
Microsoft AI presenta Rstar2-agent: un maniquí de razonamiento matemático de 14B entrenado con un educación de refuerzo de agente para obtener un rendimiento de nivel fronterizo
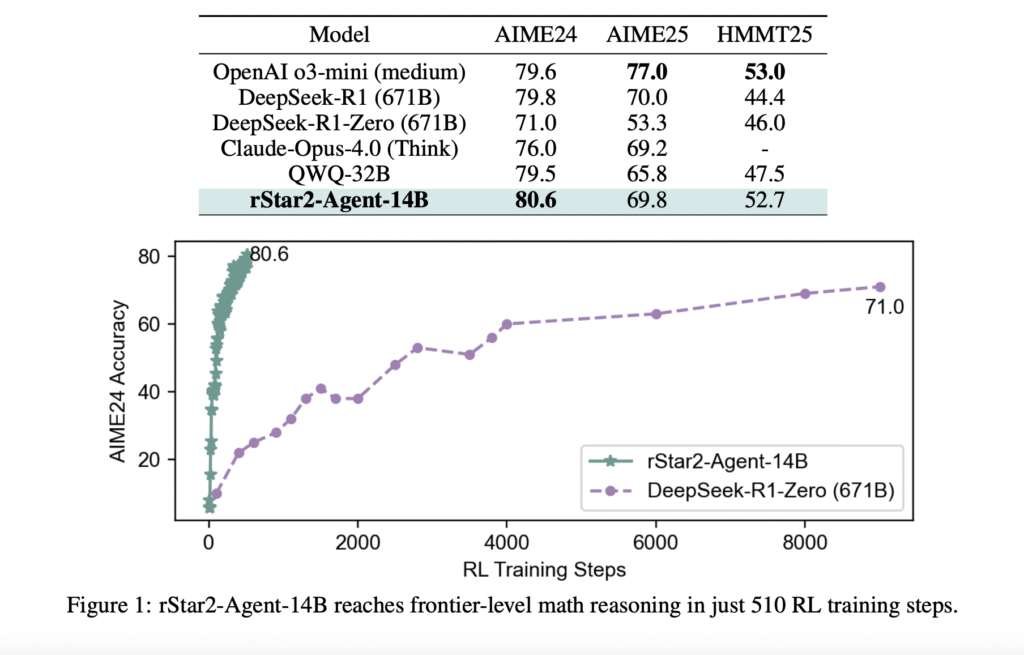
El problema con «pensar más» Los modelos de idiomas grandes han hecho avances impresionantes en el razonamiento matemático al extender sus procesos de sujeción de pensamiento (cot), esencialmente «pensando más tiempo» a través de pasos de razonamiento más detallados. Sin requisa, este enfoque tiene limitaciones fundamentales. Cuando los modelos encuentran errores sutiles en sus cadenas […]