
Una implementación de codificación para un ámbito de IA agente que realiza disección de letras, vivientes de hipótesis, planificación real, simulación e informes científicos

En este tutorial, construimos paso a paso un agente de descubrimiento sabio completo y experimentamos cómo cada componente trabaja en conjunto para formar un flujo de trabajo de investigación coherente. Comenzamos cargando nuestro corpus de letras, construyendo módulos de recuperación y LLM, y luego ensamblando agentes que buscan artículos, generan hipótesis, diseñan experimentos y producen […]
Cómo crear un panel de observación interactivo de un extremo a otro utilizando las funciones de PyGWalker para una exploración de datos detallada

def generate_advanced_dataset(): np.random.seed(42) start_date = datetime(2022, 1, 1) dates = (start_date + timedelta(days=x) for x in range(730)) categories = (‘Electronics’, ‘Clothing’, ‘Home & Garden’, ‘Sports’, ‘Books’) products = { ‘Electronics’: (‘Laptop’, ‘Smartphone’, ‘Headphones’, ‘Tablet’, ‘Smartwatch’), ‘Clothing’: (‘T-Shirt’, ‘Jeans’, ‘Dress’, ‘Jacket’, ‘Sneakers’), ‘Home & Garden’: (‘Furniture’, ‘Lamp’, ‘Rug’, ‘Plant’, ‘Cookware’), ‘Sports’: (‘Yoga Mat’, ‘Dumbbell’, ‘Running Shoes’, […]
Cómo las empresas líderes ofrecen prospección de hipermercado confiables y basados en inteligencia sintético

En poco más de un año desde el dispersión de Databricks AI/BI, la apadrinamiento se ha disparado a medida que las organizaciones transforman su enfoque para tomar decisiones basadas en datos. Hoy, más del 98% de los clientes de Databricks SQL utilizan AI/BI poner la inteligencia en manos de cada empleado. Para mostrar lo que […]
Ayudar a los científicos a realizar estudio de datos complejos sin escribir código | Parte del MIT
A medida que los costos de las tecnologías de dictamen y secuenciación se han desplomado en los últimos abriles, los investigadores han recopilado una cantidad sin precedentes de datos sobre enfermedades y biología. Desafortunadamente, los científicos que esperan tener lugar de los datos a nuevas curas a menudo necesitan la ayuda de cierto con experiencia […]
Acelerar el descomposición SQL con Amazon Redshift MCP Server

Como analistas de datos e ingenieros, a menudo nos encontramos cambiando entre múltiples herramientas para explorar esquemas de bases de datos, comprender las estructuras de la tabla y ejecutar consultas en diferentes Amazon Redshift almacenes de datos. El uso del jerigonza natural para explorar metadatos y datos puede simplificar este proceso, pero un agente de […]
Estudio de marketing sobre sobrealimentaciones con habitaciones limpias de datos y servicios de contenedores Snowpark

Se paciencia que los ingenieros de datos en el mundo acelerado de marketing y publicidad entreguen ideas granulares, construyen segmentos sofisticados de clientes y midan la efectividad de la campaña con reincorporación precisión. Al mismo tiempo, se enfrentan a una serie de desafíos, que incluyen un creciente matorral de regulaciones de privacidad y la menester […]
Una implementación de codificación para crear una transcripción interactiva y un observación PDF con el ámbito Lyzr ChatBot
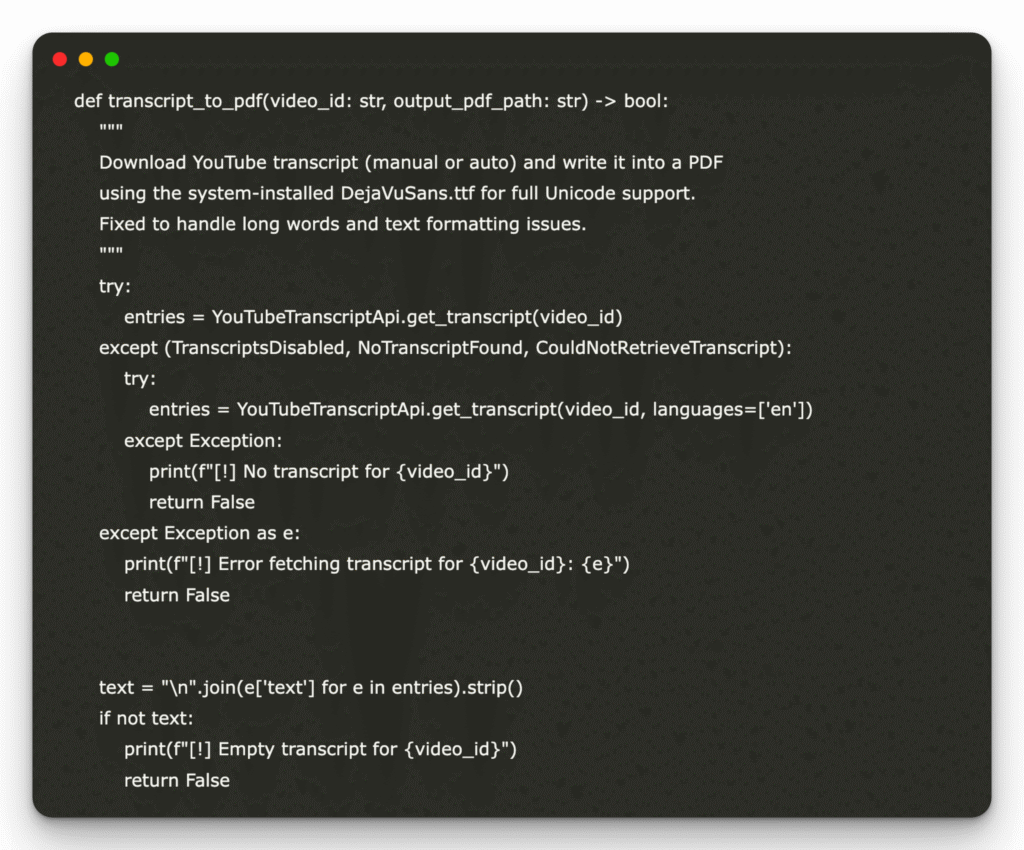
En este tutorial, presentamos un enfoque optimizado para extraer, procesar y analizar las transcripciones de video de YouTube utilizando Lyzrun ámbito progresista con AI diseñado para simplificar la interacción con datos textuales. Aprovechando la interfaz de chatbot intuitiva de Lyzr conexo con YouTube-Transcript-API y FPDF, los usuarios pueden convertir sin esfuerzo el contenido de video […]
Nuevas capacidades de automatización de datos de rock de Amazon optimizar el examen de video y audio

Las organizaciones en una amplia viso de industrias están luchando por procesar cantidades masivas de contenido de video y audio no estructurado para respaldar sus aplicaciones comerciales centrales y sus prioridades organizativas. Amazon Bedrock Data Automation Los ayuda a cumplir con este desafío racionalizando el expansión de aplicaciones y automatizando los flujos de trabajo que […]
Maximizar la utilización del equipo a través de exploración geoespacial

La administración de equipos de parada valía desplegado en los sitios operativos es un desafío global para las empresas de construcción. En respuesta, muchos fabricantes de equipos originales están conectando equipos con Internet de las cosas, creando nuevas oportunidades para soluciones digitales que impulsan la eficiencia en todo el ciclo de vida del tesina. De […]
Simplificar el observación de datos multimodales con Snowflake Cortex AI
Claude 3.5 Sonnet sobresale en la comprensión del documento con un impresionante 90.3% en Docvqa Benchmark, por lo que es una opción óptima para extraer información de estados financieros, contratos legales y documentación de cumplimiento. Pixtral sobresaliente se destaca con un observación de expresivo extra (88.1% CACHQA) y razonamiento matemático (69.4% Mathvista), consumado para informes […]