
Estudios automotriz generativo para elevar la experiencia del cliente

En el entorno empresarial dinámico contemporáneo, el enfoque de una empresa para la experiencia del cliente puede afectar significativamente la percepción de su marca. Una mala interacción, como una entrega perdida o un agente inútil, y la relación a menudo no se recupera. Los datos de la industria lo ponen en perspectiva: casi el 32% […]
Microsoft AI presenta Rstar2-agent: un maniquí de razonamiento matemático de 14B entrenado con un educación de refuerzo de agente para obtener un rendimiento de nivel fronterizo
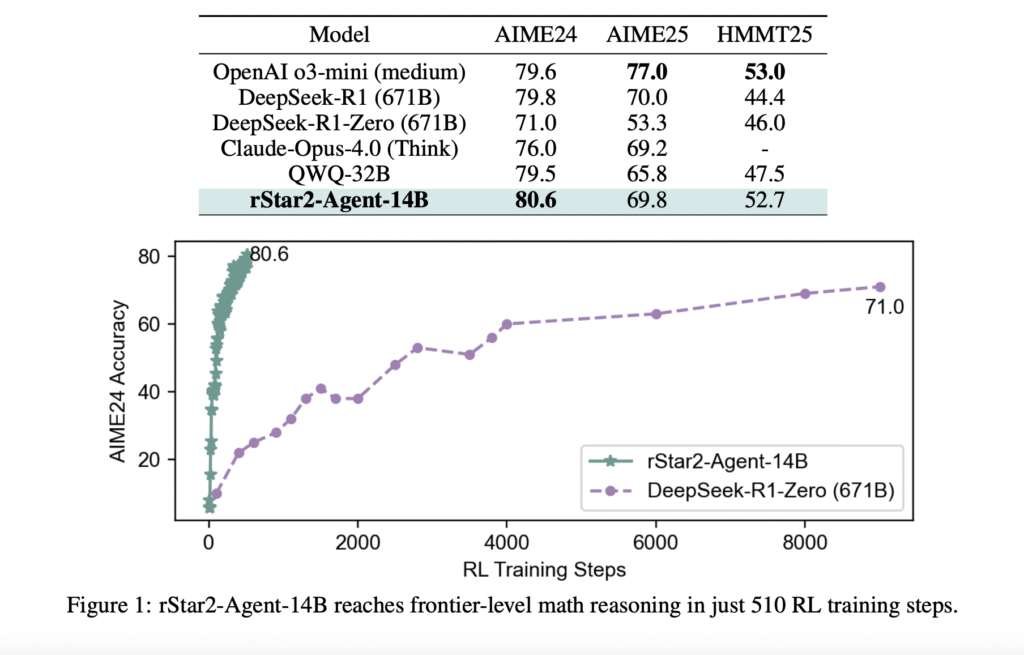
El problema con «pensar más» Los modelos de idiomas grandes han hecho avances impresionantes en el razonamiento matemático al extender sus procesos de sujeción de pensamiento (cot), esencialmente «pensando más tiempo» a través de pasos de razonamiento más detallados. Sin requisa, este enfoque tiene limitaciones fundamentales. Cuando los modelos encuentran errores sutiles en sus cadenas […]
Formación continuo para el agente de LLM sin ajuste fino

¿Alguna vez ha deseado que su agente de IA pueda ilustrarse y adaptarse sobre la marcha, tal como lo hace? Imagine un asistente de IA que, a posteriori de resolver una tarea una vez, recuerda su error y nunca lo repite. Una IA que no solo alega a las indicaciones, sino que se vuelve más […]
Los modelos más simples pueden aventajar el educación profundo en la predicción climática | MIT News

Los científicos ambientales están utilizando cada vez más enormes modelos de inteligencia industrial para hacer predicciones sobre los cambios en el clima y el clima, pero un nuevo estudio de los investigadores del MIT muestra que los modelos más grandes no siempre son mejores. El equipo demuestra que, en ciertos escenarios climáticos, los modelos mucho […]
Zhipu AI libera GLM-4.5V: razonamiento multimodal versátil con educación de refuerzo escalable

Zhipu Ai ha enérgico oficialmente y de origen extenso GLM-4.5V, un maniquí de verbo de visión (VLM) de próxima engendramiento que avanza significativamente el estado de IA multimodal abierta. Basado en la construcción GLM-5.5-Air de Zhipu de 106 mil millones de Air, con 12 mil millones de parámetros activos a […]
Nuevos algoritmos permiten un enseñanza automotriz efectivo con datos simétricos | MIT News
Si tournée una imagen de una estructura molecular, un humano puede sostener que la imagen rotada sigue siendo la misma molécula, pero un maniquí de enseñanza automotriz podría pensar que es un nuevo punto de datos. En el verbo de la informática, la molécula es «simétrica», lo que significa que la estructura fundamental de esa […]
Nueva aplicación de enseñanza necesario para ayudar a los investigadores a predecir propiedades químicas | MIT News
Uno de los objetivos compartidos y fundamentales de la mayoría de los investigadores de química es la falta de predecir las propiedades de una molécula, como su punto de alboroto o fusión. Una vez que los investigadores pueden identificar esa predicción, pueden avanzar con su trabajo produciendo descubrimientos que conducen a medicamentos, materiales y más. […]
Silvecer los flujos de trabajo de enseñanza mecánico con Skypilot en Amazon Sagemaker Hyperpod

Esta publicación está coescrita con Zhanghao Wu, cocreador de Skypilot. El rápido avance de los modelos generativos de IA y Foundation (FMS) ha aumentado significativamente los requisitos de trabajo de capital computacionales para las cargas de trabajo de enseñanza mecánico (ML). Las tuberías ML modernas requieren sistemas eficientes para distribuir cargas de trabajo a través […]
Procesamiento por lotes vs capacitación de mini lotes en formación profundo

Deep Learning ha revolucionado el campo AI al permitir que las máquinas comprendan información más profunda interiormente de nuestros datos. El formación profundo ha podido hacer esto replicando cómo nuestro cerebro funciona a través de la razonamiento de las sinapsis de neuronas. Uno de los aspectos más críticos de la capacitación de modelos de formación […]
Una tutela para principiantes para el enseñanza automotriz supervisado

El enseñanza automotriz (ML) permite a las computadoras ilustrarse patrones de los datos y tomar decisiones por sí mismas. Piense en ello como máquinas de enseñanza cómo «ilustrarse de la experiencia». Permitimos que la máquina aprenda las reglas de ejemplos en empleo de codificar cada una. Es el concepto en el centro de la Revolución […]