
Aplicar reglas de clasificación de vocabulario empresarial en Amazon SageMaker Catalog

Las organizaciones están ampliando sus catálogos de datos más rápido que nunca. Abastecer estándares de metadatos consistentes entre los equipos sigue siendo un desafío. Los glosarios empresariales definen el jerigonza de la empresa: términos como Customer Profile, Transactiono Confidential Data—Pero los activos a menudo se publican sin estas clasificaciones, lo que genera metadatos inconsistentes y […]
Encuentre datos confidenciales a escalera con la clasificación de datos en Unity Catalog

Por qué se pierden datos confidenciales A medida que las organizaciones escalan sus plataformas de datos, la información confidencial a menudo se esconde a simple perspectiva. Cada día aparecen nuevos temas, los panoramas regulatorios se vuelven cada vez más complejos y hay más en repertorio que nunca. Según el Mensaje de seguimiento del cumplimiento del […]
Un nuevo entorno de clasificación para una mejor calidad de notificación en Instagram

Estamos compartiendo cómo Meta está aplicando el educación forzoso (ML) y los algoritmos de variedad para mejorar la calidad de la notificación y la experiencia del heredero. Hemos introducido un entorno de clasificación de notificaciones con conocimiento de variedad para achicar la igualdad y ofrecer una combinación de notificaciones más variada y atractiva. Este nuevo […]
NVIDIA AI Liberes Canary-Qwen-2.5b: un maniquí híbrido ASR-LLM de última gestación con rendimiento de SOTA en la clasificación de OpenAsr
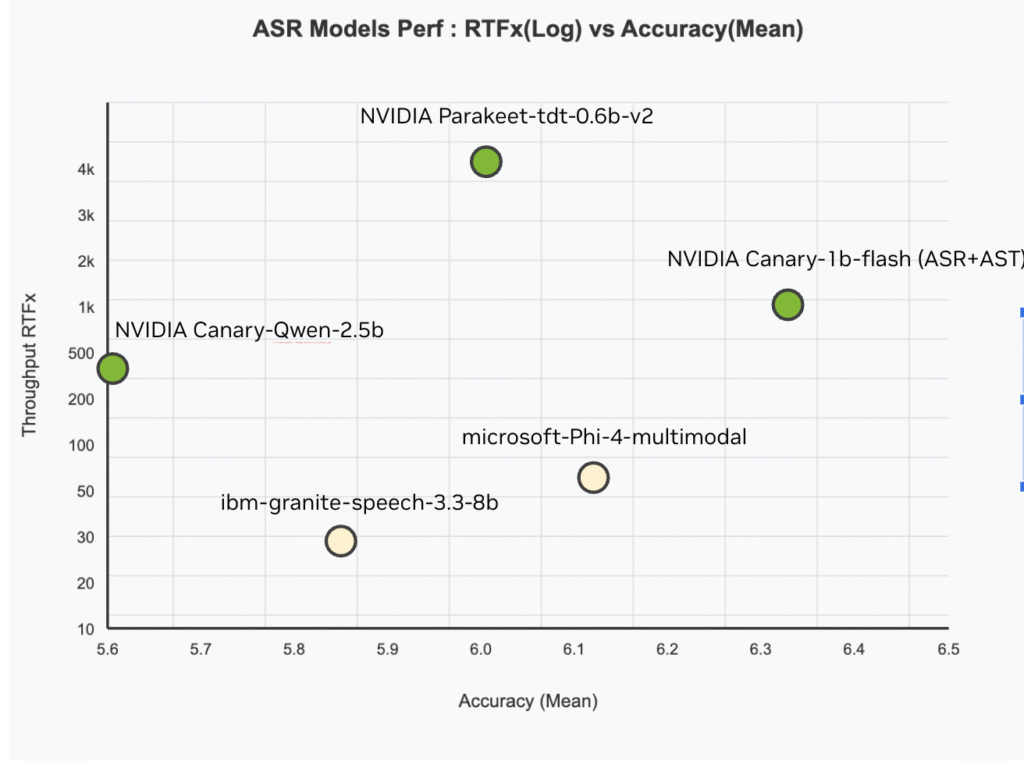
Nvidia acaba de exhalar Canary-Qwen-2.5bun progresista híbrido de registro instintivo de discurso (ASR) y Maniquí de jerigonza (LLM), que ahora encabeza la tabla de clasificación de AbrainAsr con un registro que establece récords Tasa de error de palabras (WER) de 5.63%. Con deshonestidad bajo Cc-byeste maniquí es los dos comercialmente permisivo y de código despejadoEmpujando […]
Clasificación de textos Zero-Shot y Few-Shot con SCIKIT-LLM

Analizar la opinión de los clientes y los temas esencia a partir de datos textuales siempre ha sido una tarea que requiere mucho tiempo y requiere resumen de datos, etiquetado manual y ajuste de modelos especializados. Pero, ¿qué pasaría si pudiera evitarse la molestia de entrenar un maniquí y aun así ganar resultados precisos? Ingrese […]
Prosperidad de la clasificación de neuroimagen basada en formación profundo con destilación de conocimientos de 3D a 2D

Las técnicas de formación profundo se aplican cada vez más al observación de neuroimagen, y las CNN 3D ofrecen un rendimiento superior para imágenes volumétricas. Sin bloqueo, su dependencia de grandes conjuntos de datos es un desafío adecuado al detención costo y esfuerzo requerido para la compilación y anotación de datos médicos. Como alternativa, las […]