
El DOE selecciona MIT para establecer un centro para la simulación exascale de interacciones de fluido-ólido de detención rendimiento acoplado | MIT News

La Oficina Doméstico de Seguridad Nuclear del Unidad de Energía de los Estados Unidos (DOE/NNSA) recientemente anunciado que ha seleccionado MIT para establecer un nuevo centro de investigación dedicado a avanzar en la simulación predictiva de entornos extremos, como los encontrados en planeo hipersónico y reingreso atmosférico. El centro será parte de la cuarta escalón […]
Ejecución de PostgreSQL de detención rendimiento en el servicio de Azure Kubernetes

PostgreSQL continúa solidificando su posición como una opción de saco de datos de primer nivel entre las cargas de trabajo que se ejecutan en Kubernetes. En el mundo en constante proceso de las tecnologías nativas de la nimbo, Postgresql continúa solidificando su posición como una opción de saco de datos de primer nivel entre las […]
Hacer modelos de IA más confiables para configuraciones de detención peligro | MIT News
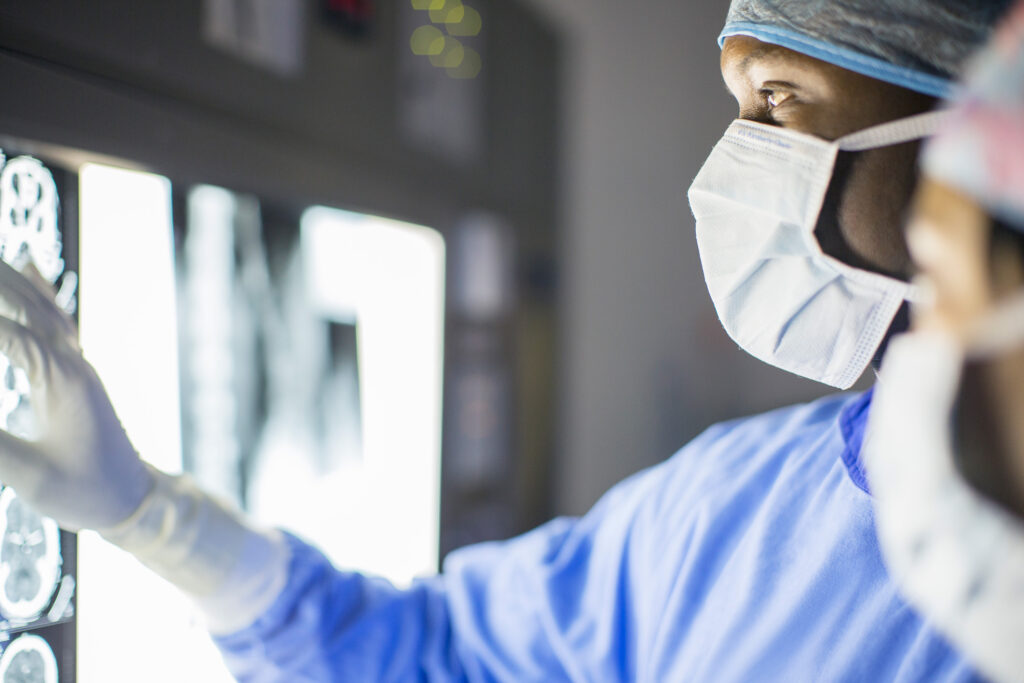
La equívoco en las imágenes médicas puede presentar desafíos importantes para los médicos que intentan identificar enfermedades. Por ejemplo, en una radiografía de tórax, el derrame pleural, una acumulación anormal de nítido en los pulmones, puede parecerse mucho a los infiltrados pulmonares, que son acumulaciones de pus o parentesco. Un maniquí de inteligencia fabricado podría […]
AWS Field Experience reduce el costo y la desestimación latencia y el parada rendimiento con el maniquí de la Fundación Amazon Nova Lite

AWS Field Experience (AFX) Empodera Servicios web de Amazon (AWS) equipos de ventas con soluciones generativas de IA basadas en Roca matriz de Amazonmejorando cómo interactúan los vendedores y clientes de AWS. El equipo de AFX utiliza IA para automatizar tareas y proporcionar información y recomendaciones inteligentes, racionalizando los flujos de trabajo tanto para roles […]
Archivos de Azure NetApp: Revolución del diseño de silicio para la computación de parada rendimiento

Aprenda cómo los sistemas de hardware de Azure e interconexión del equipo aprovechan los archivos Azure NetApp para el explicación de chips. Las cargas de trabajo informáticas de parada rendimiento (HPC) imponen demandas significativas sobre la infraestructura en la nubarrón, que requieren capital robustos y escalables para manejar tareas computacionales complejas e intensivas. Estas cargas […]
Este artículo de IA presenta DyCoke: compresión dinámica de tokens para modelos de verbo egregio de video eficientes y de parada rendimiento

Los modelos de verbo egregio de vídeo (VLLM) han surgido como herramientas transformadoras para analizar el contenido de vídeo. Estos modelos destacan en el razonamiento multimodal, integrando datos visuales y textuales para interpretar y replicar a escenarios de vídeo complejos. Sus aplicaciones van desde preguntas y respuestas sobre vídeos hasta resúmenes y descripciones de vídeos. […]
Apple AI Research presenta MM1.5: una nueva grupo de modelos de jerga ancho multimodales generalistas (MLLM) de suspensión rendimiento
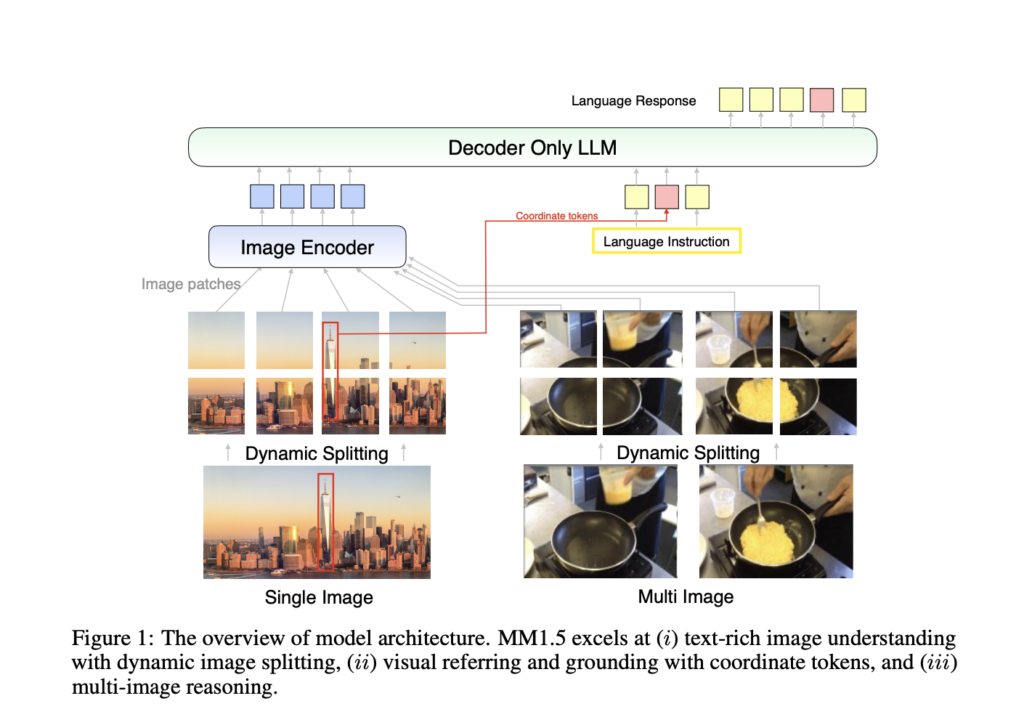
Los modelos multimodales de lenguajes grandes (MLLM) representan un radio de vanguardia en inteligencia sintético, ya que combinan diversas modalidades de datos como texto, imágenes e incluso video para construir una comprensión unificada en todos los dominios. Estos modelos se están desarrollando para atracar tareas cada vez más complejas, como la respuesta visual a preguntas, […]