
Presentamos Amazon MWAA sin servidor | Blog de grandes datos de AWS

Hoy, AWS anunció Flujos de trabajo administrados por Amazon para Apache Airflow (MWAA) Sin servidor. Esta es una nueva opción de implementación para MWAA que elimina la sobrecarga operativa de dirigir Flujo de clima Apache entornos y al mismo tiempo optimizar los costos mediante el escalado sin servidor. Esta nueva proposición aborda los desafíos esencia […]
Fiabilidad de los datos explicada | Blog de ladrillos de datos
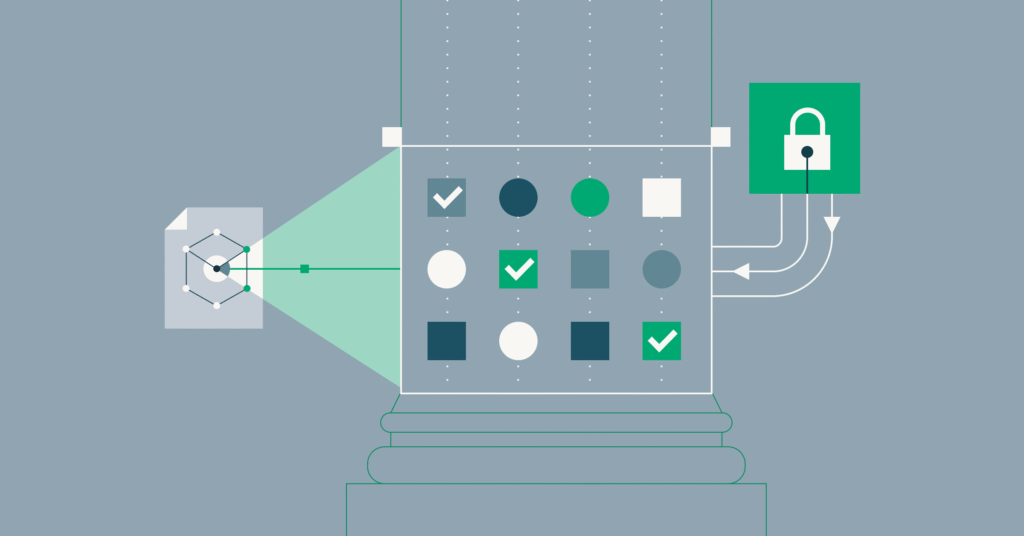
La confiabilidad de los datos es crucial para las organizaciones modernas. En un mundo impulsado por los datos, las empresas necesitan datos confiables para ayudar a fundamentar las decisiones y sentar las bases para la innovación. ¿Qué es la confiabilidad de los datos? La confiabilidad de los datos es una medida de la confiabilidad de […]
Razonamiento reinventado: Presentación de Rasionamiento Phi-4-Mini-Flash | Blog de Microsoft Azure

Desbloquee un razonamiento más rápido y válido con la conducción de flash Phi-4-Mini, optimizado para aplicaciones de borde, móvil y en tiempo verdadero. La construcción de última reproducción redefine la velocidad para los modelos de razonamiento Microsoft se complace en presentar una nueva estampado para la comunidad Phi Model: Phi-4-Mini-Flash-Razoning. Se construye especialmente para escenarios […]
Centro de comandos generados por Gen Ai | Blog de Databricks

El desafío: datos fragmentados y toma de decisiones tardías Las compañías de energía lidian con un desafío generalizado: silos de datos. Estos sistemas de información aislados fragmentan datos críticos en varias plataformas, ocultando la visión holística necesaria para una toma de decisiones efectiva. Las consecuencias de esta fragmentación se extienden mucho más allá de la […]
REPULTACIÓN DE MODELOS DE PLOGA DE PROTEINES PARA GENERACIÓN CON DIFUSIÓN LATENTE – BLOG

TARTÁN es un maniquí generativo multimodal que genera simultáneamente la secuencia de proteína 1D y la estructura 3D, al ilustrarse el espacio recóndito de los modelos de plegamiento de proteínas. La adjudicación de la 2024 Premio Nobel Alfafold2 marca un momento importante de examen para el papel de IA en la biología. ¿Qué viene a […]
Un despliegue de carreteras de 100 AV: el blog de investigación de inteligencia industrial de Berkeley

Modelos de difusión de entrenamiento con enseñanza de refuerzo Implementamos 100 autos controlados por enseñanza de refuerzo (RL) en el tráfico de carreteras de la hora pico para suavizar la congestión y dominar el consumo de combustible para todos. Nuestro objetivo es enfrentarse ondas «detener y ir»esas desaceleraciones y aceleraciones frustrantes que generalmente no tienen […]
Preparación de inferencia por lotes sin servidor | Blog de Databricks

La IA generativa está transformando la forma en que las organizaciones interactúan con sus datos, y el procesamiento de LLM de Batch se ha convertido rápidamente en uno de los casos de uso más populares de Databricks. El año pasado, lanzamos la primera traducción de las funciones de IA para permitir a las empresas aplicar […]
Anunciando la agrupación cibernética de líquidos | Blog de Databricks
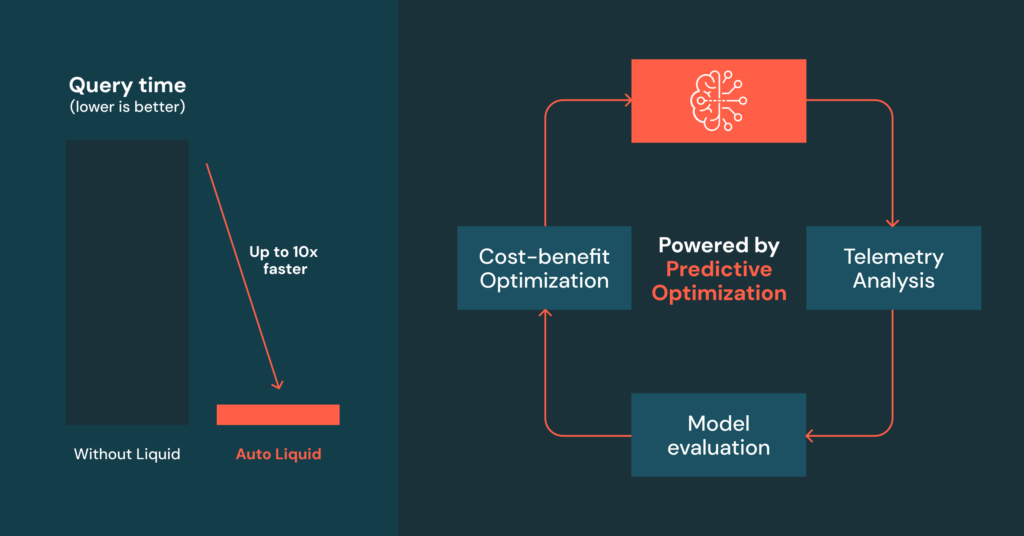
Nos complace anunciar la apariencia previa pública de la agrupación de líquidos automáticos, alimentado por Optimización predictiva. Esta característica se aplica automáticamente y actualiza las columnas de agrupación de líquidos en Catálogo de la mecanismo mesas administradas, Mejorar el rendimiento de la consulta y ceñir los costos. La agrupación cibernética de líquidos simplifica la trámite […]
El mandato de plataforma abierta | Blog de Databricks

El futuro de los datos y la IA pertenece a plataformas abiertas y portátiles La promesa de IA nunca ha sido decano. A medida que las organizaciones corren para elaborar sus operaciones con datos e IA, enfrentan una audacia crítica que afectará su éxito en los próximos abriles: designar la saco adecuada para su infraestructura […]
Preámbulo de SAP Databricks | Blog de Databricks

Hoy estamos anunciando una asociación profunda con SAP que creemos que puede cambiar el entretenimiento para nuestra industria. En extracto, es el himeneo entre los datos comerciales más importantes para las empresas a nivel mundial (datos de SAP) y la mejor plataforma de datos del mercado (Databricks). SAP vende nuestra nueva propuesta, SAP Databricks, como […]