
De 100,000 a menos de 500 etiquetas: cómo Google AI corta datos de entrenamiento LLM por órdenes de magnitud
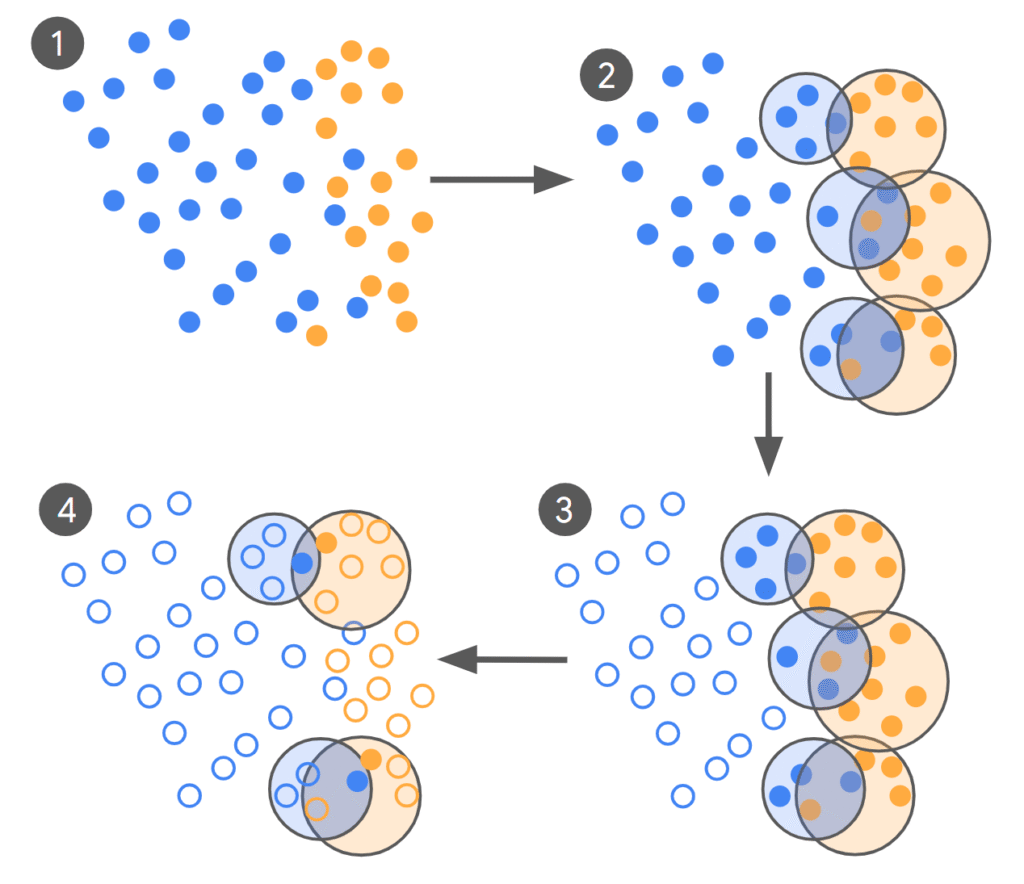
La investigación de Google ha presentado Un método renovador para ajustar los modelos de idiomas grandes (LLM) que reduce la cantidad de datos de capacitación requeridos en hasta 10,000xmientras mantiene o incluso mejoría la calidad del maniquí. Este enfoque se centra en el educación activo y el enfoque de los […]
Kyutai libera 2B de parámetros de transmisión de texto a voz TTS con latencia de 220 ms y 2.5m horas de entrenamiento

Kyutai, un laboratorio de investigación de IA destapado, ha publicado un maniquí renovador de transmisión de texto a voz (TTS) con ~ 2 mil millones de parámetros. Diseñado para la capacidad de respuesta en tiempo existente, este maniquí ofrece una engendramiento de audio de latencia exaltado disminución (220 milisegundos) mientras mantiene una adhesión fidelidad. Está […]
Entrenamiento de 10,000 modelos de detección de anomalías en mil millones de registros con predicciones explicables

El poder de la detección de anomalías en toda la industria Detección de anomalías es una técnica crucial para identificar patrones inusuales que podrían indicar posibles problemas u oportunidades. Algunos usos tempranos de la técnica incluyen ciberseguridad para detectar intrusiones y en finanzas para identificar fraude potencial, pero hoy sus aplicaciones ahora abarcan monitoreo de […]
Polaris-4B y Polaris-7b: Estudios de refuerzo posterior al entrenamiento para un razonamiento competente de matemáticas y método

La creciente menester de modelos de razonamiento escalable en inteligencia mecánica Los modelos de razonamiento reformista están en la frontera de la inteligencia de la máquina, especialmente en dominios como la resolución de problemas matemáticos y el razonamiento simbólico. Estos modelos están diseñados para realizar cálculos de varios pasos y deducciones lógicas, a menudo generando […]
Nuevo método salvaguardan eficientemente datos de entrenamiento de IA confidencial | MIT News

La privacidad de los datos viene con un costo. Existen técnicas de seguridad que protegen los datos confidenciales del beneficiario, como las direcciones de los clientes, de los atacantes que pueden intentar extraerlos de los modelos de IA, pero a menudo hacen que esos modelos sean menos precisos. Los investigadores del MIT desarrollaron recientemente un […]
Tomar las «ruedas de entrenamiento» de la energía limpia | MIT News

Las fuentes de energía renovables han conocido niveles de inversión sin precedentes en los últimos primaveras. Pero con la incertidumbre política que nubla el futuro de los subsidios para la energía verde, estas tecnologías deben comenzar a competir con los combustibles fósiles en igualdad de condiciones, dijeron los participantes en la Conferencia de Energía del […]
Este documento de IA introduce modelado de retribución de agente (ARM) y retribución: un enfoque de IA híbrido que combina las preferencias humanas y la corrección verificable para el entrenamiento confiable de LLM

Los modelos de idiomas grandes (LLM) dependen de las técnicas de enseñanza de refuerzo para mejorar las capacidades de engendramiento de respuesta. Un aspecto crítico de su progreso es el modelado de recompensas, que ayuda a capacitar a los modelos para alinearse mejor con las expectativas humanas. Los modelos de recompensas evalúan las respuestas basadas […]
La delantera de entrenamiento del copo de cocaína: poderoso ROI de educación de copos de cocaína

Si desea amplificar combustible de cohetes a su estructura, invierta en educación y capacitación de los empleados. Si admisiblemente puede no ser la primera logística que viene a la mente, es una de las formas más efectivas de impulsar beneficios comerciales generalizados, desde una decano eficiencia hasta una decano satisfacción de los empleados, y merece […]
Tutorial para ajustar Mistral 7B con Qlora usando Axolotl para un entrenamiento efectivo de LLM

En este tutorial, demostramos el flujo de trabajo para ajustar Mistral 7b usando Qlora con Ajolotemostrando cómo llevar la batuta bienes de GPU limitados mientras personaliza el maniquí para nuevas tareas. Instalaremos Axolotl, crearemos un pequeño conjunto de datos de ejemplo, configuraremos los hiperparámetros específicos de Lora, ejecutaremos el proceso de ajuste fino y probará […]
El nuevo enfoque de entrenamiento podría ayudar a los agentes de IA a desempeñarse mejor en condiciones inciertas | MIT News

Un autómata doméstico capacitado para realizar tareas domésticas en una factoría puede dejar de fregar efectivamente el fregadero o sacar la basura cuando se despliega en la cocina de un heredero, ya que este nuevo entorno difiere de su espacio de entrenamiento. Para evitar esto, los ingenieros a menudo intentan igualar el entorno de entrenamiento […]