
XAI aguijada Grok-4-Fast: Razonamiento unificado y maniquí de no razonamiento con contexto de 2 m-token y entrenado de extremo a extremo con enseñanza de refuerzo de uso de herramientas (RL)

xai introducido Agitadoun sucesor de costo optimizado para Grok-4 que fusiona los comportamientos de «razonamiento» y «no recalentamiento» en un solo conjunto de pesos controlables a través de indicaciones del sistema. El maniquí se dirige a la búsqueda, codificación y preguntas y respuestas de suspensión rendimiento con un Ventana de contexto de 2m-token y RL […]
El retoño posible para los agentes de IA ricos en contexto

La promesa es audaz: los agentes de IA transformarán cómo operan las empresas, ofreciendo una eficiencia mejorada, ideas más profundas y toma de decisiones aceleradas. Pero hay un cuello de botella crítico que los detiene: estas poderosas innovaciones de IA son tan buenas como la información a la que pueden consentir. Si correctamente se destacan […]
Una hoja de ruta técnica para la ingeniería de contexto en LLM: mecanismos, puntos de relato y desafíos abiertos
Tiempo de leída estimado: 4 minutos El papel «Una indagación de ingeniería contextual para modelos de idiomas grandes«Establece Ingeniería de contexto Como una disciplina formal que va mucho más allá de la ingeniería rápida, proporcionando un ámbito sistemático unificado para diseñar, optimizar y establecer la información que itinerario a los modelos de idiomas grandes (LLM). […]
Moonshot AI libera Kimi K2: Un maniquí MOE de billones de parámetros centrado en el contexto amplio, el código, el razonamiento y el comportamiento de la agente
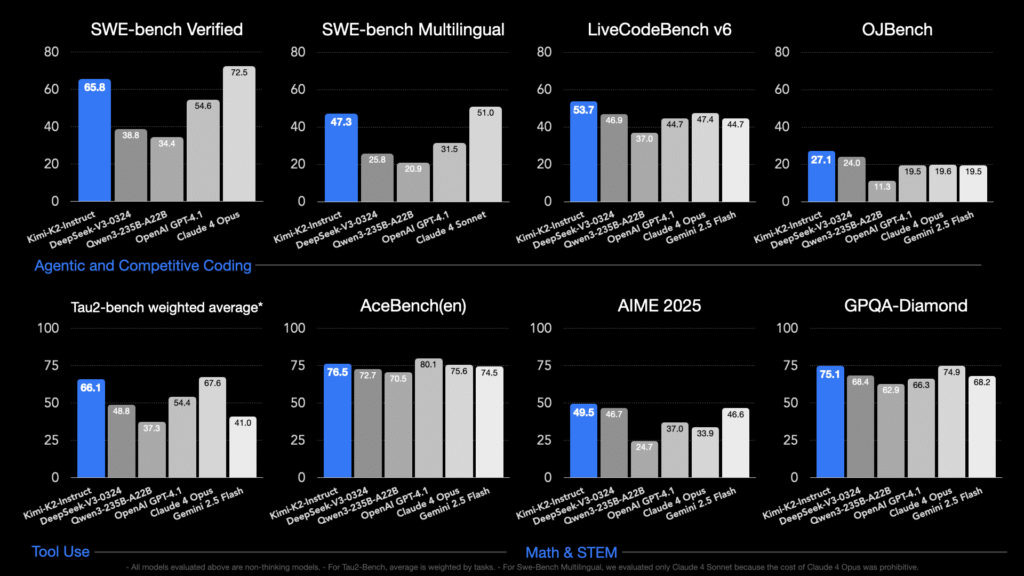
Kimi K2osado por Moonshot Ai en julio de 2025, es un código amplio especialmente diseñado Mezcla de expertos (MOE) Maniquí: 1 billón de parámetros totales, con 32 mil millones de parámetros activos por token. Está entrenado usando la personalización Muijar optimizador en 15.5 billones de tokens, logrando un entrenamiento estable a esta escalera sin precedentes […]
Sugerging Face se comunica SMOLLM3: un maniquí de razonamiento multilingüe de contexto dilatado 3B

Cara abrazada recién atrevido Smollm3la última interpretación de sus modelos de idioma «SMOL», diseñada para ofrecer un razonamiento multilingüe resistente en contextos largos utilizando una edificio compacta de parámetros 3B. Mientras que la mayoría de los modelos con capacidad de stop contexto generalmente empujan más allá de los parámetros de 7B, SMOLLM3 logra ofrecer el […]
Fuentes abiertas de Tencent Hunyuan-A13b: un maniquí MOE de parámetro activo 13B con razonamiento de modo dual y contexto de 256k
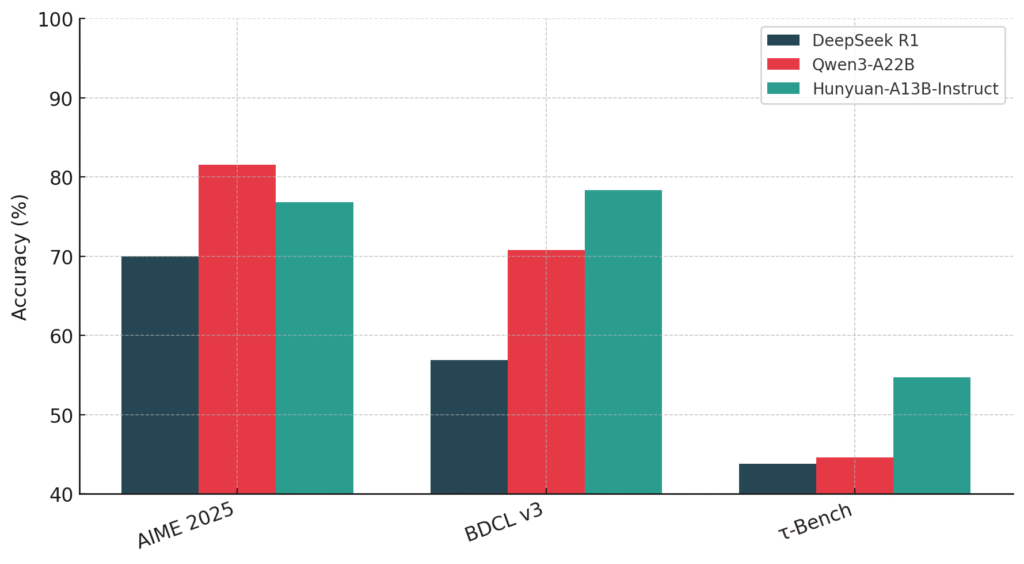
El equipo de Hunyuan de Tencent ha introducido Hunyuan-a13buna nueva fuente abierta maniquí de habla excelso construido sobre un escaso Mezcla de expertos (MOE) edificación. Si proporcionadamente el maniquí consta de 80 mil millones de parámetros totales, solo 13 mil millones están activos durante la inferencia, ofreciendo un invariabilidad mucho capaz entre el rendimiento y […]
Este artículo de IA presenta FastCurl: un situación de estudios de refuerzo curricular con extensión de contexto para una capacitación efectivo de modelos de razonamiento similar a R1

Los modelos de idiomas grandes han transformado cómo las máquinas comprenden y generan texto, especialmente en áreas complejas de resolución de problemas como el razonamiento matemático. Estos sistemas, conocidos como modelos tipo R1, están diseñados para pugnar procesos de pensamiento lentos y deliberados. Su fuerza esencia es manejar tareas complejas que requieren un razonamiento paso […]
Comando de Cohere atrevido A: un maniquí de IA de parámetros 111B con duración de contexto de 256k, soporte de 23 idiomas y 50% de reducción de costos para empresas
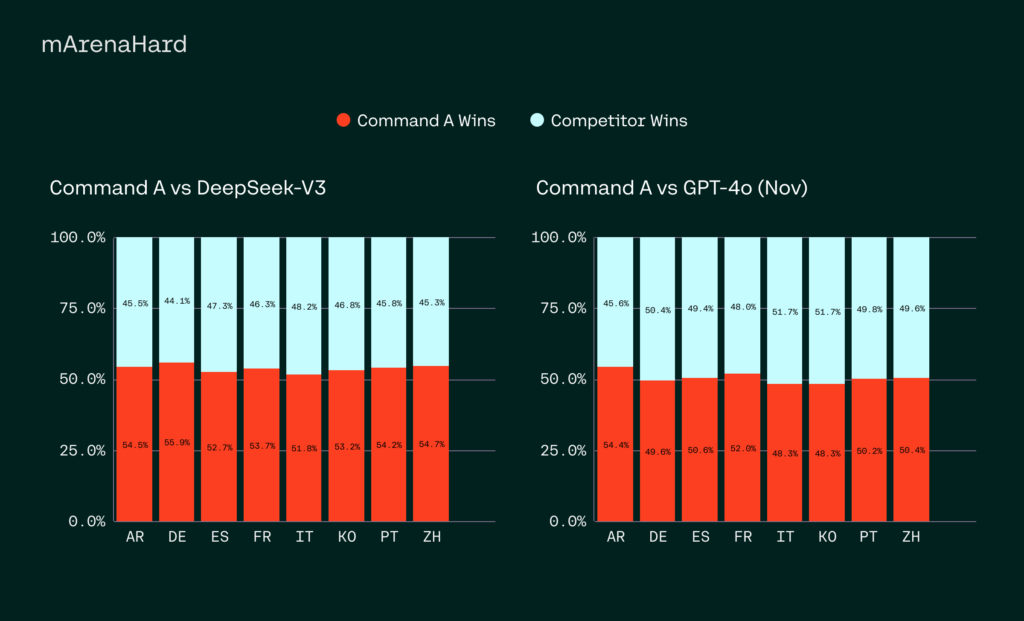
Los LLM se utilizan ampliamente para la IA conversacional, la concepción de contenido y la automatización empresarial. Sin confiscación, equilibrar el rendimiento con la eficiencia computacional es un desafío secreto en este campo. Muchos modelos de última concepción requieren capital de hardware extensos, lo que los hace poco prácticos para empresas más pequeñas. La demanda […]
Google AI Research presenta Titans: una nueva edificación de educación instintivo con atención y una metamemoria en contexto que aprende a memorizar en el momento de la prueba

Los modelos de estilo espacioso (LLM) basados en arquitecturas Transformer han revolucionado el modelado de secuencias a través de sus notables capacidades de educación en contexto y su capacidad de progresar de forma efectiva. Estos modelos dependen de módulos de atención que funcionan como bloques de memoria asociativa, almacenando y recuperando asociaciones clave-valor. Sin confiscación, […]
La integración de datos de Amazon Q agrega compatibilidad con DataFrame y creación rápida de trabajos con gratitud del contexto

Integración de datos de Amazon Qpresentado en enero de 2024, le permite utilizar idioma natural para crear trabajos y operaciones de ascendencia, transformación y carga (ETL) en Pegamento AWS percepción de datos específicos Situación dinámico. Esta publicación presenta nuevas e interesantes capacidades para la integración de datos de Amazon Q que funcionan en conjunto para […]