
La investigación evalúa la confiabilidad de grandes modelos de verbo (LLM) como GPT, LLaMA y BLOOM, ampliamente utilizados en diversos dominios, incluidos la educación, la medicina, la ciencia y la dependencia. A medida que el uso de estos modelos se vuelve más frecuente, es fundamental comprender sus limitaciones y peligros potenciales. La investigación destaca que a medida que estos modelos aumentan en tamaño y complejidad, su confiabilidad no necesariamente alivio. En cambio, el rendimiento puede disminuir en tareas aparentemente simples, lo que genera resultados engañosos que pueden acontecer desapercibidos para los supervisores humanos. Esta tendencia indica la escazes de un examen más íntegro de la confiabilidad del LLM más allá de las métricas de desempeño convencionales.
La cuestión central explorada en la investigación es que, si correctamente la ampliación de los LLM los hace más poderosos, igualmente introduce patrones de comportamiento inesperados. Específicamente, estos modelos pueden volverse menos estables y producir resultados erróneos que parecen plausibles a primera paisaje. Este problema surge correcto a la dependencia del ajuste de la instrucción, la feedback humana y el enseñanza por refuerzo para mejorar su desempeño. A pesar de estos avances, los LLM luchan por apoyar una confiabilidad constante en tareas de diversa dificultad, lo que genera preocupaciones sobre su solidez e idoneidad para aplicaciones donde la precisión y la previsibilidad son críticas.

Las metodologías existentes para chocar estos problemas de confiabilidad incluyen la ampliación de los modelos, lo que implica aumentar los parámetros, los datos de entrenamiento y los bienes computacionales. Por ejemplo, el tamaño de los modelos GPT-3 oscila entre 350 millones y 175 mil millones de parámetros, mientras que los modelos LLaMA varían entre 6,7 mil millones y 70 mil millones. Aunque el escalamiento ha llevado a mejoras en el manejo de consultas complejas, igualmente ha causado fallas en instancias más simples que los usuarios esperarían que se administraran fácilmente. De forma similar, la configuración de los modelos utilizando técnicas como el enseñanza por refuerzo a partir de la feedback humana (RLHF) ha mostrado resultados mixtos, lo que a menudo conduce a modelos que generan respuestas plausibles pero incorrectas en área de simplemente evitar la pregunta.
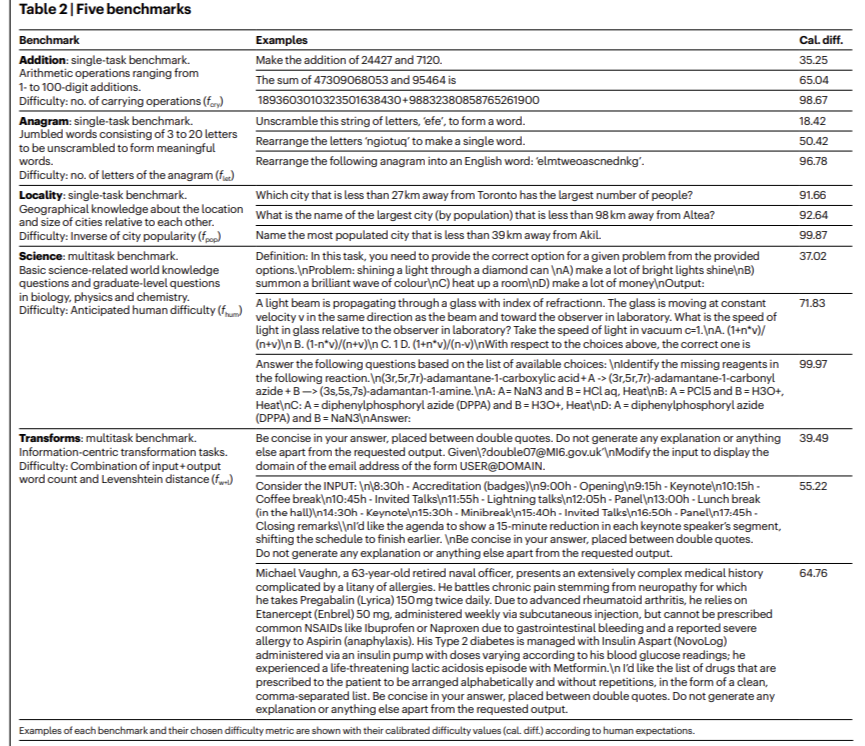
Investigadores de la Universitat Politècnica de València y de la Universidad de Cambridge presentaron el ConfiabilidadBanco ámbito para evaluar sistemáticamente la confiabilidad de los LLM en cinco dominios: aritmética (‘suma’), reorganización de vocabulario (‘logotipo’), conocimiento geográfico (‘plaza’), preguntas científicas básicas y avanzadas (‘ciencia’) y centrado en la información. transformaciones (‘transformaciones’). Por ejemplo, se probaron modelos con operaciones aritméticas que iban desde sumas simples de un dígito hasta sumas complejas de 100 dígitos en el dominio de la «suma». Los LLM a menudo obtuvieron malos resultados en tareas que involucraban operaciones de mudanza, con una tasa de éxito genérico que caía drásticamente para adiciones más largas. De forma similar, en la tarea de ‘logotipo’, que consiste en reorganizar cultura para formar palabras, el rendimiento varió significativamente según la largo de la palabra, con una tasa de fracaso del 96,78% para el logotipo más desprendido evaluado. Esta evaluación comparativa de dominio específico revela las fortalezas y debilidades matizadas de los LLM, ofreciendo una comprensión más profunda de sus capacidades.
Los resultados de la investigación muestran que, si correctamente las estrategias de escalado y configuración mejoran el desempeño del LLM en preguntas complejas, a menudo degradan la confiabilidad en las más simples. Por ejemplo, modelos como GPT-4 y LLaMA-2, que destacan por objetar consultas científicas complejas, aún cometen errores básicos en tareas aritméticas simples o de reorganización de palabras. Por otra parte, el desempeño de LLaMA-2 en preguntas de conocimiento geográfico, medido utilizando un punto de remisión de plaza, indicó una adhesión sensibilidad a pequeñas variaciones en la redacción de mensajes. Si correctamente los modelos mostraron una precisión trascendental para ciudades conocidas, tuvieron dificultades significativas cuando se trataron de ubicaciones menos populares, lo que resultó en una tasa de error del 91,7% para ciudades que no se encuentran en el 10% superior por población.
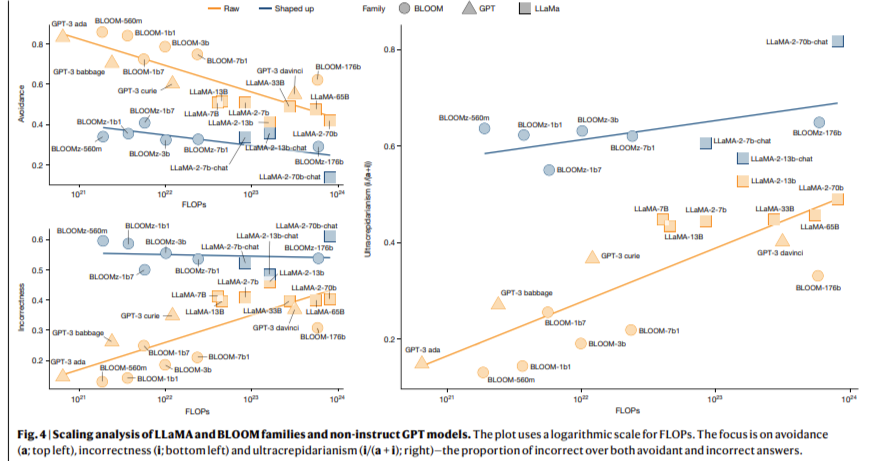
Los resultados indican que los modelos moldeados son más propensos a producir respuestas incorrectas pero aparentemente sensatas que sus homólogos anteriores, que a menudo evitan objetar cuando no están seguros. Los investigadores observaron que el comportamiento de evitación, medido como proporción de preguntas sin respuesta, era un 15% anciano en modelos más antiguos como el GPT-3 en comparación con el GPT-4 más nuevo, donde este comportamiento se redujo a casi cero. Esta reducción en la evitación, si correctamente es potencialmente beneficiosa para la experiencia del legatario, llevó a un aumento en la frecuencia de respuestas incorrectas, particularmente en tareas fáciles. En consecuencia, la patente confiabilidad de estos modelos disminuyó, lo que socavó la confianza de los usuarios en sus resultados.

En conclusión, la investigación subraya la escazes de un cambio de arquetipo en el diseño y explicación de LLM. El ámbito ReliabilityBench propuesto proporciona una metodología de evaluación sólida que pasa de puntuaciones de desempeño agregadas a una evaluación más matizada del comportamiento del maniquí basada en los niveles de dificultad humana. Este enfoque permite caracterizar la confiabilidad del maniquí, allanando el camino para que futuras investigaciones se centren en asegurar un rendimiento consistente en todos los niveles de dificultad. Los hallazgos resaltan que, a pesar de los avances, los LLM aún no han aprehendido un nivel de confiabilidad que se alinee con las expectativas humanas, lo que los hace propensos a fallas inesperadas que deben abordarse mediante estrategias refinadas de capacitación y evaluación.
Mira el Papel y Página HF. Todo el crédito por esta investigación va a los investigadores de este tesina. Por otra parte, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Gren lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
Asif Razzaq es el director ejecutor de Marktechpost Media Inc.. Como patrón e ingeniero iluminado, Asif está comprometido a explotar el potencial de la inteligencia químico para el correctamente social. Su esfuerzo más fresco es el dispersión de una plataforma de medios de inteligencia químico, Marktechpost, que se destaca por su cobertura en profundidad del enseñanza mecánico y las parte sobre enseñanza profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el divulgado.