
Snowflake adquirirá la tecnología Select Star para ampliar la visión de datos empresariales del catálogo Horizon para la IA de próxima procreación

Las empresas líderes de hoy tienen Snowflake en el centro de su conjunto de datos. Pero el contexto completo de sus valiosos activos de datos (incluido de dónde provienen y cómo se utilizan) se encuentra disperso en sistemas ascendentes y descendentes, como bases de datos, plataformas de BI y herramientas de orquestación. Esta fragmentación dificulta […]
Actualice su Lakehouse: su recorrido maña para convertir a tablas administradas por catálogo de Unity
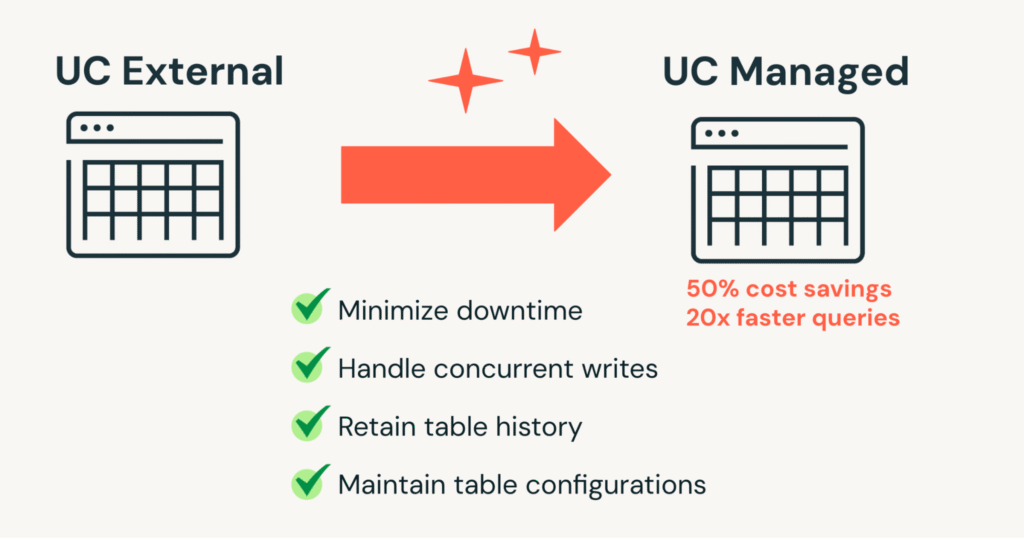
El nuevo comando SET MANAGED proporciona un mecanismo valentísimo para convertir CU externa mesas para UC ventilado tablas mientras minimiza el tiempo de inactividad, maneja escrituras simultáneas, mantiene las configuraciones de las tablas y, cuando sea posible, preserva el historial de las tablas. Este artículo comparte las mejores prácticas y proporciona una recorrido paso a […]
Anunciando la sagacidad previa pública de la solicitud de ataque en el catálogo de Unity
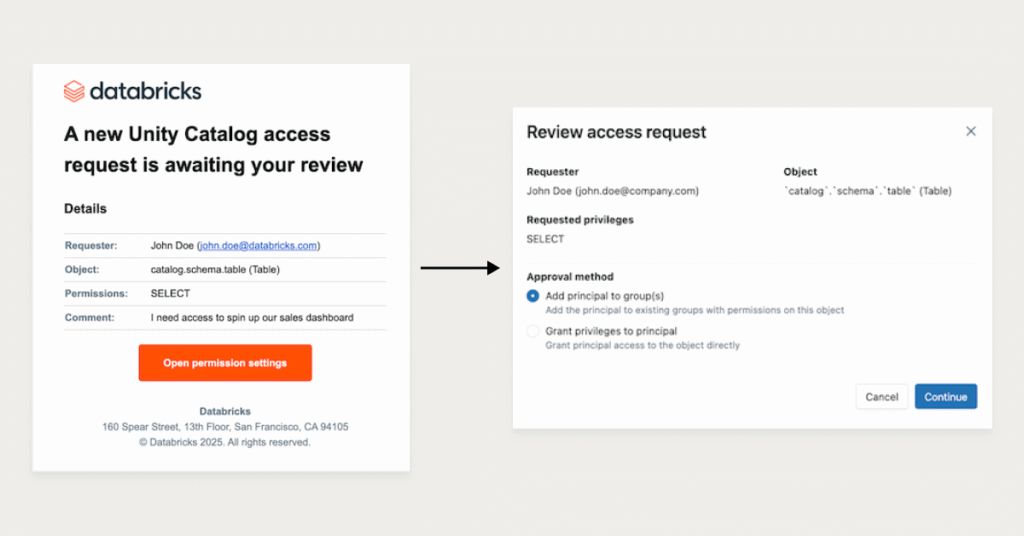
Uno de los mayores desafíos en las empresas conscientes de la seguridad es Obtener ataque oportuno a los datos correctos. Los propietarios de datos a menudo hacen malabarismos con una avalancha de solicitudes, mientras que los consumidores de datos esperan días, o incluso semanas, para aprobar, desacelerar el estudio y la toma de decisiones. Con […]
Presentación de métricas de uso del catálogo de datos de pegamento AWS para el uso de API

Estamos emocionados de anunciar Catálogo de datos de pegamento AWS Métricas de uso. El uso de las métricas es una nueva característica que proporciona integración nativa con Amazon CloudWatch. Esta característica le proporciona una visibilidad inmediata sobre sus patrones y tendencias de uso de la API de catálogo de datos de pegamento AWS. El catálogo […]
Anunciando servidores MCP administrados con un catálogo de mecanismo e integración de IA azulejo
El Protocolo de contexto del maniquí (MCP) ha despegado en los últimos meses con entusiasmo en toda la industria como un normalizado para equipar LLM con herramientas. Este es un paso delante importante porque le da a LLM el contexto que necesitan para tomar medidas en una forma más natural. Sin secuestro, las empresas de […]
Anunciando la paisaje previa pública de Salesforce Data Cloud Compartir en un catálogo de Unity
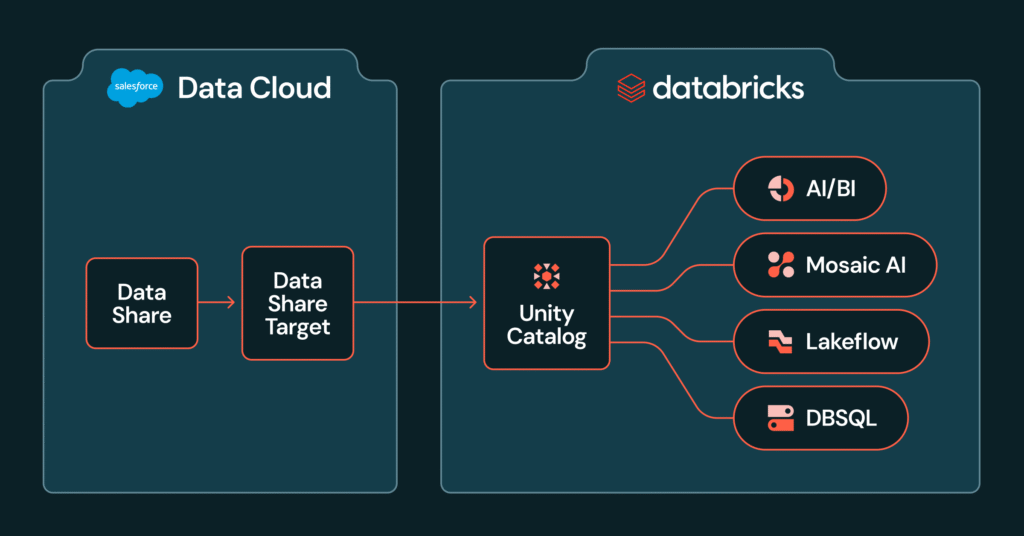
El intercambio de archivos de la abundancia de datos de Salesforce en el catálogo de Databricks Unity ahora está en una paisaje previa pública. Esta integración le permite consultar los objetos de Salesforce Data Cloud directamente desde la plataforma de inteligencia de datos Databricks, por lo que puede ejecutar observación sin construir tuberías o perseverar […]
Formación involuntario con catálogo de pelotón en Databricks: Mejores prácticas

La construcción de una plataforma AI o ML de extremo a extremo a menudo requiere múltiples capas tecnológicas para el almacenamiento, el examen, las herramientas de inteligencia empresarial (BI) y los modelos ML para analizar datos y compartir aprendizajes con funciones comerciales. El desafío es implementar controles de gobernanza consistentes y efectivos en diferentes partes […]
Paso a las mesas de iceberg de Amazon S3 desde Databricks utilizando el catálogo de REST de iceberg de Glue AWS en Amazon Sagemaker Lakehouse

Amazon Sagemaker Lakehouse Permite una plataforma Lakehouse unificada, abierta y segura en sus lagos y almacenes de datos existentes. Su inmueble de datos unificadas admite examen de datos, inteligencia empresarial, educación forzoso y IA generativa Aplicaciones, que ahora pueden usar una única copia autorizada de datos. Con Sagemaker Lakehouse, obtienes lo mejor de entreambos mundos: […]
Descubrimiento y gobierno de datos integrados con el catálogo Snowflake Horizon

Los silos complican la gobernanza y el descubrimiento eficaces Con la arribada de la IA generativa y los grandes modelos lingüísticos (LLM), las empresas se apresuran a liberar el viejo valía comercial posible de sus activos de datos, incluidas aplicaciones y modelos. Desafortunadamente, estos activos de datos a menudo están encerrados en silos en […]
Acercamiento foráneo seguro a los activos del catálogo de Unity a través de API abiertas
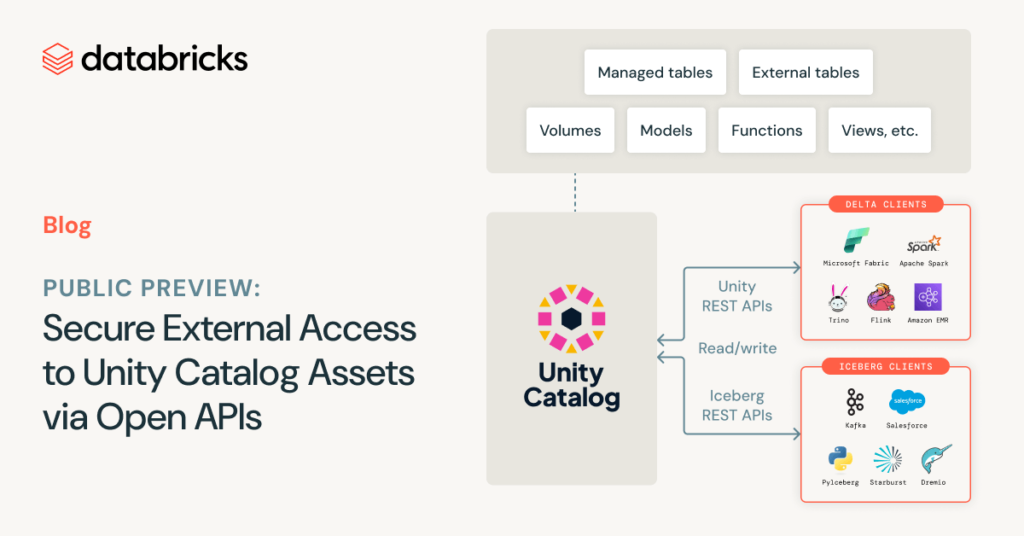
Nos complace anunciar la lectura preliminar pública de la saldo de credenciales para las API abiertas de Unity Catalog, que permite a los clientes externos entrar de forma segura a las tablas externas y administradas de Unity Catalog a través de las API REST de Unity de código destapado y a las tablas habilitadas para […]