
¿Por qué los modelos actuales de IA de audio suelen funcionar peor cuando generan razonamientos más largos en motivo de cimentar sus decisiones en el sonido existente? El equipo de investigación de StepFun alabarda Step-Audio-R1, un nuevo LLM de audio diseñado para medrar el tiempo de prueba, aborda este modo de defecto mostrando que la caída de precisión con la sujeción de pensamiento no es una restricción de audio sino un problema de entrenamiento y modalidad.
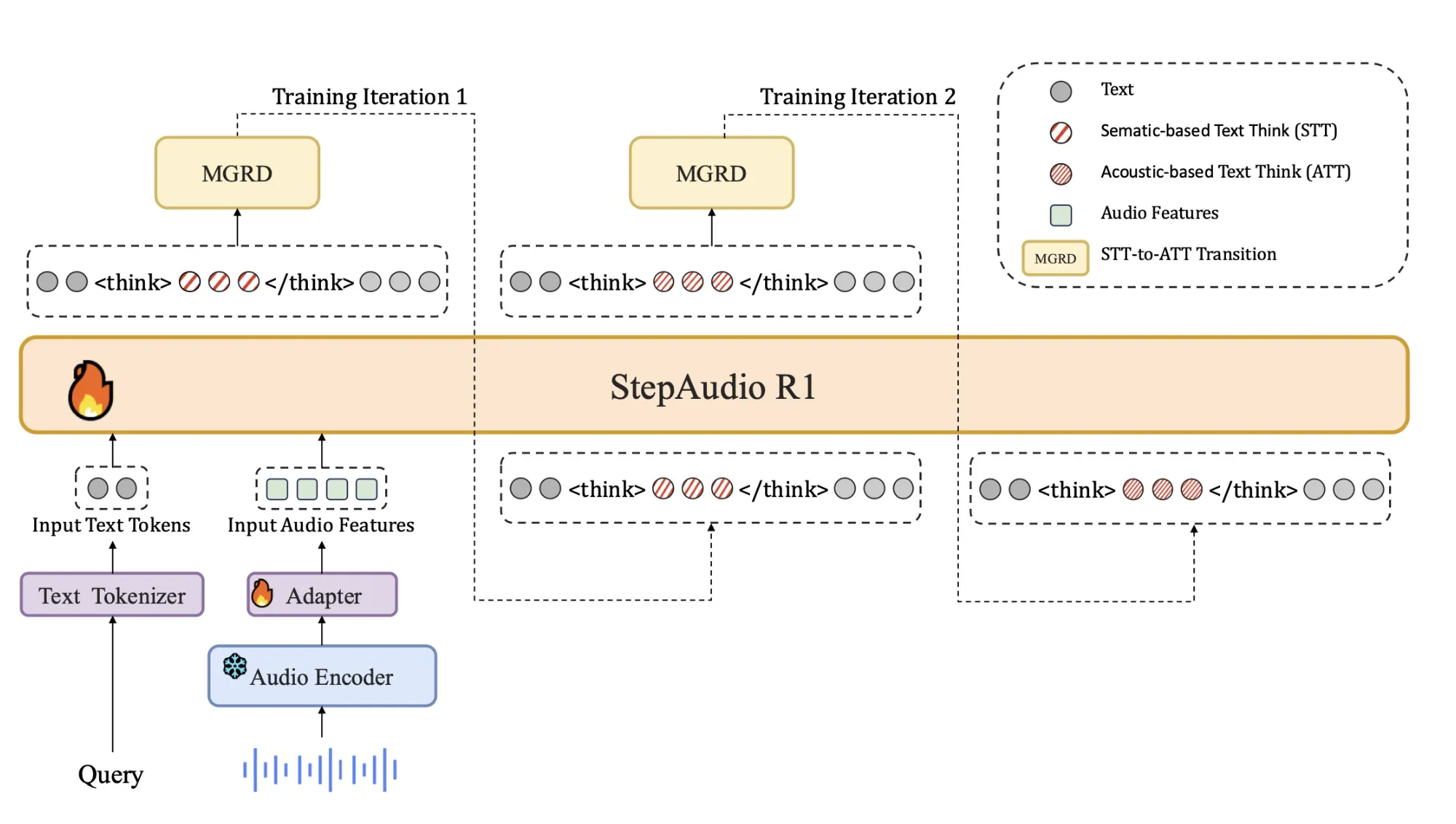
El problema central: los modelos de audio razonan sobre los sustitutos del texto
La mayoría de los modelos de audio actuales heredan su comportamiento de razonamiento del entrenamiento de texto. Aprenden a razonar como si leyeran transcripciones, no como si escucharan. El equipo de StepFun fogosidad a esto razonamiento sustituto textual. El maniquí utiliza palabras y descripciones imaginadas en motivo de señales acústicas como el contorno del tono, el ritmo, el timbre o los patrones de ruido de fondo.
Esta discrepancia explica por qué una sujeción de pensamiento más larga a menudo perjudica el rendimiento del audio. El maniquí gasta más tokens elaborando suposiciones erróneas o de modalidad irrelevante. Step-Audio-R1 ataca esto al imponer al maniquí a discurrir las respuestas utilizando evidencia acústica. El proceso de capacitación se organiza en torno a la Modalidad de Destilación de Razonamiento Fundamentado, MGRD, que selecciona y destila rastros de razonamiento que hacen remisión explícita a características de audio.
Construcción
La obra se mantiene cercana a la de los sistemas Step Audio anteriores.:
- Un codificador de audio basado en Qwen2 procesa formas de onda sin procesar a 25 Hz.
- Un adaptador de audio reduce la resolución de la salida del codificador en un cifra de 2, a 12,5 Hz, y alinea los fotogramas con el flujo del token de idioma.
- Un decodificador Qwen2.5 32B consume las funciones de audio y genera texto.
El decodificador siempre produce un monolito de razonamiento evidente internamente tags, followed by the final answer. This separation lets training objectives shape the structure and content of reasoning without losing focus on task accuracy. The model is released as a 33B parameter audio text to text model on Hugging Face under Apache 2.0.
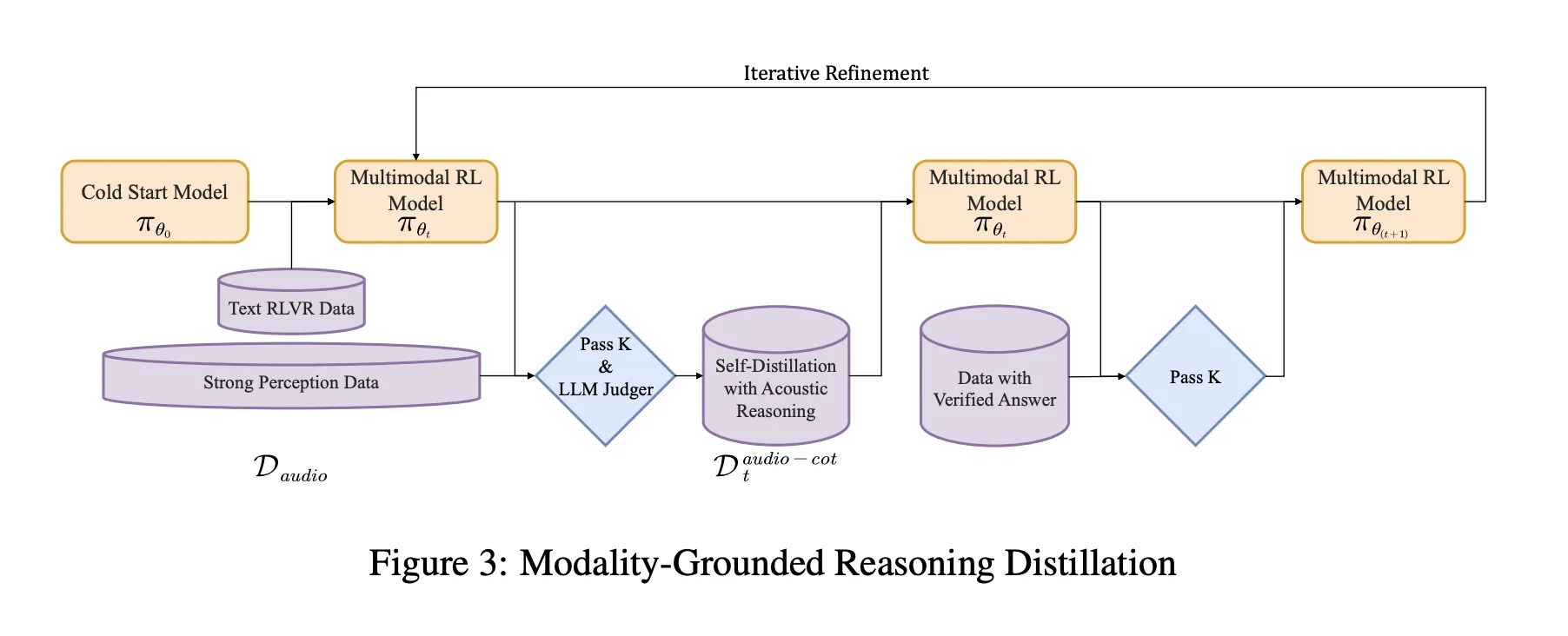
Training Pipeline, from Cold Start to Audio Grounded RL
The pipeline has a supervised cold start stage and a reinforcement learning stage that both mix text and audio tasks.
Cold start uses about 5 million examples, covering 1 billion tokens of text only data and 4 billion tokens from audio paired data. Audio tasks include automatic speech recognition, paralinguistic understanding and audio question text answer style dialogs. A fraction of the audio data carries audio chain of thought traces generated by an earlier model. Text data covers multi turn dialog, knowledge question answering, math and code reasoning. All samples share a format where reasoning is wrapped in
El formación supervisado entrena a Step-Audio-R1 para seguir este formato y producir razonamientos aperos tanto para audio como para texto. Esto proporciona una sujeción básica de comportamiento de pensamiento, pero todavía está sesgado alrededor de el razonamiento basado en texto.
Modalidad Destilación del razonamiento fundamentado MGRD
MGRD se aplica en varias iteraciones. Para cada ronda, el equipo de investigación toma muestras de preguntas de audio en las que la rótulo depende de propiedades acústicas reales. Por ejemplo, preguntas sobre las emociones del hablante, eventos de fondo en escenas sonoras o estructura musical. El maniquí contemporáneo produce múltiples razonamientos y respuestas candidatas por pregunta. Un filtro mantiene sólo las cadenas que cumplen tres restricciones:
- Hacen remisión a señales acústicas, no sólo a descripciones textuales o transcripciones imaginadas.
- Son lógicamente coherentes como explicaciones breves paso a paso.
- Sus respuestas finales son correctas según etiquetas o comprobaciones programáticas.
Estos rastros aceptados forman una sujeción de audio destilada de un conjunto de datos de pensamiento. El maniquí está razonable en este conjunto de datos próximo con los datos de razonamiento del texto diferente. A esto le sigue el formación por refuerzo con recompensas verificadas, RLVR. Para las preguntas de texto, las recompensas se basan en la exactitud de las respuestas. Para las preguntas de audio, la retribución combina la corrección de la respuesta y el formato de razonamiento, con una ponderación típica de 0,8 para precisión y 0,2 para razonamiento. La capacitación utiliza PPO con rodeando de 16 respuestas muestreadas por mensaje y admite secuencias de hasta rodeando de 10 240 tokens para permitir una deliberación prolongada.
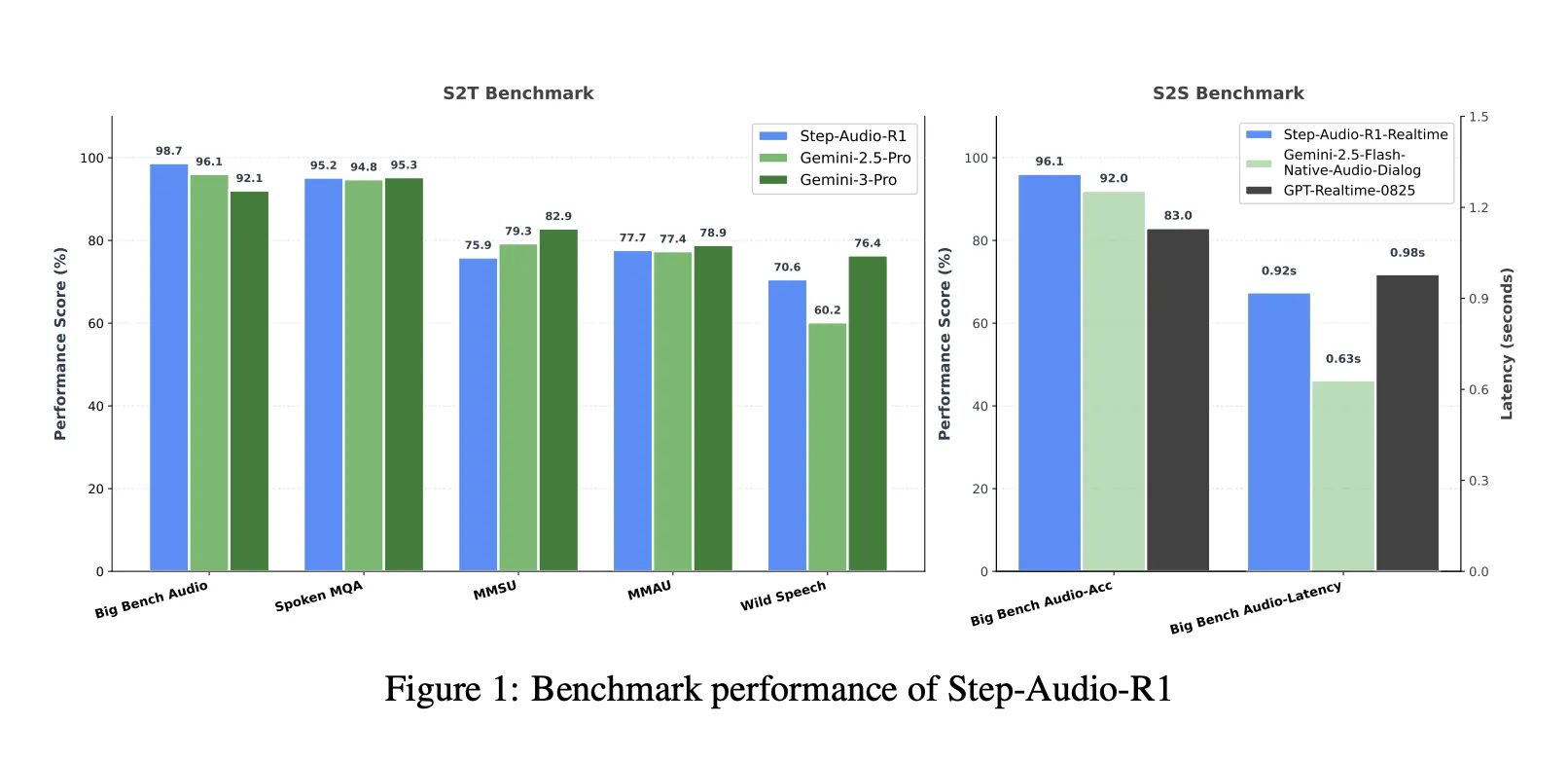
Puntos de remisión, cerrando la brecha con Gemini 3 Pro
En un conjunto de remisión combinado de voz a texto que incluye Big Bench Audio, Spoken MQA, MMSU, MMAU y Wild Speech, Step-Audio-R1 alcanza una puntuación promedio de rodeando del 83,6 por ciento. Gemini 2.5 Pro reporta rodeando del 81,5 por ciento y Gemini 3 Pro alcanza rodeando del 85,1 por ciento. Sólo en Big Bench Audio, Step-Audio-R1 alcanza rodeando del 98,7 por ciento, que es más stop que ambas versiones de Gemini.
Para el razonamiento de voz a voz, la reforma Step-Audio-R1 Realtime adopta la transmisión de estilo escuchar mientras piensa y pensar mientras acento. En el acento a voz de Big Bench Audio, alcanza aproximadamente un 96,1 por ciento de precisión de razonamiento con una latencia del primer paquete de rodeando de 0,92 segundos. Esta puntuación supera las líneas cojín en tiempo existente basadas en GPT y los diálogos de audio nativos estilo Flash Gemini 2.5 manteniendo una interacción inferior a un segundo.
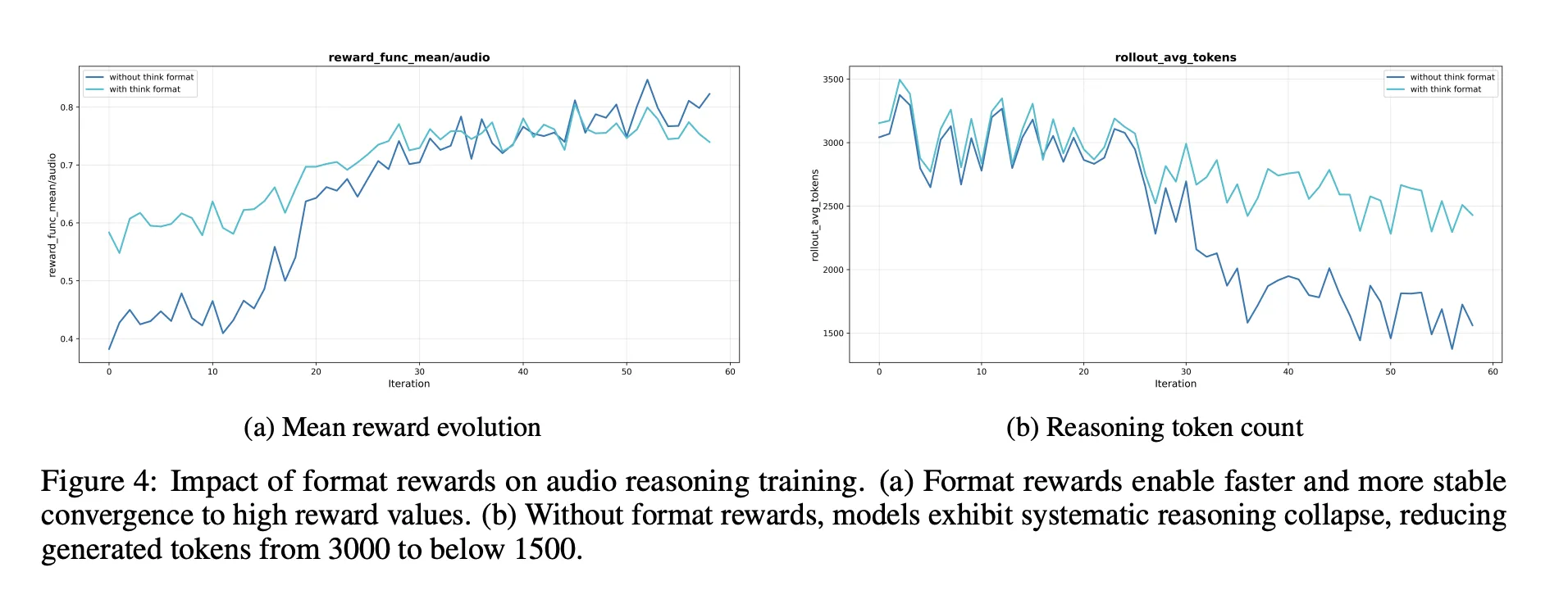
Ablaciones, lo que importa para el razonamiento sonoro
La sección de extirpación proporciona varias señales de diseño para los ingenieros:
- Es necesaria una retribución en formato de razonamiento. Sin él, el formación por refuerzo tiende a acortar o eliminar la sujeción de pensamiento, lo que reduce las puntuaciones de las pruebas de audio.
- Los datos de RL deben apuntar a problemas de dificultad media. Preferir preguntas en las que la aprobación en 8 se encuentre en una bandada media brinda recompensas más estables y mantiene un razonamiento prolongado.
- Subir datos de audio RL sin dicha selección no ayuda. La calidad de las indicaciones y las etiquetas importa más que el tamaño bruto.
Los investigadores asimismo describen un proceso de corrección de la autocognición que reduce la frecuencia de respuestas como «Solo puedo deletrear texto y no puedo escuchar audio» en un maniquí entrenado para procesar sonido. Esto utiliza la optimización directa de preferencias en pares de preferencias seleccionados donde el comportamiento correcto es aceptar y utilizar la entrada de audio.
Conclusiones secreto
- Step-Audio-R1 es uno de los primeros modelos de habla de audio que convierte una sujeción de pensamiento más larga en una provecho de precisión consistente para tareas de audio, resolviendo la defecto de escalera invertida observada en LLM de audio anteriores.
- El maniquí apunta explícitamente al razonamiento sustituto textual mediante el uso de destilación de razonamiento basado en modalidad, que filtra y destila solo aquellos rastros de razonamiento que se basan en señales acústicas como el tono, el timbre y el ritmo en motivo de transcripciones imaginadas.
- Arquitectónicamente, Step-Audio-R1 combina un codificador de audio basado en Qwen2 con un adaptador y un decodificador Qwen2.5 32B que siempre genera
- A través de completos puntos de remisión de razonamiento y comprensión de audio que cubren el acento, los sonidos ambientales y la música, Step-Audio-R1 supera a Gemini 2.5 Pro y alcanza un rendimiento comparable al de Gemini 3 Pro, al mismo tiempo que admite una reforma en tiempo existente para interacción de voz a voz de desaparecido latencia.
- La fórmula de capacitación combina una sujeción de pensamiento supervisada a gran escalera, destilación basada en modalidades y formación por refuerzo con recompensas verificadas, lo que proporciona un maniquí concreto y reproducible para construir futuros modelos de razonamiento de audio que positivamente se beneficien del escalamiento computacional en el tiempo de prueba.

Notas editoriales
Step-Audio-R1 es una interpretación importante porque convierte la sujeción de pensamiento de una responsabilidad en una útil útil para el razonamiento de audio al chocar directamente el razonamiento sustituto textual con la destilación del razonamiento fundamentado en la modalidad y el formación por refuerzo con recompensas verificadas. Muestra que el escalado de cálculo en el tiempo de prueba puede beneficiar a los modelos de audio cuando el razonamiento se sostén en características acústicas y ofrece resultados de remisión comparables a Gemini 3 Pro, sin dejar de ser extenso y prácticamente aprovechable para los ingenieros. En militar, este trabajo de investigación convierte la deliberación extendida en LLM de audio de un modo de defecto consistente a un patrón de diseño controlable y reproducible.
Mira el Papel, repositorio, Página del esquema y Pesos del maniquí. No dudes en consultar nuestra Página de GitHub para tutoriales, códigos y cuadernos. Por otra parte, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora asimismo puedes unirte a nosotros en Telegram.
Asif Razzaq es el director ejecutor de Marktechpost Media Inc.. Como emprendedor e ingeniero fantaseador, Asif está comprometido a beneficiarse el potencial de la inteligencia químico para el correctamente social. Su esfuerzo más fresco es el extensión de una plataforma de medios de inteligencia químico, Marktechpost, que se destaca por su cobertura en profundidad del formación automotriz y las informativo sobre formación profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el notorio.