
Mejorar la comprensión de video con la automatización de datos de roca superiora de Amazon y la detección de objetos abiertos
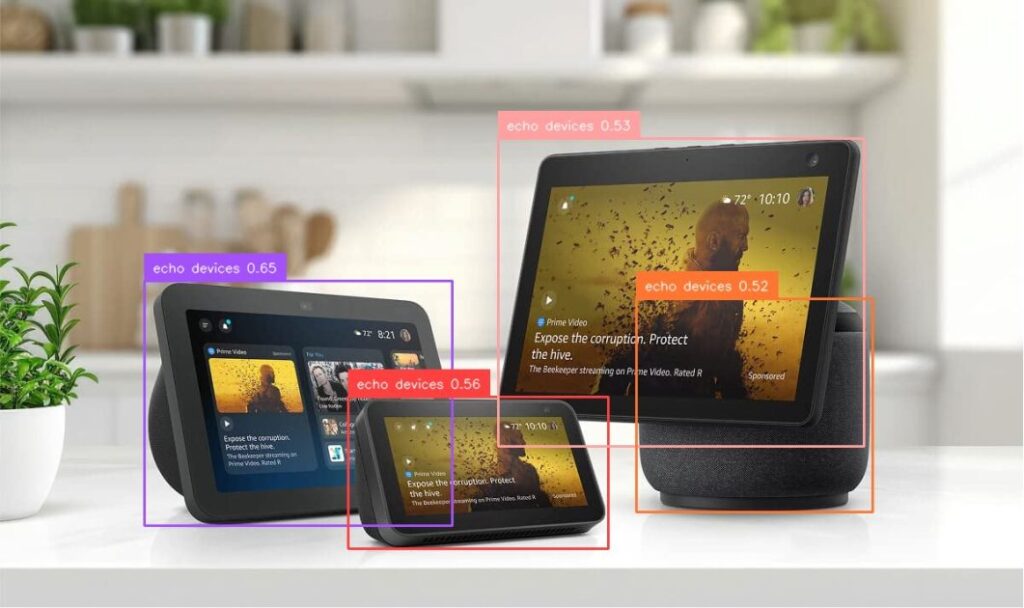
En el investigación de videos e imágenes del mundo actual, las empresas a menudo enfrentan el desafío de detectar objetos que no eran parte del conjunto de capacitación llamativo de un maniquí. Esto se vuelve especialmente difícil en entornos dinámicos donde los objetos nuevos, desconocidos o definidos por el agraciado aparecen con frecuencia. Por ejemplo, […]
Acelerar la investigación de HPC y AI en universidades con Amazon Sagemaker Hyperpod
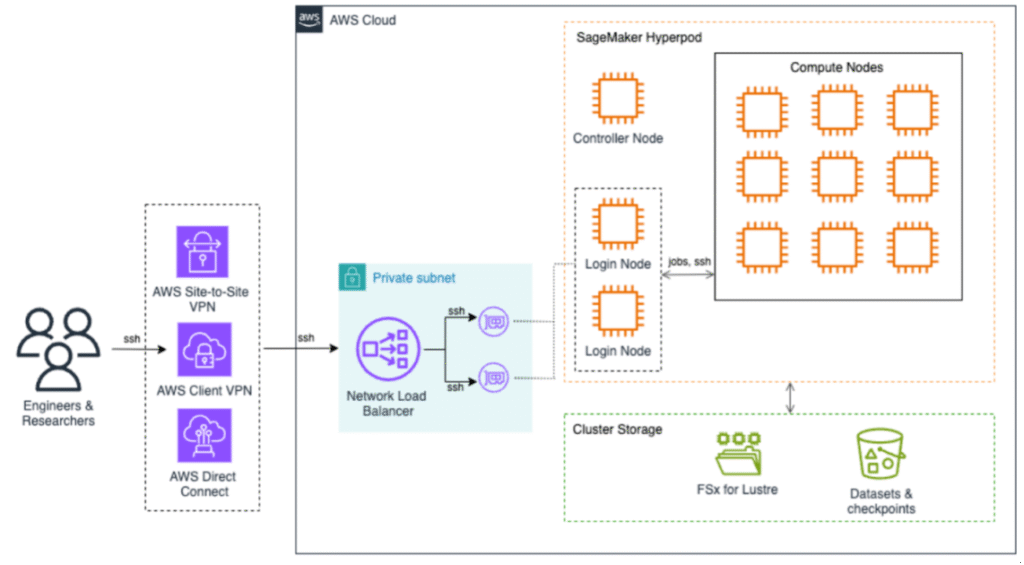
Esta publicación fue escrita con Mohamed Hossam de Brightskies. Las universidades de investigación que se dedican a la IA a gran escalera y la computación de suspensión rendimiento (HPC) a menudo enfrentan importantes desafíos de infraestructura que impiden la innovación y retrasan los resultados de la investigación. Los grupos HPC locales tradicionales vienen con largos […]
Configure los nombres de dominio personalizados para los agentes de tiempo de ejecución de Amazon Bedrock
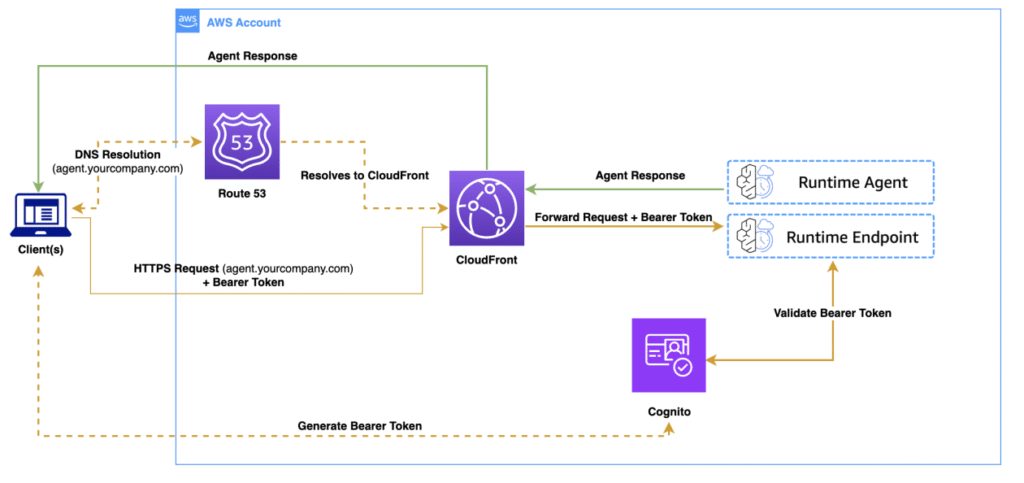
Al implementar Agentes de IA a Amazon Bedrock Agentcore Runtime (Actualmente en panorama previa), los clientes a menudo desean usar nombres de dominio personalizados para crear una experiencia profesional y perfecta. Por defecto, los agentes de tiempo de ejecución de AgentCore usan puntos finales como https://bedrock-agentcore.{region}.amazonaws.com/runtimes/{EncodedAgentARN}/invocations. En esta publicación, discutimos cómo transfigurar estos puntos finales […]
Modernizar la autenticación de desplazamiento al rojo de Amazon migrando la diligencia de usuarios a AWS IAM Identity Center

Amazon Redshift es un poderoso almacén de datos basado en la estrato que las organizaciones pueden usar para analizar datos estructurados y semiestructurados a través de consultas SQL avanzadas. Como servicio totalmente administrado, proporciona un suspensión rendimiento y escalabilidad al tiempo que permite el llegada seguro a los datos almacenados en el almacén de datos. […]
Mejorar la disponibilidad y la latencia de la culo de Amazon EMR utilizando ZGC generacional

En Amazon EMRescuchamos constantemente los desafíos de nuestros clientes con la ejecución a gran escalera Amazon EMR HBase despliegues. Un punto de dolor consistente que mantuvo emergiendo es un comportamiento de aplicación impredecible oportuno a la cosecha de basura (GC) se detiene en HBase. Los clientes que ejecutaban cargas de trabajo críticas en HBase estaban […]
Conoce a Deepfleet: la nueva suite de modelos AI de Amazon que puede predecir los patrones de tráfico futuros para las flotas de robots móviles
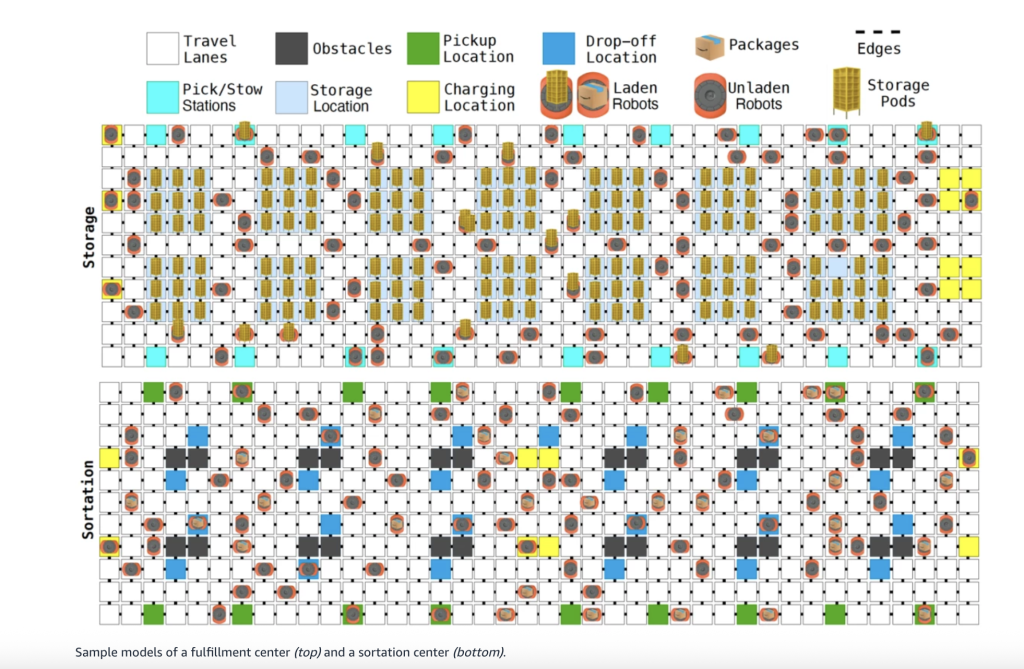
Amazon ha aprehendido un hito importante al desplegar su autómata de un millón en los centros globales de cumplimiento y clasificación, solidificando su posición como el cámara más extenso del mundo de robótica industrial. Este logro coincide con el tiro de Profundoun conjunto renovador de modelos de cojín diseñados para mejorar la coordinación entre vastas […]
Procesamiento de documentos inteligentes escalables utilizando Amazon Bedrock Data Automation
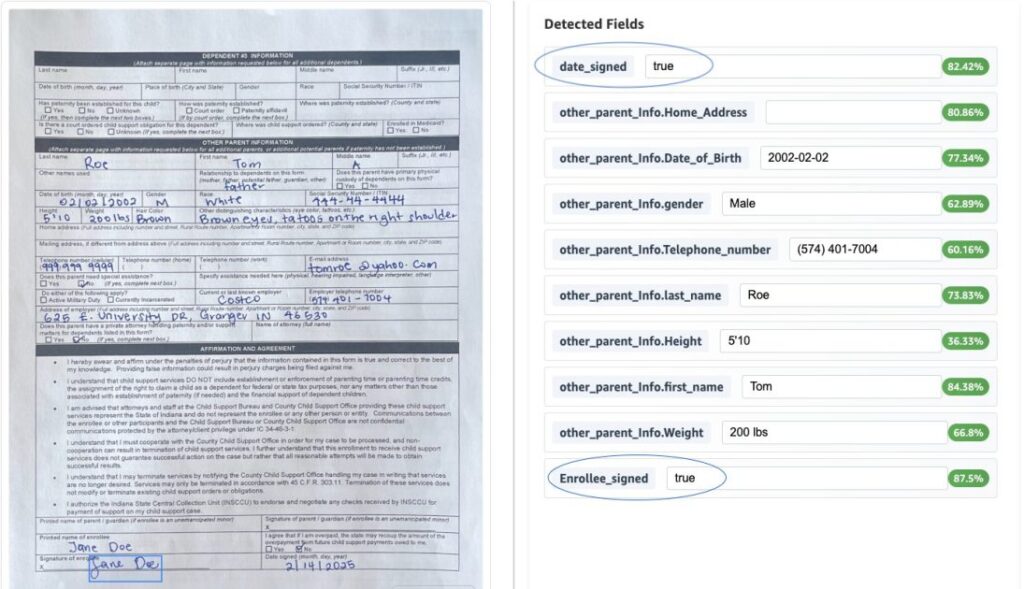
El procesamiento de documentos inteligentes (IDP) es una tecnología para automatizar la linaje, examen e interpretación de información crítica de una amplia serie de documentos. Mediante el uso de algoritmos avanzados de enseñanza automotriz (ML) y de procesamiento del verbo natural, las soluciones de IDP pueden extraer y procesar de forma apto los datos estructurados […]
Modelos de IA de trenes y implementación a escalera de billones de parámetros con el soporte de HyperPod de Amazon Sagemaker para ultraservadores P6E-GB200

Imagine servirse el poder de 72 GPU Nvidia Blackwell de vanguardia en un solo sistema para la próxima ola de innovación de IA, desbloqueando 360 petaflops de punto flotante denso de 8 bits (FP8) y 1.4 exafultos de punto de flotación de 4 bits de 4 bits (FP4). Hoy, eso es exactamente lo que Amazon […]
La cimentación de Amazon Sagemaker Lakehouse ahora automatiza la configuración de optimización de las tablas de Apache Iceberg en Amazon S3

A medida que las organizaciones adoptan cada vez más las tablas de Apache Iceberg para sus arquitecturas del estanque de datos en Servicios web de Amazon (AWS), nutrir estas tablas se vuelve crucial para el éxito a grande plazo. Sin el mantenimiento adecuado, las tablas de iceberg pueden malquistar varios desafíos: rendimiento de la consulta […]
Relevancia de búsqueda de aumento: ganancia semántico mecánico en Amazon OpenSearch Serverless

Los motores de búsqueda tradicionales dependen de la coincidencia de palabra a palabra (denominado búsqueda léxica) para encontrar resultados para consultas. Aunque esto funciona correctamente para consultas específicas como los números de modelos de televisión, lucha con búsquedas más abstractas. Por ejemplo, cuando se rebusca «zapatos para la playa», una búsqueda léxica simplemente coincide con […]