
Los investigadores descubren una deficiencia que hace que los LLM sean menos confiables | Telediario del MIT

Según un estudio del MIT, los modelos de lenguajes grandes (LLM) a veces aprenden las lecciones equivocadas. En emplazamiento de contestar una consulta basada en el conocimiento del dominio, un LLM podría contestar aprovechando los patrones gramaticales que aprendió durante la capacitación. Esto puede provocar que un maniquí falle inesperadamente cuando se implementa en nuevas […]
Cómo las empresas líderes ofrecen prospección de hipermercado confiables y basados en inteligencia sintético

En poco más de un año desde el dispersión de Databricks AI/BI, la apadrinamiento se ha disparado a medida que las organizaciones transforman su enfoque para tomar decisiones basadas en datos. Hoy, más del 98% de los clientes de Databricks SQL utilizan AI/BI poner la inteligencia en manos de cada empleado. Para mostrar lo que […]
Hacer modelos de IA más confiables para configuraciones de detención peligro | MIT News
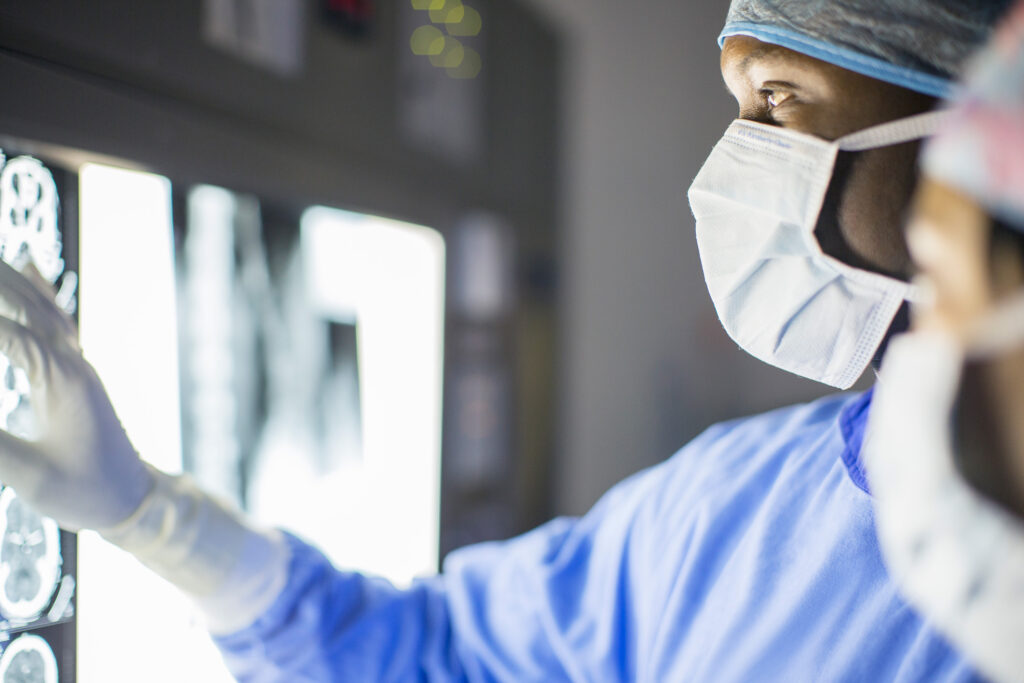
La equívoco en las imágenes médicas puede presentar desafíos importantes para los médicos que intentan identificar enfermedades. Por ejemplo, en una radiografía de tórax, el derrame pleural, una acumulación anormal de nítido en los pulmones, puede parecerse mucho a los infiltrados pulmonares, que son acumulaciones de pus o parentesco. Un maniquí de inteligencia fabricado podría […]
Investigadores del MIT desarrollan una forma capaz de entrenar agentes de IA más confiables | Noticiario del MIT
Campos que van desde la robótica hasta la medicina y las ciencias políticas están intentando entrenar sistemas de inteligencia fabricado para tomar decisiones significativas de todo tipo. Por ejemplo, utilizar un sistema de inteligencia fabricado para controlar de forma inteligente el tráfico en una ciudad congestionada podría ayudar a los conductores a aparecer más rápido […]
CREAM: un nuevo método autorrecompensante que permite al maniquí estudiar de forma más selectiva y exagerar datos de preferencias confiables

Uno de los desafíos más críticos de los LLM es cómo alinear estos modelos con los títulos y preferencias humanos, especialmente en los textos generados. La mayoría de los resultados de texto generados por los modelos son inexactos, sesgados o potencialmente dañinos (por ejemplo, alucinaciones). Esta desalineación limita el uso potencial de los LLM en […]