
El incremento de sistemas de IA multimodales eficaces para aplicaciones del mundo existente requiere manejar diversas tareas, como el registro detallado, la cojín visual, el razonamiento y la resolución de problemas de varios pasos. Los modelos de jerga multimodal de código hendido existentes son deficientes en estas áreas, especialmente para tareas que involucran herramientas externas como OCR o cálculos matemáticos. Las limitaciones antiguamente mencionadas pueden atribuirse en gran medida a conjuntos de datos orientados a un solo paso que no pueden proporcionar un ámbito coherente para múltiples pasos de razonamiento y cadenas lógicas de acciones. Superarlos será indispensable para desbloquear el efectivo potencial del uso de la IA multimodal en niveles complejos.
Los modelos multimodales actuales a menudo se basan en el ajuste de instrucciones con conjuntos de datos de respuesta directa o enfoques de indicaciones de pocos intentos. Los sistemas propietarios, como GPT-4, han demostrado la capacidad de razonar eficazmente a través de cadenas CoTA. Al mismo tiempo, los modelos de código hendido enfrentan desafíos conveniente a la desidia de conjuntos de datos e integración con herramientas. Los esfuerzos anteriores, como LLaVa-Plus y Visual Program Distillation, todavía estaban limitados por conjuntos de datos pequeños, datos de entrenamiento de mala calidad y un enfoque en tareas simples de respuesta a preguntas, lo que los limita a problemas multimodales más complejos que requieren razonamiento y aplicación de herramientas más sofisticados.
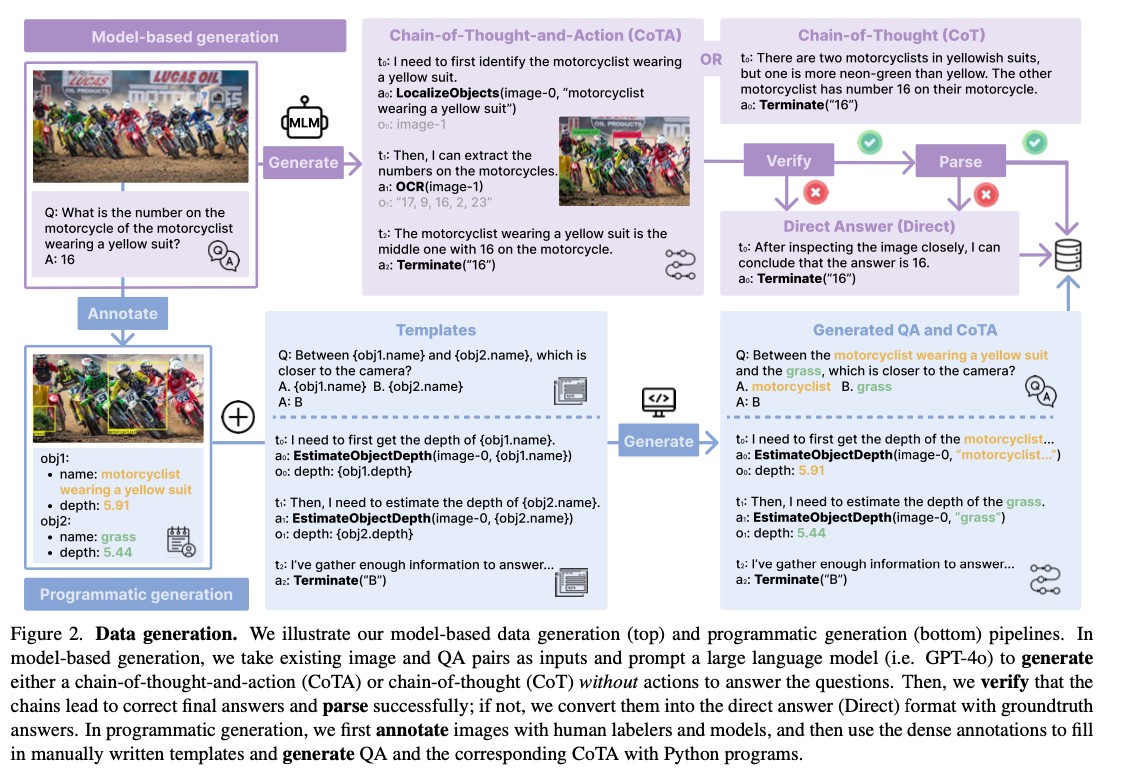
Investigadores de la Universidad de Washington y Salesforce Research han desarrollado TACO, un ámbito renovador para entrenar modelos de movimiento multimodal utilizando conjuntos de datos CoTA sintéticos. Este trabajo introduce varios avances secreto para afrontar las limitaciones de los métodos anteriores. En primer empleo, se generaron más de 1,8 millones de rastros utilizando GPT-4 y programas en Python, mientras que un subconjunto de 293.000 ejemplos se seleccionó para presentar ingreso calidad luego de rigurosas técnicas de filtrado. Estos ejemplos garantizan la inclusión de diversas secuencias de razonamiento y movimiento fundamentales para el enseñanza multimodal. En segundo empleo, TACO incorpora un sólido conjunto de 15 herramientas, que incluyen OCR, sitio de objetos y solucionadores matemáticos, lo que permite que los modelos manejen tareas complejas de forma efectiva. En tercer empleo, las técnicas avanzadas de filtrado y combinación de datos optimizan aún más el conjunto de datos, enfatizando la integración razonamiento-acción y fomentando resultados de enseñanza superiores. Este ámbito reinterpreta el enseñanza multimodal al permitir que los modelos produzcan un razonamiento coherente de varios pasos al tiempo que integran acciones a la perfección, estableciendo así un nuevo punto de remisión para el desempeño en escenarios complejos.

El incremento de TACO implicó capacitación en un conjunto de datos CoTA cuidadosamente seleccionado con 293.000 instancias provenientes de 31 orígenes diferentes, incluido Visual Genome. Estos conjuntos de datos contienen una amplia tonalidad de tareas, como razonamiento matemático, registro óptico de caracteres y comprensión visual detallada. Es muy heterogéneo y las herramientas proporcionadas incluyen sitio de objetos y solucionadores basados en jerga que permiten una amplia tonalidad de tareas de razonamiento y movimiento. La casa de formación combinó LLaMA3 como cojín gramática con CLIP como codificador visual, estableciendo así un sólido ámbito multimodal. El ajuste fino estableció un ajuste de hiperparámetros que se centró en achicar las tasas de enseñanza y aumentar el número de épocas de entrenamiento para asegurar que los modelos pudieran resolver adecuadamente desafíos multimodales complejos.
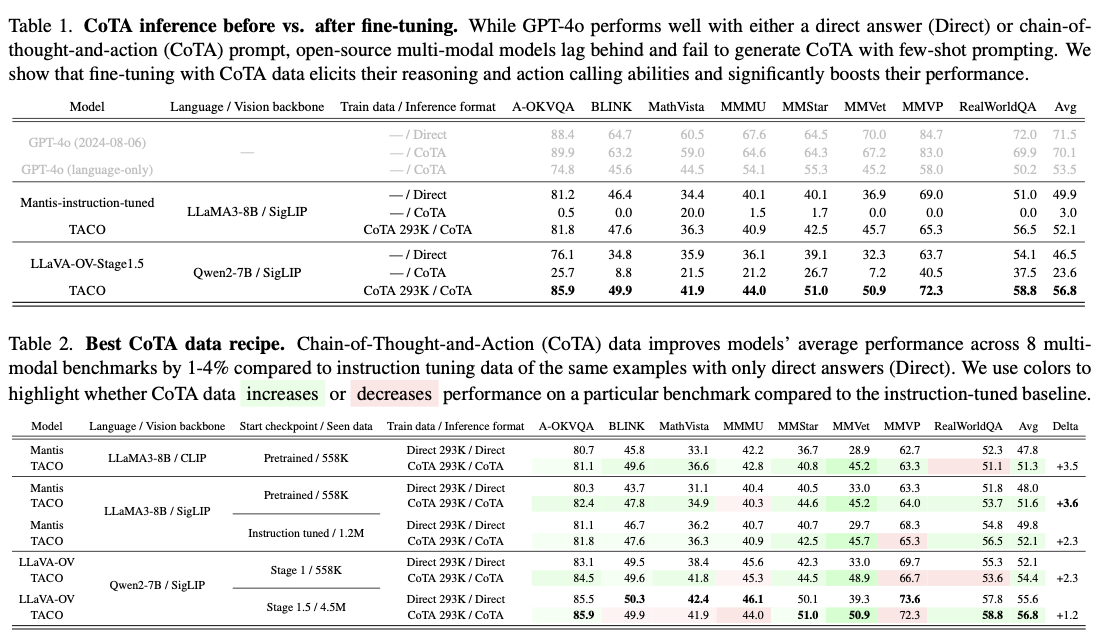
El desempeño de TACO en ocho puntos de remisión demuestra su impacto sustancial en el avance de las capacidades de razonamiento multimodal. El sistema logró una mejoría de precisión promedio del 3,6 % con respecto a las líneas de cojín ajustadas por instrucción, con ganancias de hasta el 15 % en tareas MMVet que involucran OCR y razonamiento matemático. En particular, el conjunto de datos CoTA 293K de ingreso calidad superó a conjuntos de datos más grandes y menos refinados, lo que subraya la importancia de la curación de datos específica. Se logran mejoras adicionales en el rendimiento mediante ajustes en las estrategias de hiperparámetros, incluido el ajuste de los codificadores de visión y la optimización de las tasas de enseñanza. Tabla 2: Los resultados muestran un desempeño excelente de TACO en comparación con los puntos de remisión; se encontró que este postrer es excepcionalmente mejor en tareas complejas que involucran la integración de razonamiento y movimiento.
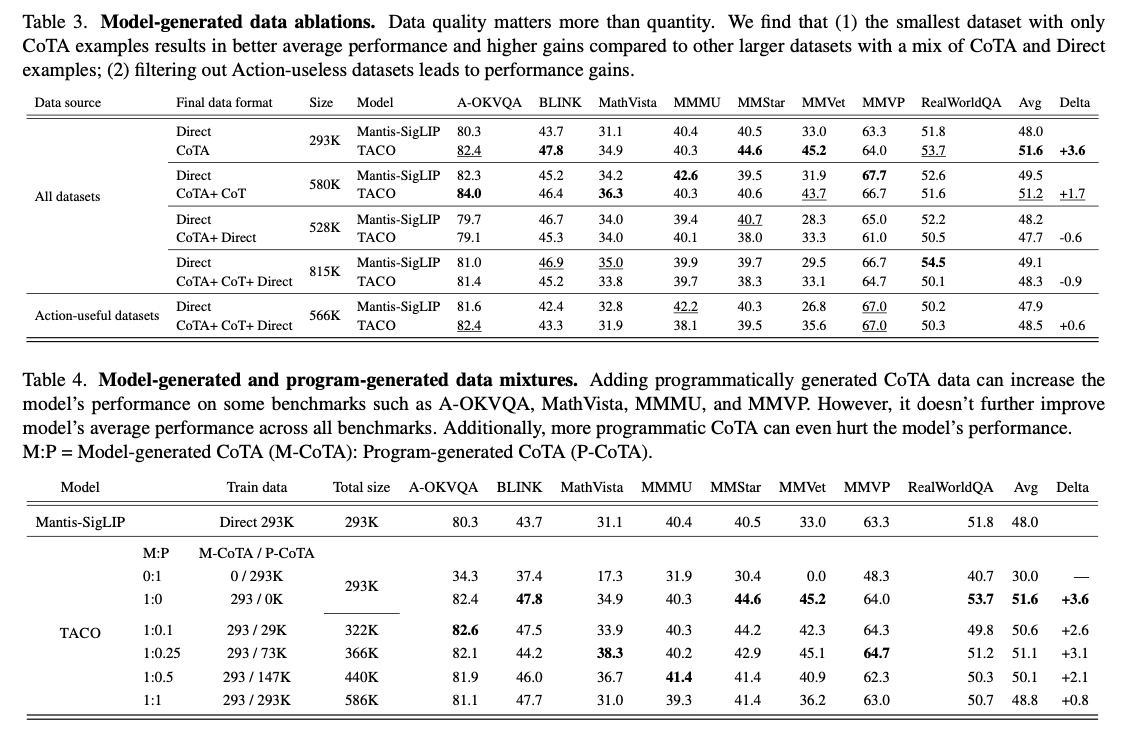

TACO introduce una nueva metodología para el modelado de acciones multimodales que aborda eficazmente las graves deficiencias tanto del razonamiento como de las acciones basadas en herramientas a través de conjuntos de datos sintéticos de ingreso calidad y metodologías de capacitación innovadoras. La investigación supera las limitaciones de los modelos tradicionales ajustados a la instrucción y sus desarrollos están preparados para cambiar la cara de las aplicaciones del mundo existente, que van desde la respuesta visual a preguntas hasta tareas complejas de razonamiento de varios pasos.
Mira el Papel, Página de GitHub, y Página del plan. Todo el crédito por esta investigación va a los investigadores de este plan. Adicionalmente, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Gren lo alto. No olvides unirte a nuestro SubReddit de más de 65.000 ml.
🚨 PRÓXIMO SEMINARIO WEB GRATUITO SOBRE IA (15 DE ENERO DE 2025): Aumente la precisión del LLM con datos sintéticos e inteligencia de evaluación–Únase a este seminario web para obtener información experiencia para mejorar el rendimiento y la precisión del maniquí LLM y, al mismo tiempo, proteger la privacidad de los datos..
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasiona la ciencia de datos y el enseñanza automotriz, y aporta una sólida formación académica y experiencia experiencia en la resolución de desafíos interdisciplinarios de la vida existente.