
Mejorar la comprensión de video con la automatización de datos de roca superiora de Amazon y la detección de objetos abiertos
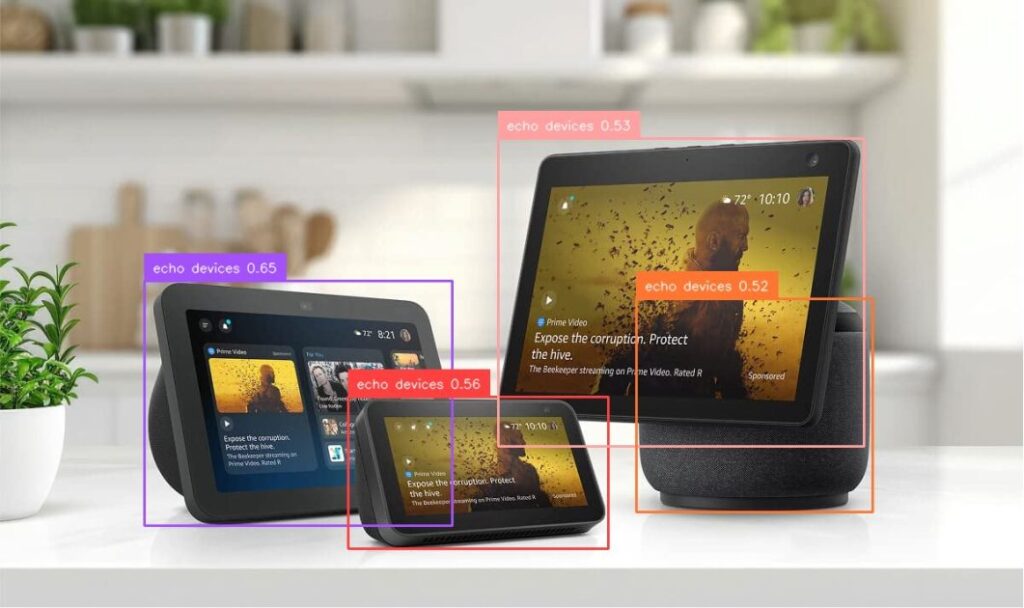
En el investigación de videos e imágenes del mundo actual, las empresas a menudo enfrentan el desafío de detectar objetos que no eran parte del conjunto de capacitación llamativo de un maniquí. Esto se vuelve especialmente difícil en entornos dinámicos donde los objetos nuevos, desconocidos o definidos por el agraciado aparecen con frecuencia. Por ejemplo, […]
Meta AI Lanzamientos V-JEPA 2: Modelos mundiales auto-supervisados de código hendido para la comprensión, la predicción y la planificación

Meta AI ha introducido V-Jepa 2, un maniquí de mundo hendido escalable diseñado para educarse de video a escalera de Internet y permitir una comprensión visual robusta, predicción estatal futura y planificación de disparos cero. Sobre la almohadilla de la cimentación predictiva de incrustación conjunta (JEPA), V-JEPA 2 demuestra cómo el estudios auto-supervisado del video […]
Los investigadores de Alibaba proponen Videollama 3: Un maniquí de almohadilla multimodal progresista para la comprensión de imágenes y videos

Avances en inteligencia multimodal Depende del procesamiento y la comprensión de imágenes y videos. Las imágenes pueden revelar escenas estáticas proporcionando información sobre detalles como objetos, texto y relaciones espaciales. Sin confiscación, esto tiene el costo de ser extremadamente desafiante. La comprensión de video implica el seguimiento de los cambios a lo amplio del tiempo, […]
Desarrollar una comprensión de cómo los conductores interactúan con las tecnologías vehiculares emergentes | Noticiario del MIT

A medida que evoluciona la conversación total sobre los vehículos asistidos y automatizados (AV), el Consorcio de Tecnología de Vehículos Innovador (AVT) del MIT continúa liderando investigaciones de vanguardia destinadas a comprender cómo los conductores interactúan con las tecnologías de vehículos emergentes. Desde su tiro en 2015, el Consorcio AVT, una colaboración total entre la […]
A pesar de su impresionante rendimiento, la IA generativa no tiene una comprensión coherente del mundo | Noticiario del MIT

Los grandes modelos de verbo pueden hacer cosas impresionantes, como escribir poesía o producir programas informáticos viables, aunque estos modelos están entrenados para predecir las palabras que siguen en un texto. Capacidades tan sorprendentes pueden hacer que parezca que los modelos están aprendiendo implícitamente algunas verdades generales sobre el mundo. Pero ese no es necesariamente […]
Los estudiantes de máster en Derecho desarrollan su propia comprensión de la sinceridad a medida que mejoran sus habilidades lingüísticas | Telediario del MIT

Si le pides a un maniquí de verbo ilustre (LLM) como GPT-4 que huela un campamento empapado por la borrasca, se negará cortésmente. Si le pides al mismo sistema que te describa ese olor, hablará con poesía sobre “un garbo cargado de anticipación” y “un olor que es fresco y terroso”, a pesar de no […]
Present-o: un modelo de IA unificado que unifica la comprensión y la generación multimodal utilizando un único transformador
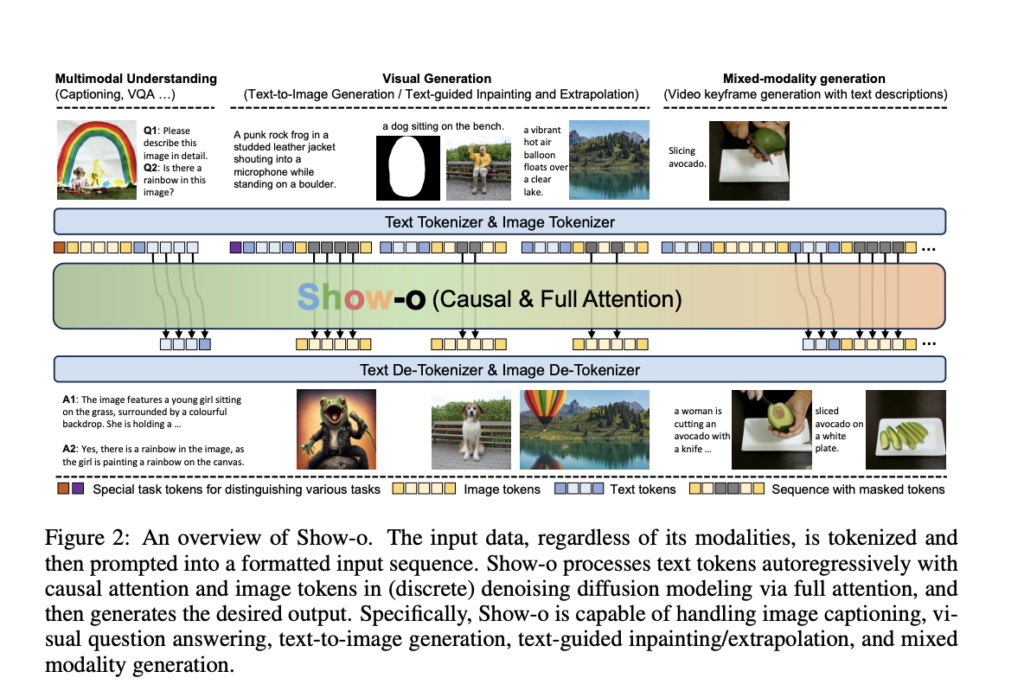
Este artículo presenta Present-o, un modelo de transformador unificado que integra capacidades de comprensión y generación multimodal dentro de una única arquitectura. A medida que avanza la inteligencia synthetic, ha habido un progreso significativo en la comprensión multimodal (por ejemplo, la respuesta a preguntas visuales) y la generación (por ejemplo, la síntesis de texto a […]