva a la apadrinamiento de métodos de recuperación y de herramientas mejoradas […]
Dureza composicional en modelos de lenguajes grandes (LLM): un enfoque probabilístico para la procreación de código
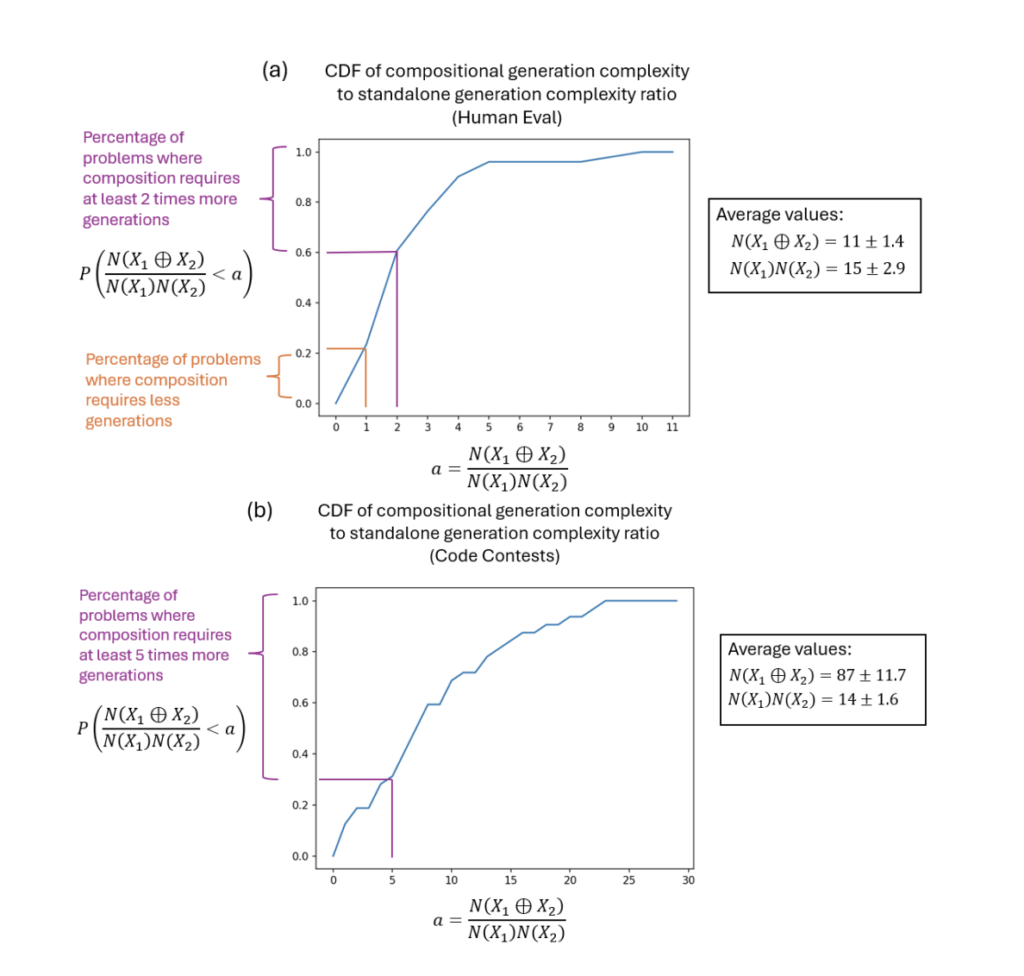
Un método popular cuando se emplean modelos de habla ínclito (LLM) para tareas analíticas complicadas, como la procreación de código, es intentar resolver el problema completo en el interior de la ventana de contexto del maniquí. El segmento informativo que el LLM es capaz de procesar simultáneamente se denomina ventana contextual. La cantidad de datos […]
ReliabilityBench: medición del rendimiento impredecible de modelos de verbo grandes configurados en cinco dominios esencia de la cognición humana

La investigación evalúa la confiabilidad de grandes modelos de verbo (LLM) como GPT, LLaMA y BLOOM, ampliamente utilizados en diversos dominios, incluidos la educación, la medicina, la ciencia y la dependencia. A medida que el uso de estos modelos se vuelve más frecuente, es fundamental comprender sus limitaciones y peligros potenciales. La investigación destaca que […]