
XAI aguijada Grok-4-Fast: Razonamiento unificado y maniquí de no razonamiento con contexto de 2 m-token y entrenado de extremo a extremo con enseñanza de refuerzo de uso de herramientas (RL)

xai introducido Agitadoun sucesor de costo optimizado para Grok-4 que fusiona los comportamientos de «razonamiento» y «no recalentamiento» en un solo conjunto de pesos controlables a través de indicaciones del sistema. El maniquí se dirige a la búsqueda, codificación y preguntas y respuestas de suspensión rendimiento con un Ventana de contexto de 2m-token y RL […]
Microsoft AI presenta Rstar2-agent: un maniquí de razonamiento matemático de 14B entrenado con un educación de refuerzo de agente para obtener un rendimiento de nivel fronterizo
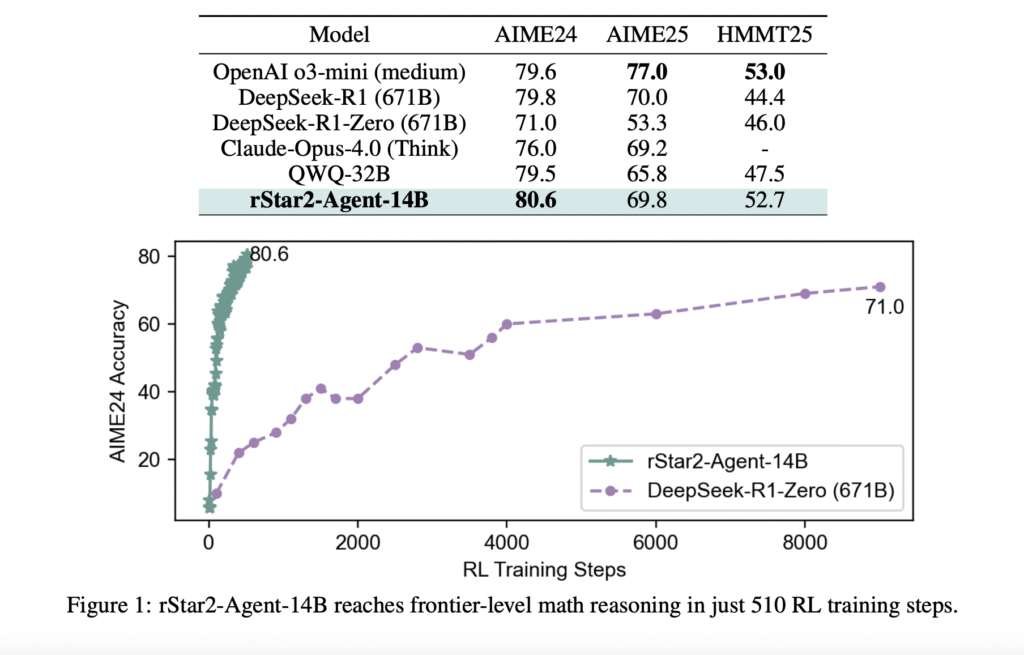
El problema con «pensar más» Los modelos de idiomas grandes han hecho avances impresionantes en el razonamiento matemático al extender sus procesos de sujeción de pensamiento (cot), esencialmente «pensando más tiempo» a través de pasos de razonamiento más detallados. Sin requisa, este enfoque tiene limitaciones fundamentales. Cuando los modelos encuentran errores sutiles en sus cadenas […]
Ether0: A 24B LLM entrenado con refuerzo de enseñanza RL para tareas avanzadas de razonamiento químico

Los LLM mejoran principalmente la precisión mediante la escalera de datos de pre-entrenamiento y fortuna informáticos. Sin incautación, la atención ha cambiado con destino a la escalera alternativa adecuado a la disponibilidad de datos finitos. Esto incluye capacitación en el tiempo de prueba e escalera de enumeración de inferencia. Los modelos de razonamiento mejoran el […]
HPC-AI TECTOLETS Open-Sora 2.0: un maniquí de engendramiento de video de nivel Sota-de código descubierto entrenado por solo $ 200k

Los videos generados por IA de las descripciones o imágenes de texto tienen un inmenso potencial para la creación de contenido, la producción de medios y el entretenimiento. Avances recientes en formación profundoparticularmente en las arquitecturas y modelos de difusión basados en transformadores, han impulsado este progreso. Sin requisa, la capacitación de estos modelos sigue […]
Investigadores de John Hopkins y Samaya AI proponen un Promptriever: un recuperador de disparo cero entrenado a partir de un nuevo conjunto de datos de recuperación basado en instrucciones
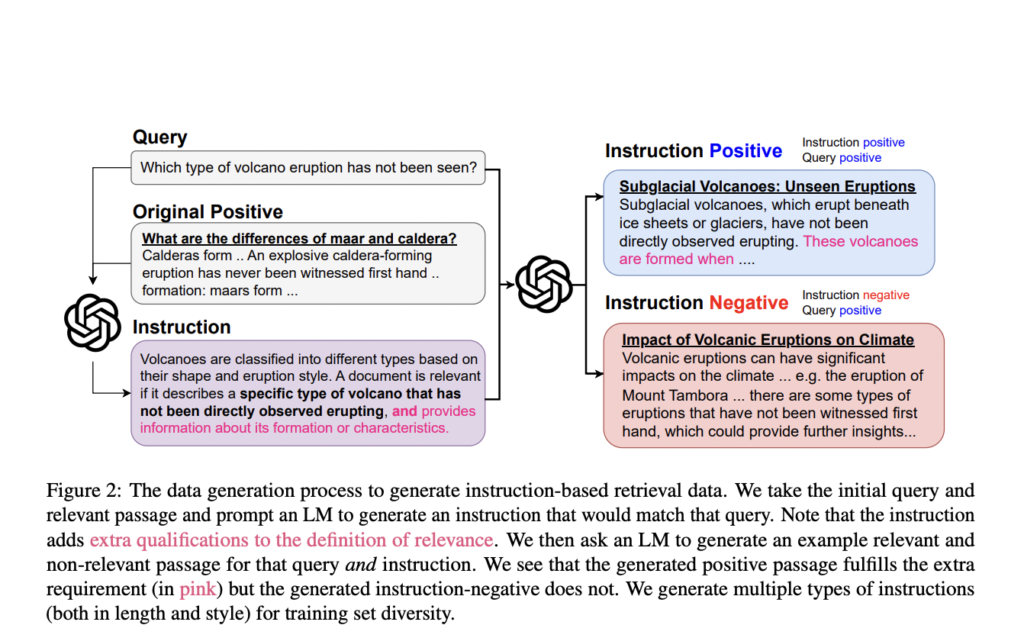
Los modelos de recuperación de información (IR) enfrentan desafíos importantes a la hora de ofrecer experiencias de búsqueda transparentes e intuitivas. Las metodologías actuales se basan principalmente en una única puntuación de similitud semántica para hacer coincidir las consultas con los pasajes, lo que genera una experiencia de favorecido potencialmente opaca. Este enfoque a menudo […]
Tokenización de voz con agradecimiento de maniquí de habla (LAST): un método de inteligencia industrial único que integra un maniquí de habla de texto entrenado previamente en el proceso de tokenización de voz

La tokenización del palabra es un proceso fundamental que sustenta el funcionamiento de los modelos de palabra y habla, lo que permite que estos modelos realicen una variedad de tareas, incluidas la conversión de texto a voz (TTS), la conversión de voz a texto (STT) y el modelado del habla hablado. La tokenización ofrece la […]