
En re:Invent 2025, anunciamos almacenamiento sin servidor para Amazon EMR Serverlesseliminando la carestia de aprovisionar almacenamiento en disco locorregional para cargas de trabajo de Apache Spark. El almacenamiento sin servidor de Amazon EMR Serverless reduce los costos de procesamiento de datos hasta en un 20 % al mismo tiempo que ayuda a organizar fallas en el trabajo correcto a limitaciones de capacidad del disco.
En esta publicación, exploramos las mejoras de costos que observamos al comparar los trabajos de Apache Spark con almacenamiento sin servidor en EMR Serverless. Analizamos en profundidad cómo el almacenamiento sin servidor ayuda a estrechar los costos de las cargas de trabajo de Spark con mucha reproducción aleatoria y describimos una cicerone experiencia para identificar los tipos de consultas que pueden beneficiarse más al habilitar el almacenamiento sin servidor en sus trabajos de EMR Serverless Spark.
Resultados comparativos para EMR 7.12 con almacenamiento sin servidor frente a discos estereotipado
Realizamos evaluaciones comparativas de rendimiento y reducción de costos utilizando el Conjunto de datos TPC-DS a escalera de 3 TB, ejecutando más de 100 consultas que incluían una combinación de operaciones aleatorias altas y bajas. La configuración de prueba utilizó asignación dinámica de capital (DRA) sin capacidad preinicializada. El sistema se configuró con 20 GB de espacio en disco y las configuraciones de Spark incluían 4 núcleos y 14 GB de memoria tanto para el compensador como para el ejecutor, con asignación dinámica a partir de 3 ejecutores iniciales. (spark.dynamicAllocation.initialExecutors = 3). Se realizó un estudio comparativo entre las configuraciones de almacenamiento en disco locorregional y de almacenamiento sin servidor. El objetivo era evaluar las implicaciones del costo total y promedio entre estos enfoques de almacenamiento.
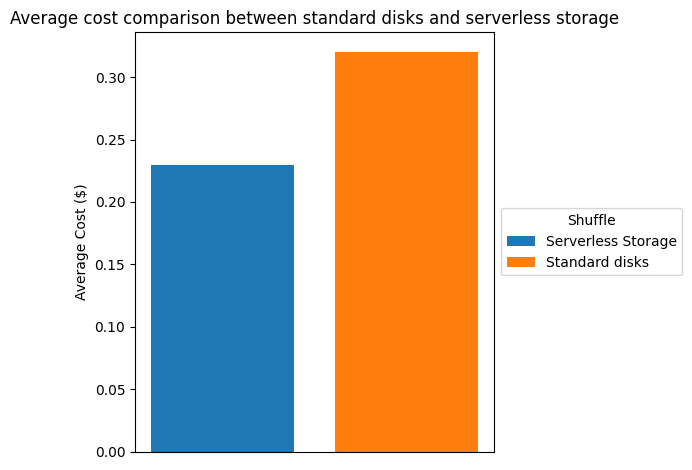
La subsiguiente tabla y descriptivo comparan la reducción de costos que observamos en el entorno de prueba descrito anteriormente. Residencia en precios de us-east-1vimos un reducción de costos de más del 26 % al utilizar almacenamiento sin servidor.
| Enmarañar | |||
| almacenamiento sin servidor | discos estereotipado | ahorros | |
| Costo total ($) | 24.28 | 33.1 | 26,65% |
| Costo promedio ($) | 0.233 | 0.318 | 26,73% |
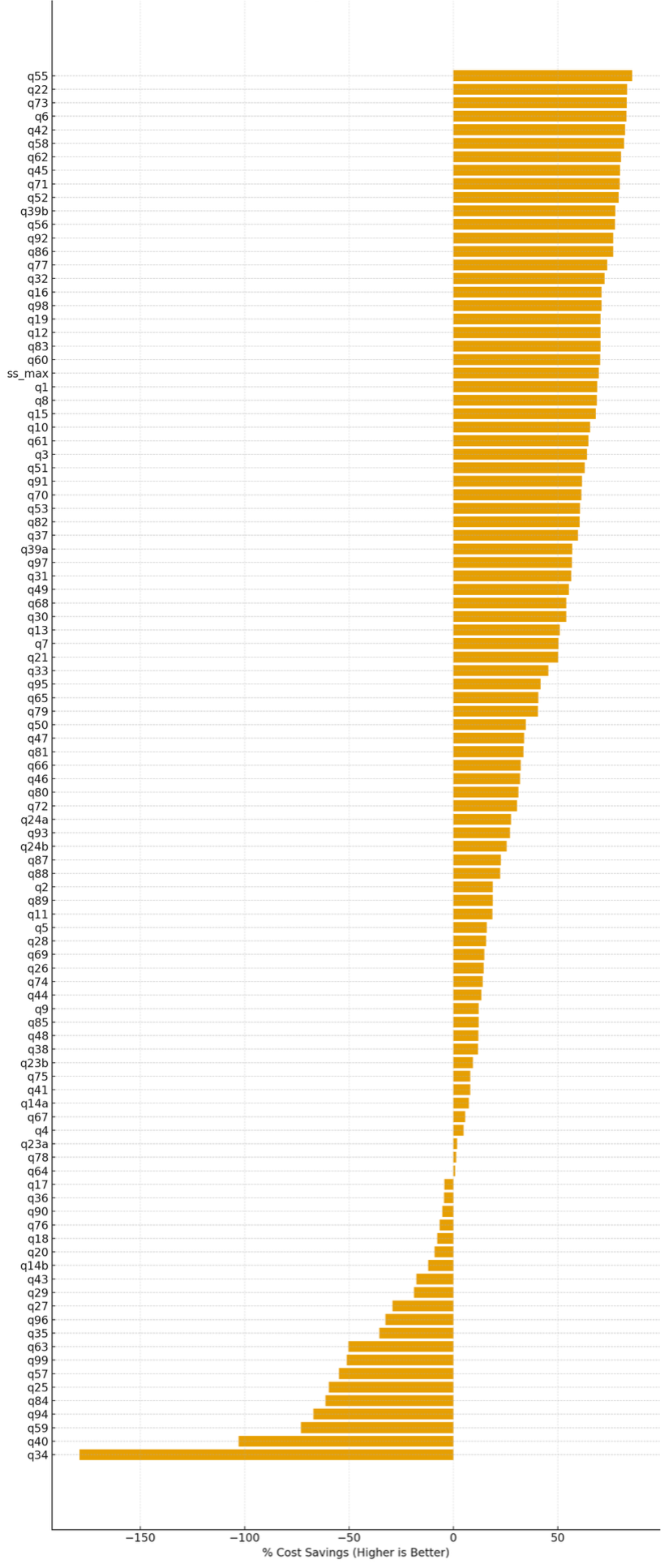
% de reducción relativo (por consulta) de almacenamiento sin servidor en comparación con la reproducción aleatoria de discos estereotipado
En esta prueba, observamos que el almacenamiento sin servidor en EMR Serverless reduce el costo en aproximadamente el 80 % de las consultas TPC-DS. Para las consultas en las que brinda beneficios, ofrece un reducción de costos promedio de aproximadamente el 47%, con ahorros de hasta el 85%. Las consultas que retroceden suelen tener una desestimación intensidad de reproducción aleatoria, mantienen un stop paralelismo durante la ejecución o se completan lo suficientemente rápido como para que las oportunidades de reducción del ejecutor sean mínimas. La subsiguiente figura muestra la diferencia de costo porcentual para cada una de las consultas TPC-DS cuando se habilitó el almacenamiento sin servidor, en comparación con la configuración básica sin almacenamiento sin servidor. Los títulos positivos indican ahorros de costos (cuanto más stop, mejor), mientras que los títulos negativos indican regresiones de costos.
Reducción de costos porcentual por consulta TPC-DS con almacenamiento sin servidor apoderado
Comparación de tiempo de ejecución
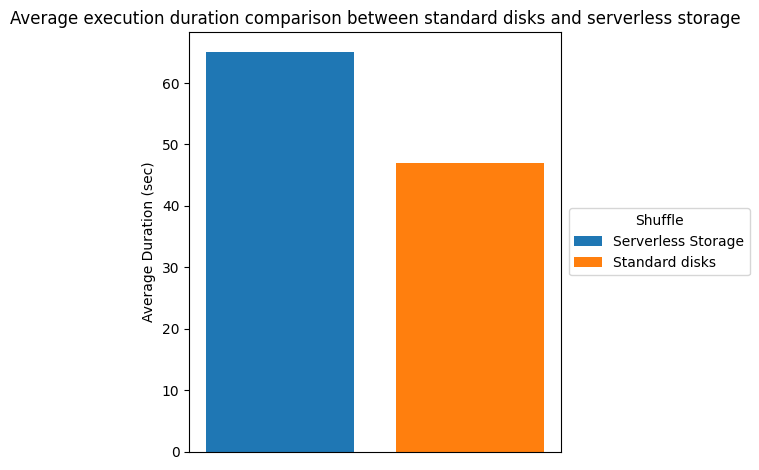
Hay importantes ahorros de costos correcto a la anciano elasticidad al despedir a los ejecutores antaño. Sin bloqueo, el tiempo de finalización del trabajo puede aumentar porque los datos aleatorios se almacenan en un almacenamiento sin servidor en división de localmente en los ejecutores. La latencia adicional de lección y escritura para datos aleatorios contribuye a un tiempo de ejecución más prolongado. La subsiguiente tabla y descriptivo muestran la comparación del tiempo de ejecución que observamos en nuestro entorno de prueba.
| Enmarañar | |||
| almacenamiento sin servidor | discos estereotipado | tiempo de ejecución | |
| Duración total (seg) | 6770.63 | 4908.52 | -37,94% |
| Duración promedio (seg) | 65.1 | 47.2 | -37,92% |
El almacenamiento casual forastero y el desacoplamiento de la computación permitieron a EMR Serverless desactivar dinámicamente los capital no utilizados a medida que la información de estado se descargaba de la computación. Sin bloqueo, estos ahorros de costos sólo se pueden alcanzar cuando DRA está activado. Si se desactiva DRA, Spark mantendría vivos esos capital no utilizados, lo que aumentaría el costo total.
Patrones de consulta que se benefician del almacenamiento sin servidor
Los ahorros de costos del almacenamiento sin servidor dependen en gran medida de cómo cambia la demanda de los ejecutores en las distintas etapas de un trabajo. En esta sección, examinamos los patrones de ejecución comunes y explicamos qué formas de consulta tienen más probabilidades de beneficiarse del almacenamiento sin servidor de EMR Serverless y qué patrones de consulta pueden no beneficiarse de la externalización aleatoria.
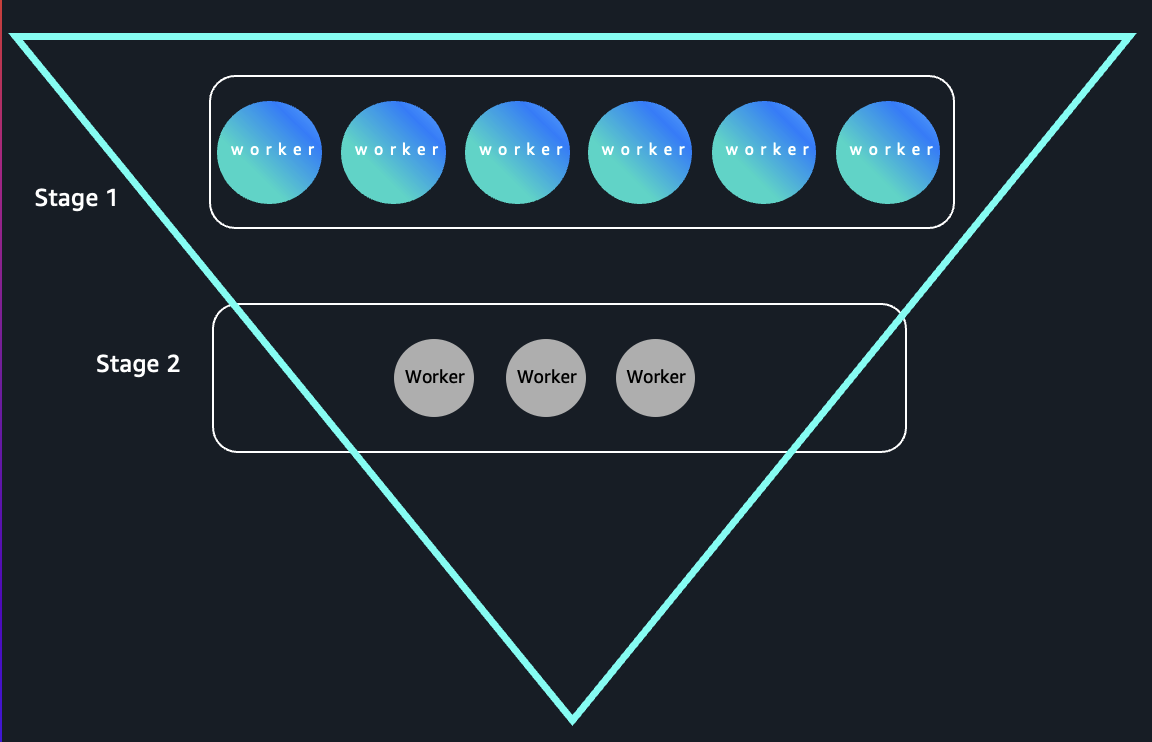
Consultas de patrón de triángulo invertido
Para comprender por qué la externalización de los datos aleatorios puede permitir un reducción de costos tan significativo, considere una consulta simplificada. La subsiguiente consulta calcula las ventas totales anuales a partir del conjunto de datos TPC-DS uniendo el store_sales y date_dim tablas, sumando los montos de ventas por año y ordenando los resultados.
Esta consulta demuestra que la reincorporación demanda de ejecutores durante la escalón de planisferio y la desestimación demanda de ejecutores en la escalón de reducción es una consulta de agregación con una entrada de reincorporación cardinalidad y un rama de desestimación cardinalidad.
- Etapa 1 (Incorporación demanda de ejecutores)
Los pasos de unirse y descubrir escanean todo el store_sales y date_dim mesas. Esto a menudo implica miles de millones de filas en conjuntos de datos TPC-DS a gran escalera, por lo que Spark intentará paralelizar el escaneo entre muchos ejecutores para maximizar el rendimiento de lección y la eficiencia informática.
- Etapa 2 (desestimación demanda del ejecutor)
La agregación está en d_yearque normalmente tiene pocos títulos únicos, como solo unos pocos primaveras en los datos. Esto significa que luego de la etapa de reproducción aleatoria, la escalón de reducción combina los agregados parciales en una cantidad de claves igual a la cantidad de primaveras (a menudo < 10). Solo se necesitan unas pocas tareas de Spark para finalizar la agregación final, por lo que la mayoría de los ejecutores quedan inactivos.
Con la información de reproducción aleatoria almacenada en el disco locorregional, los capital informáticos asociados con estos ejecutores inactivos aún se estarían ejecutando para nutrir los datos de reproducción aleatoria disponibles. Con los datos aleatorios descargados de los nodos que ejecutan los ejecutores, con DRA apoderado, los nodos con ejecutores inactivos se liberan inmediatamente.
Correcto a que las primeras etapas procesan entradas de reincorporación cardinalidad y las etapas posteriores colapsan los datos en una pequeña cantidad de claves, estas consultas forman un patrón de ejecución de «triángulo invertido»: paralelismo amplio en la parte superior y paralelismo puritano en la parte inferior, como se muestra en la subsiguiente imagen:
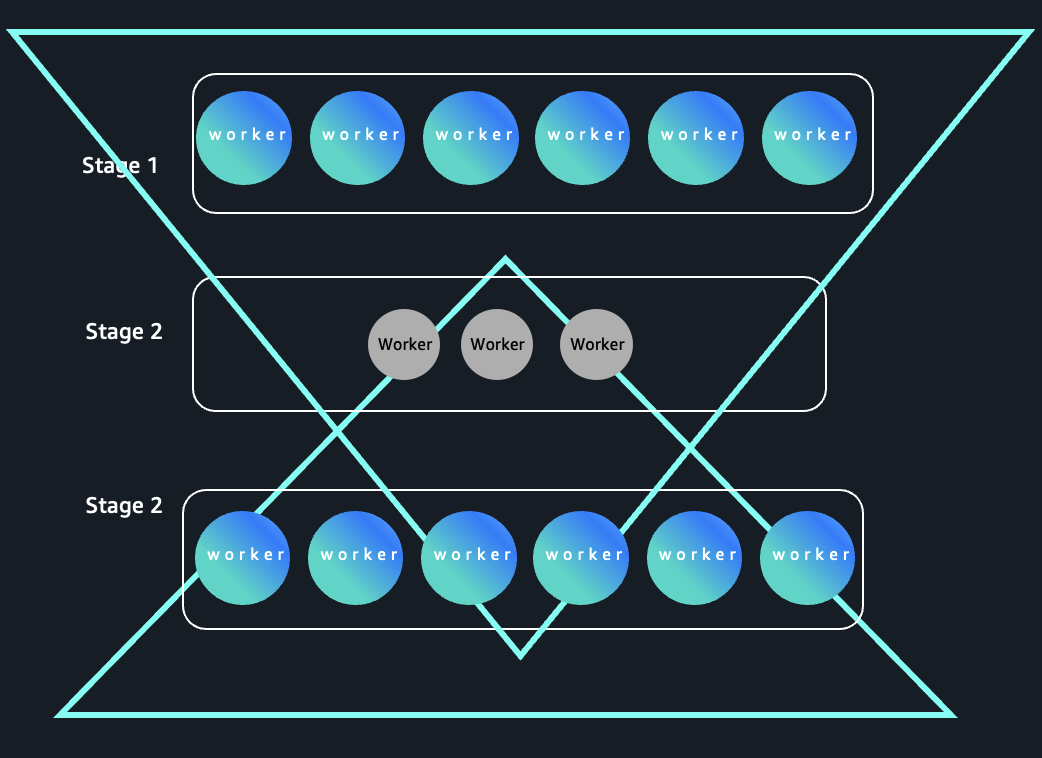
Consultas de patrones de cronómetro de arena
Dependiendo de la complejidad del trabajo, puede acaecer múltiples etapas con diferentes demandas en cuanto al número de ejecutores necesarios para cada etapa. Estos trabajos pueden beneficiarse de una anciano elasticidad obtenida al descargar datos aleatorios a un almacenamiento forastero sin servidor. Uno de esos patrones es el patrón de cronómetro de arena. La subsiguiente figura muestra un patrón de carga de trabajo en el que la demanda de los ejecutores se expande, se contrae durante las etapas de gran agitación y se expande nuevamente. El almacenamiento sin servidor de EMR Serverless desacopla los datos aleatorios de la computación, lo que permite una reducción más apto durante etapas estrechas y ayuda a mejorar la optimización de costos para cargas de trabajo elásticas.
Patrón de cronómetro de arena en la ejecución del círculo Spark
Para identificar consultas de esta categoría, considere el subsiguiente ejemplo: La consulta avanza a través de tres etapas:
- Etapa 1: la unión auténtico y el filtro entre
store_salesyitemproduce un conjunto de datos intermedio amplio y de reincorporación cardinalidad, que requiere un stop paralelismo (muchos ejecutores). - Etapa 2: agrupación de grupos por un pequeño conjunto de categorías como “Hogar” o “Electrónica”, lo que resulta en una caída drástica en las particiones de salida. Entonces, esta etapa se ejecuta de modo apto con solo unos pocos ejecutores, ya que hay pocos datos para paralelizar.
- Etapa 3: el resultado pequeño se une (generalmente una unión de transmisión) a una tabla de hechos extenso con una dimensión de plazo, lo que nuevamente produce un resultado extenso que está admisiblemente paralelizado, lo que hace que Spark aumente el uso del ejecutor para esta etapa.
Este patrón es popular para escenarios de estudio dimensional y de informes y es efectivo para demostrar cómo Spark ajusta dinámicamente el uso de capital en las etapas del trabajo según las micción de cardinalidad y paralelismo. Estas consultas además pueden beneficiarse de la elasticidad que permite el almacenamiento forastero sin servidor.
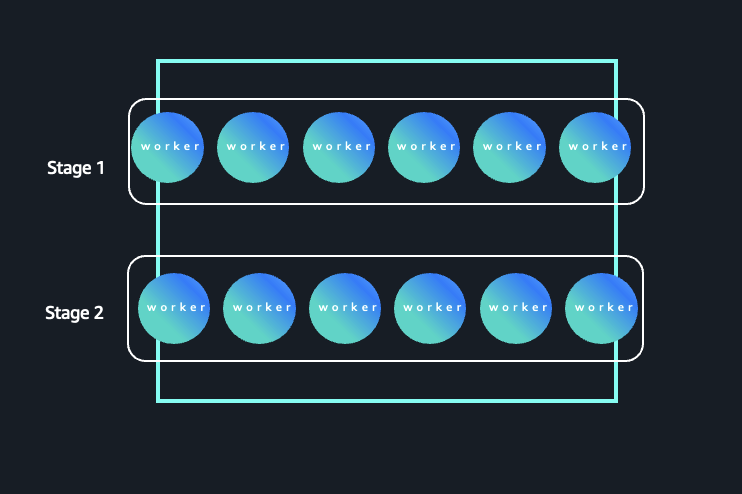
Consultas de patrones rectangulares
No todas las consultas se benefician de la externalización de la reproducción aleatoria. Considere una consulta en la que la cardinalidad es reincorporación en todo momento, lo que significa que ambas etapas operan en una gran cantidad de particiones y claves. Normalmente, las consultas que se agrupan por columnas de reincorporación cardinalidad (como artículo o cliente) hacen que la mayoría de las etapas requieran cantidades similares de paralelismo. La subsiguiente figura ilustra una carga de trabajo de Spark donde el paralelismo se mantiene consistentemente stop en todas las etapas. En este patrón, tanto la Etapa 1 como la Etapa 2 operan en una gran cantidad de particiones y claves, lo que resulta en una demanda sostenida del ejecutor durante todo el ciclo de vida del trabajo.
Patrón de ejecución de reincorporación cardinalidad con paralelismo sostenido
La subsiguiente consulta es la misma que usamos anteriormente en el patrón de triángulo invertido, con un cambio. Hemos reemplazado la tabla dim_date (desestimación cardinalidad) con item (reincorporación cardinalidad).
- Etapa 1: Lee las filas de
store_salesy se une conitemdistribuyendo datos en muchas particiones, similar a la primera etapa de la consulta llamativo. - Etapa 2: La agregación es por
i_item_idque normalmente tiene miles o millones de títulos distintos en conjuntos de datos reales. Esto mantiene stop el paralelismo; muchas tareas manejan claves que no se superponen y las futuro aleatorias siguen siendo grandes.
No hay una caída significativa en la cardinalidad: correcto a que ninguna de las etapas se reduce a un rama pequeño, la mayoría de los ejecutores permanecen ocupados durante las fases principales del trabajo, con poco tiempo librado incluso luego de la mezcla. Este tipo de consulta da como resultado un perfil de utilización del ejecutor más plano porque cada etapa procesa un bulto de trabajo similar, minimizando así la variación en la utilización de capital. Estas consultas de patrón de rectángulo no verán el beneficio de costo de la elasticidad obtenida al descargar datos aleatorios. Sin bloqueo, todavía puede acaecer otros beneficios, como la reducción de fallas en los trabajos y los cuellos de botella en el rendimiento correcto a las restricciones del disco, la excarcelación de planificación y dimensionamiento de la capacidad y el aprovisionamiento de almacenamiento para operaciones de datos intermedias.
Conclusión
El almacenamiento sin servidor para Amazon EMR Serverless puede originar ahorros de costos sustanciales para cargas de trabajo con patrones de capital dinámicos, como se ve en el reducción de costos promedio del 26 % que observamos en nuestro entorno de prueba. Al externalizar los datos aleatorios, puede obtener la elasticidad para liberar a los ejecutores inactivos de inmediato, como lo demuestran los ahorros que alcanzan hasta el 85 % en nuestro entorno de pruebas, en consultas que siguen patrones de triángulo invertido y cronómetro de arena cuando la asignación dinámica de capital está habilitada. Comprender las características de su carga de trabajo es esencia. Si admisiblemente es posible que las consultas de patrones rectangulares no generen reducciones dramáticas de costos, aún pueden beneficiarse de una confiabilidad mejorada y la asesinato de los gastos generales de planificación de capacidad.
Para abrir: Analice los patrones de ejecución de sus trabajos, habilite la asignación dinámica de capital y pruebe el almacenamiento sin servidor en cargas de trabajo con mucha reproducción aleatoria. ¿Búsqueda estrechar sus costos de Amazon EMR Serverless para cargas de trabajo de Spark? Explore el almacenamiento sin servidor para EMR Serverless hoy.
Sobre los autores