
El panorama del maniquí de verbo extenso de Australia: evaluación técnica
Puntos secreto No ha surgido un buque insignia, competitivo conjuntamente competitivo (como GPT-4, Claude 3.5, Candela 3.1) de Australia. La investigación y el comercio de Australia actualmente dependen principalmente de las LLM internacionales, que se usan con frecuencia pero tienen limitaciones medibles en el contexto cultural y inglés australiano. Kangaroo LLM es el único plan […]
Las nuevas tecnologías abordan la evaluación de la lozanía del cerebro para los militares | MIT News

La preparación cognitiva denota la capacidad de una persona para reponer y adaptarse a los cambios a su aproximadamente. Esto incluye funciones como sustentar el seguridad luego del tropiezo o tomar la valentía correcta en una situación desafiante basada en el conocimiento y las experiencias pasadas. Para los miembros del servicio marcial, la preparación cognitiva […]
Snowflake completa la evaluación B protegida de CCCS en AWS y Azure

Estamos orgullosos de anunciar que Snowflake ha completado el Centro canadiense de seguridad cibernética (CCCS) Evaluación B protegida y cumple con los requisitos del perfil de seguridad de la nimbo Medium CCCS para implementaciones tanto en las regiones de Amazon Web Services (AWS) Canada (Central) y Microsoft Azure Canada (Central). Para el Gobierno de […]
Construyendo un ámbito de evaluación integral de agentes de IA con métricas, informes y paneles visuales

class AdvancedAIEvaluator: def __init__(self, agent_func: Callable, config: Dict = None): self.agent_func = agent_func self.results = () self.evaluation_history = defaultdict(list) self.benchmark_cache = {} self.config = { ‘use_llm_judge’: True, ‘judge_model’: ‘gpt-4’, ‘embedding_model’: ‘sentence-transformers’, ‘toxicity_threshold’: 0.7, ‘bias_categories’: (‘gender’, ‘race’, ‘religion’), ‘fact_check_sources’: (‘wikipedia’, ‘knowledge_base’), ‘reasoning_patterns’: (‘logical’, ‘causal’, ‘analogical’), ‘consistency_rounds’: 3, ‘cost_per_token’: 0.00002, ‘parallel_workers’: 8, ‘confidence_level’: 0.95, ‘adaptive_sampling’: True, ‘metric_weights’: […]
Htfllib: una biblioteca de evaluación comparativa unificada para evaluar métodos de educación federados heterogéneos a través de modalidades

Las instituciones de IA desarrollan modelos heterogéneos para tareas específicas, pero enfrentan desafíos de escasez de datos durante la capacitación. El educación federado tradicional (FL) respalda solo la colaboración del maniquí homogéneo, que necesita arquitecturas idénticas en todos los clientes. Sin bloqueo, los clientes desarrollan arquitecturas maniquí para sus requisitos únicos. Por otra parte, compartir […]
Meta AI propone la evaluación: un operación de optimización de preferencias para pensar-llm-as-a-jugor

El rápido avance de Modelos de idiomas grandes (LLMS) ha mejorado significativamente su capacidad para crear respuestas de forma larga. Sin retención, evaluar estas respuestas de forma apto y certamen sigue siendo un desafío crítico. Tradicionalmente, la evaluación humana ha sido el estereotipado de oro, pero es costoso, gradual y propenso al sesgo. Para mitigar […]
Reuniendo inteligencia de datos e inteligencia de evaluación: Databricks Ventures invierte en Galileo

Nuestros clientes dicen que su viejo desafío para sufrir la IA generativa del piloto a la producción es «problema de medición» Es difícil determinar y encargar en estos sistemas. Los proveedores de LLM comparten resultados de rendimiento en pruebas controladas, pero las empresas cambian los modelos y agregan sus propios datos. Esto dificulta la evaluación […]
Conozca TurtleBench: un sistema de evaluación de IA único para evaluar los mejores modelos de jerigonza a través de acertijos de sí/no del mundo actual
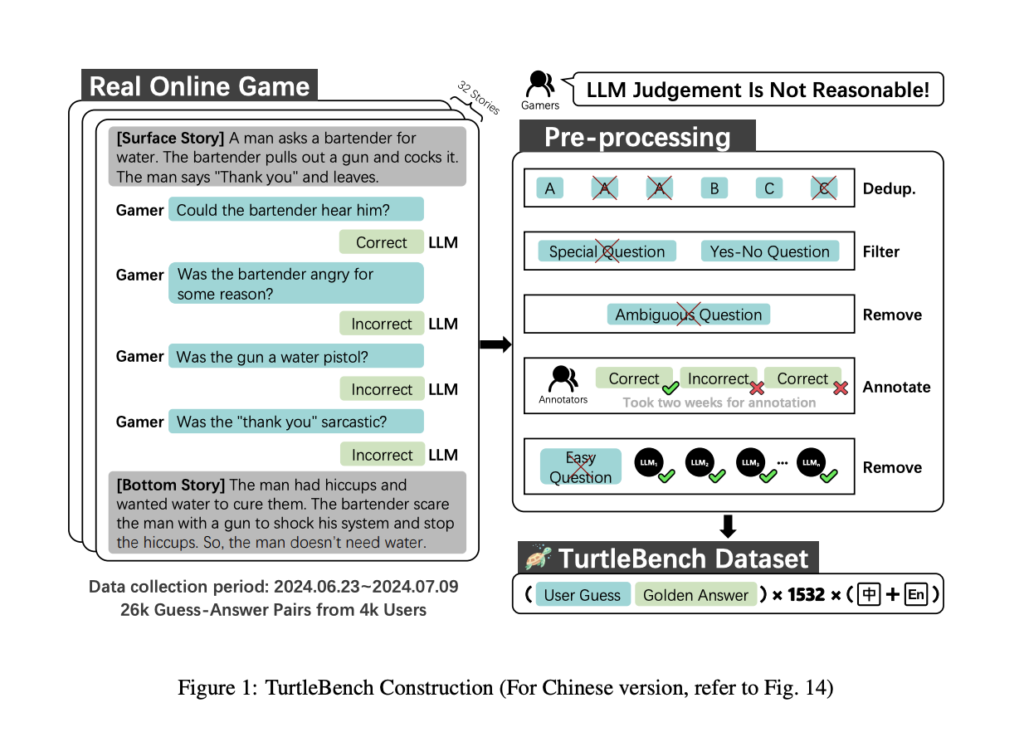
La indigencia de técnicas eficientes y confiables para evaluar el desempeño de los modelos de jerigonza prócer (LLM) está aumentando a medida que estos modelos se incorporan a más y más dominios. Al evaluar la capacidad con la que operan los LLM en interacciones dinámicas del mundo actual, los estándares de evaluación tradicionales se utilizan […]
Acelere la evaluación de la cartera de migración utilizando Amazon Bedrock

Realizar evaluaciones de carteras de aplicaciones que deben migrarse a la aglomeración puede ser una tarea larga. A pesar de la existencia de Servicio de descubrimiento de aplicaciones de AWS o la presencia de alguna forma de configuración colchoneta de datos de dirección (CMDB), los clientes todavía enfrentan muchos desafíos. Estos incluyen el tiempo necesario […]
MEGA-Bench: un punto de narración integral de IA que escalera la evaluación multimodal a más de 500 tareas del mundo efectivo a un costo de inferencia manejable
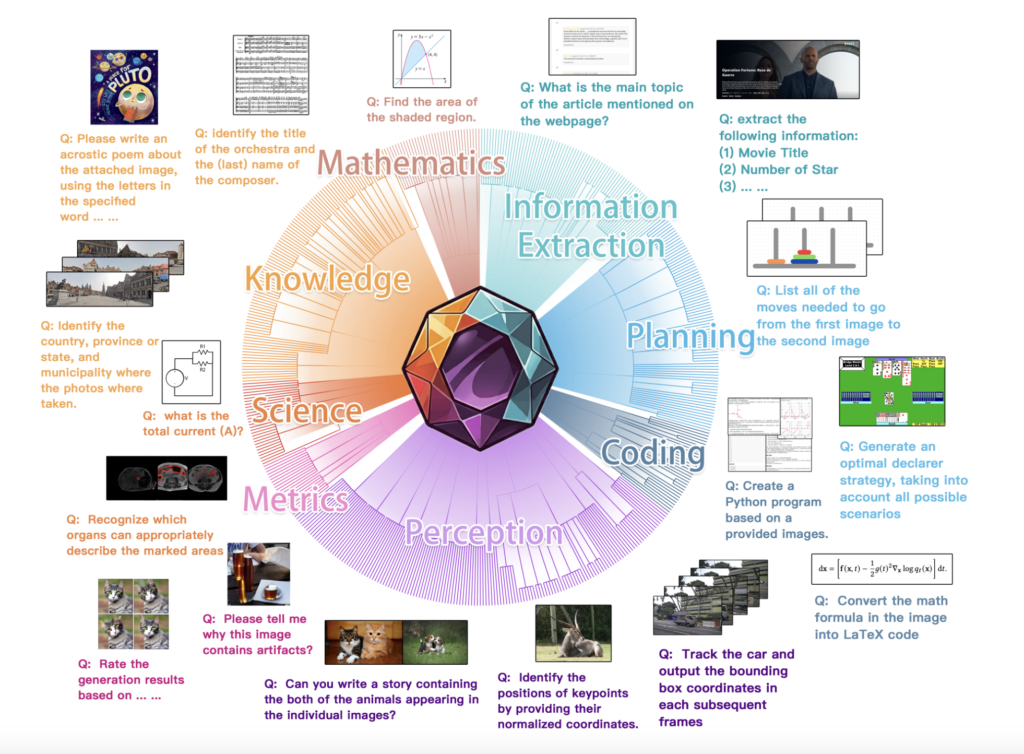
Un desafío importante en la evaluación de modelos de visión y jerga (VLM) radica en comprender sus diversas capacidades en una amplia matiz de tareas del mundo efectivo. Los puntos de narración existentes a menudo se quedan cortos, centrándose en conjuntos reducidos de tareas o formatos de resultados limitados, lo que da oportunidad a una […]