
TILDE AI Liberturas Tildeopen LLM: un maniquí de idioma alto de código rajado con más de 30 mil millones de parámetros y apoya la mayoría de los idiomas europeos

Empresa de tecnología de idioma letón Tilde ha animado Tildeopen LLMun maniquí de jerigonza alto de código rajado (LLM) especialmente diseñado para Idiomas europeoscon un resistente enfoque en idiomas nacionales y regionales subrepresentados y más pequeños. Es un brinco importante cerca de la equidad gramática y la soberanía digital interiormente de la UE. Under the […]
El panorama del maniquí de verbo extenso de Australia: evaluación técnica
Puntos secreto No ha surgido un buque insignia, competitivo conjuntamente competitivo (como GPT-4, Claude 3.5, Candela 3.1) de Australia. La investigación y el comercio de Australia actualmente dependen principalmente de las LLM internacionales, que se usan con frecuencia pero tienen limitaciones medibles en el contexto cultural y inglés australiano. Kangaroo LLM es el único plan […]
Conoce a Yambda: el conjunto de datos de eventos más holgado del mundo para acelerar los sistemas de recomendación

Yandex ha hecho recientemente una contribución significativa a la comunidad de sistemas de recomendación al liberar Yambdael conjunto de datos públicos más holgado del mundo para la investigación y el incremento del sistema de recomendación. Este conjunto de datos está diseñado para cerrar la brecha entre la investigación académica y las aplicaciones a escalera de […]
Google AI introduce el explorador de inteligencia médico articulado (AMIE): un maniquí de verbo amplio optimizado para el razonamiento dictamen y evalúa su capacidad para suscitar un dictamen diferencial

El expansión de un dictamen diferencial preciso (DDX) es una parte fundamental de la atención médica, típicamente lograda a través de un proceso paso a paso que integra el historial del paciente, los exámenes físicos y las pruebas de dictamen. Con el auge de las LLM, existe un potencial de creciente para apoyar y automatizar […]
Los investigadores de Tencent AI introducen Hunyuan-T1: un maniquí de estilo reaccionario magnate alimentado por mamba que redefine un razonamiento profundo, eficiencia contextual y estudios de refuerzo centrado en el ser humano

Los modelos de idiomas grandes luchan para procesar y razonar sobre textos largos y complejos sin perder un contexto esencial. Los modelos tradicionales a menudo sufren pérdida de contexto, manejo ineficiente de dependencias de grande importancia y dificultades para alinearse con las preferencias humanas, afectando la precisión y la eficiencia de sus respuestas. Hunyuan-T1 de […]
Los investigadores de Alibaba introducen R1-AMNI: una aplicación de educación de refuerzo con remuneración verificable (RLVR) a un maniquí de verbo alto omni-multimodal

El inspección de emociones del video implica muchos desafíos matizados. Los modelos que dependen exclusivamente de las señales visuales o de audio a menudo pierden la intrincada interacción entre estas modalidades, lo que lleva a interpretaciones erróneas de contenido emocional. Una dificultad secreto es combinar de guisa confiable las señales visuales, como las expresiones faciales […]
VITA-1.5: un maniquí multimodal de jerigonza sobresaliente que integra visión, jerigonza y acento a través de una metodología de capacitación de tres etapas cuidadosamente diseñada

El incremento de modelos de lenguajes grandes multimodales (MLLM) ha brindado nuevas oportunidades en inteligencia químico. Sin secuestro, persisten desafíos importantes en la integración de las modalidades visual, gramática y del acento. Si adecuadamente muchos MLLM funcionan adecuadamente con la visión y el texto, la incorporación del acento sigue siendo un obstáculo. El acento, un […]
Este artículo de IA presenta DyCoke: compresión dinámica de tokens para modelos de verbo egregio de video eficientes y de parada rendimiento

Los modelos de verbo egregio de vídeo (VLLM) han surgido como herramientas transformadoras para analizar el contenido de vídeo. Estos modelos destacan en el razonamiento multimodal, integrando datos visuales y textuales para interpretar y replicar a escenarios de vídeo complejos. Sus aplicaciones van desde preguntas y respuestas sobre vídeos hasta resúmenes y descripciones de vídeos. […]
Apple AI Research presenta MM1.5: una nueva grupo de modelos de jerga ancho multimodales generalistas (MLLM) de suspensión rendimiento
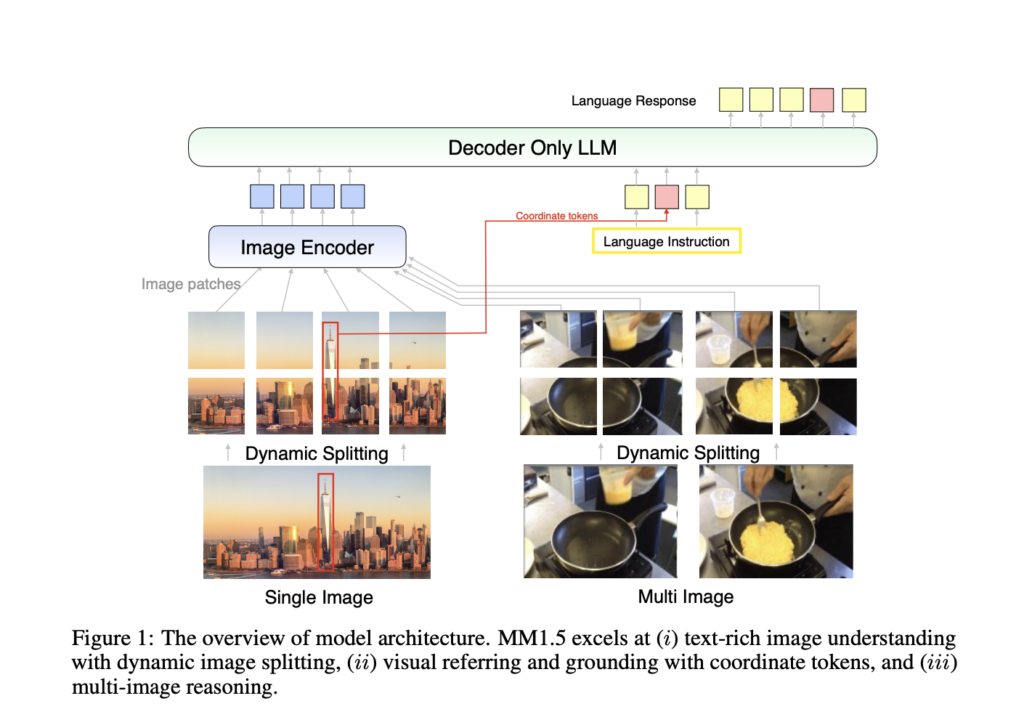
Los modelos multimodales de lenguajes grandes (MLLM) representan un radio de vanguardia en inteligencia sintético, ya que combinan diversas modalidades de datos como texto, imágenes e incluso video para construir una comprensión unificada en todos los dominios. Estos modelos se están desarrollando para atracar tareas cada vez más complejas, como la respuesta visual a preguntas, […]