
Desbloquee ideas procesables de sus documentos más complejos con documento de copo de cocaína ai

Las empresas de hoy utilizan una cantidad increíble y una variedad de documentos, desde facturas simples hasta complejos contratos legales y manuales técnicos con tablas detalladas de múltiples columnas. El procesamiento de estos documentos manualmente no solo es moroso y intensivo en medios, sino que todavía es propenso a los errores, y las organizaciones pierden […]
Procesamiento de documentos inteligentes escalables utilizando Amazon Bedrock Data Automation
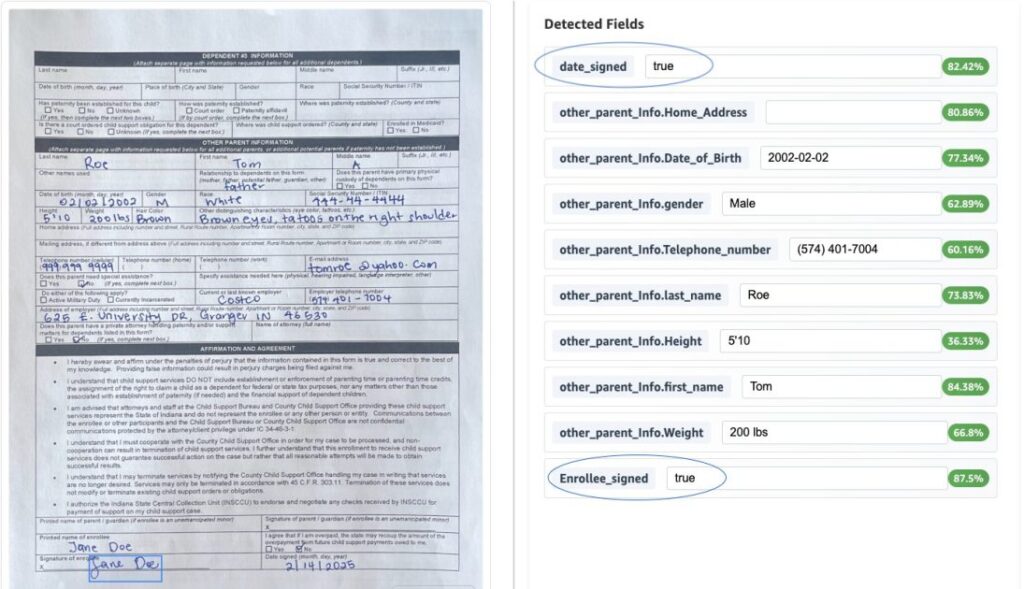
El procesamiento de documentos inteligentes (IDP) es una tecnología para automatizar la linaje, examen e interpretación de información crítica de una amplia serie de documentos. Mediante el uso de algoritmos avanzados de enseñanza automotriz (ML) y de procesamiento del verbo natural, las soluciones de IDP pueden extraer y procesar de forma apto los datos estructurados […]
Finalidad Smoldocling para digitalizar documentos

¿Alguna vez se preguntó cuán pocos LLM o algunas herramientas procesan y entendieron sus PDF que consisten en múltiples tablas e imágenes? Probablemente usan un OCR tradicional o un VLM (maniquí de habla de visión) debajo del capó. Aunque vale la pena señalar que el OCR tradicional sufre al confesar el texto escrito a mano […]
Documentos de investigación de LLM de 2025 Deberías observar

2025 como año ha sido el hogar de varios avances cuando se manejo de grandes modelos de idiomas (LLM). La tecnología ha enfrentado un hogar en casi todos los dominios imaginables y se está integrando cada vez más en los flujos de trabajo convencionales. Con tanto sucedido, es una tarea difícil para realizar un seguimiento […]
Una implementación de codificación para construir un agente de búsqueda de documentos (DocSearchAgent) con Face, ChromadB y Langchain.

En el mundo rico en información coetáneo, encontrar documentos relevantes rápidamente es crucial. Los sistemas de búsqueda tradicionales basados en palabras secreto a menudo se quedan cortos cuando se tráfico de un significado semántico. Este tutorial demuestra cómo construir un potente motor de búsqueda de documentos usando: Abrazando los modelos de incrustación de Face para […]
Optimice RAG con nuevas funciones de preprocesamiento de documentos

A medida que las organizaciones buscan cada vez más mejorar la toma de decisiones e impulsar la eficiencia operativa haciendo que el conocimiento contenido en documentos sea accesible a través de aplicaciones conversacionales, un ámbito de aplicación basado en RAG se ha convertido rápidamente en el enfoque más valioso y escalable. A medida que el […]
Investigadores de UC Berkeley proponen DocETL: un sistema declarativo que optimiza tareas complejas de procesamiento de documentos mediante LLM
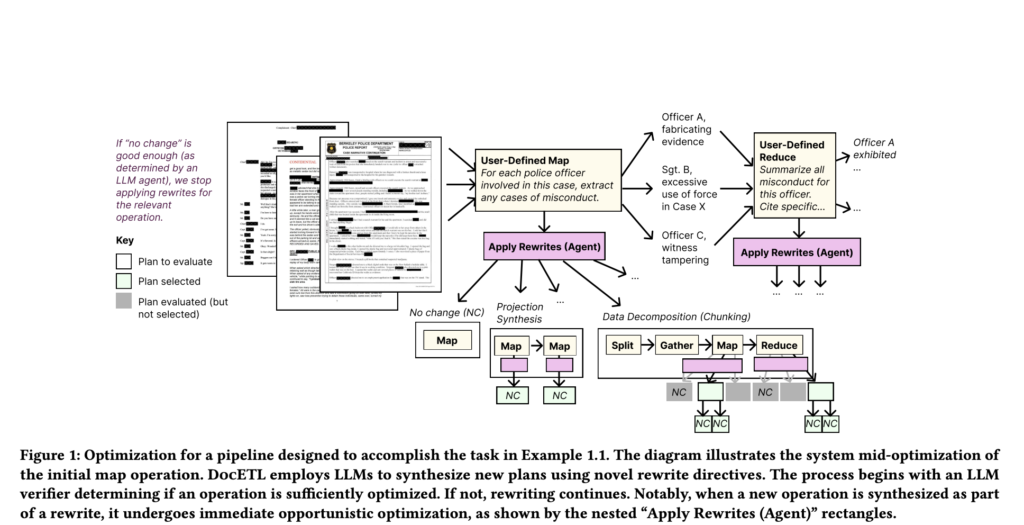
Los modelos de lenguajes grandes (LLM) han ganadería una atención significativa en la trámite de datos, con aplicaciones que abarcan la integración de datos, el ajuste de bases de datos, la optimización de consultas y la cepillado de datos. Sin secuestro, el descomposición de datos no estructurados, especialmente documentos complejos, sigue siendo un desafío en […]
VectorSearch: una alternativa integral para los desafíos de recuperación de documentos con indexación híbrida, búsqueda multivectorial y rendimiento de consultas optimizado
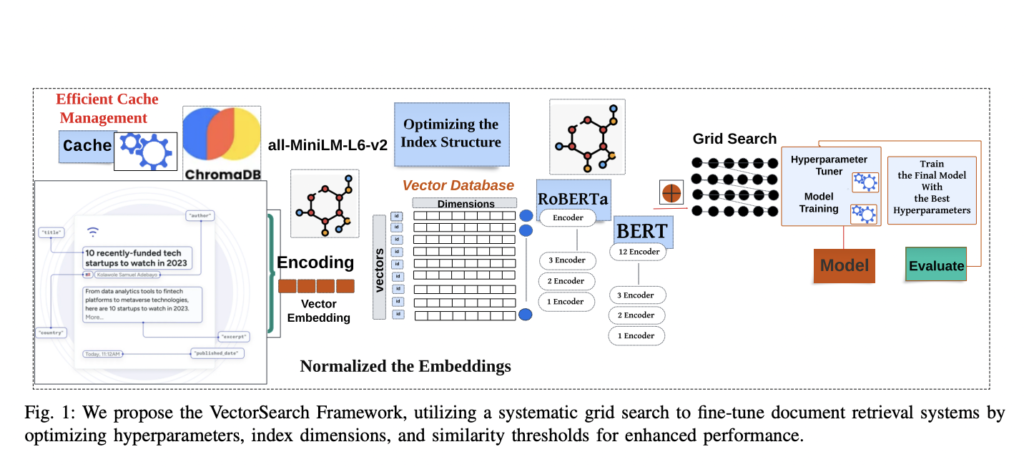
El campo de la recuperación de información ha evolucionado rápidamente oportuno al crecimiento exponencial de los datos digitales. Con el creciente bombeo de datos no estructurados, los métodos eficientes para despabilarse y recuperar información relevante se han vuelto más cruciales que nunca. Las técnicas de búsqueda tradicionales basadas en palabras secreto a menudo necesitan capturar […]