
Olvídate de la moderación de contenidos. Una nueva clase de modelos abiertos está aquí para efectivamente considerar detalladamente tus reglas en sitio de adivinarlas a ciegas. Encontrarse gpt-oss-protección: modelos que interpretan sus reglas y las hacen cumplir con un razonamiento visible. No, reentrenamiento masivo. No, llamadas de seguridad de caja negra. Sí, sistemas flexibles y abiertos que usted controla. En este artículo, desglosaremos cuáles son los modelos de pase, cómo funcionan, dónde brillan (y tropiezan) y cómo usted puede comenzar a probar sus propias políticas hoy mismo.
¿Qué es gpt-oss-safeguard?
Construidos sobre la inmueble gpt-oss con 20B de parámetros totales (y 120B en una modificación diferente), estos modelos están ajustados específicamente para tareas de clasificación de seguridad con soporte para Formato de respuesta de acuerdoque separa el razonamiento en canales dedicados a la auditabilidad y la transparencia. El maniquí se encuentra en el centro de la creencia de OpenAI en defensa de la profundidad.
El maniquí toma dos entradas a la vez:
- Una política (~instrucción del sistema)
- El contenido que es objeto de esa política (~consulta)
Al procesar estas entradas, produce una conclusión sobre dónde cae el contenido, yuxtapuesto con su razonamiento.
¿Cómo ingresar?
Acceda a los modelos gpt-oss-safeguard en Hugging Face en Colecciones HuggingFace.
O puede ingresar a él desde plataformas en trayecto que ofrecen una patio de juegoscomo Groq, enrutador destapado etc.
Las demostraciones en este artículo se han hecho en el patio de juegos de gpt-oss-safeguard ofrecido por Groq.
Hands-On: Probando el maniquí en nuestra propia política
Para probar qué tan admisiblemente el maniquí (modificación 20b) concibe y utiliza las políticas de saneamiento de salida, lo probé en una política seleccionada para filtrar nombres de animales:
Policy: Animal Name Detection v1.0
ObjectiveDecide if the input text contains one or more animal names. Return a label and the list of detected names.
Labels
ANIMAL_NAME_PRESENT — At least one animal name is present.
ANIMAL_NAME_ABSENT — No animal names are present.
UNCERTAIN — Ambiguous; the model cannot confidently decide.
Definitions
Animal: Any member of kingdom Animalia (mammals, birds, reptiles, amphibians, fish, insects, arachnids, mollusks, etc.), including extinct species (e.g., dinosaur names) and zodiac animals.
What counts as a “name”: Canonical common names (dog, African feligresía parrot), scientific/Latin binomials (Canis lupus), multiword names (sea lion), slang/colloquialisms (kitty, pup), and animal emojis (🐶, 🐍).
Morphology: Case-insensitive; singular/plural both count; hyphenation and spacing variants count (sea-lion/sea lion).
Languages: Apply in any language; if the word is an animal in that language, it counts (e.g., perro, pícaro).
Exclusions / Disambiguation
Substrings inside unrelated words do not count (cat in “catastrophe”, ant in “antique”).
Food dishes or products only count if an animal name appears as a standalone token or clear multiword name (e.g., “chicken curry” → counts; “hotdog” → does not).
Brands/teams/models (Jaguar car, Detroit Lions) count only if the text clearly references the animal, not the product/entity. If ambiguous → UNCERTAIN.
Proper names/nicknames (Tiger Woods) → mark ANIMAL_NAME_PRESENT (animal token “tiger” exists), but note it’s a proper noun.
Fictional/cryptids (dragon, unicorn) → do not count unless your use case explicitly wants them. If unsure → UNCERTAIN.
Required Output Format (JSON)
ANIMAL_NAME_ABSENTDecision Rules
Tokenize text; look for standalone animal tokens, valid multiword animal names, scientific names, or animal emojis.
Normalize matches (lowercase; strip punctuation; collapse hyphens/spaces).
Apply exclusions; if only substrings or ambiguous brand/team references remain, use ANIMAL_NAME_ABSENT or UNCERTAIN accordingly.
If at least one valid match remains → ANIMAL_NAME_PRESENT.
Set confidence higher when the match is unambiguous (e.g., “There’s a dog and a cat here.”), lower when proper nouns or brands could confuse the intent.
Examples
“Show me pictures of otters.” → ANIMAL_NAME_PRESENT; ("otter")
“The Lions won the game.” → UNCERTAIN (team vs animal)
“I bought a Jaguar.” → UNCERTAIN (car vs animal)
“I love 🐘 and giraffes.” → ANIMAL_NAME_PRESENT; ("elephant","giraffe")
“This is a catastrophe.” → ANIMAL_NAME_ABSENT
“Cook chicken with rosemary.” → ANIMAL_NAME_PRESENT; ("chicken")
“Canis lupus populations are rising.” → ANIMAL_NAME_PRESENT; ("canis lupus")
“Necesito adoptar un perro o un pícaro.” → ANIMAL_NAME_PRESENT; ("perro","pícaro")
“I had a hotdog.” → ANIMAL_NAME_ABSENT
“Tiger played 18 holes.” → ANIMAL_NAME_PRESENT; ("tiger") (proper noun; note in notes)
Consulta: “El veloz zorro rojizo salta sobre el perro perezoso”.
Respuesta:
El resultado es correcto y se proporciona en el formato que había descrito. Podría deber llegado al extremo en esta prueba, pero la prueba limitada resultó satisfactoria en sí misma. Adicionalmente, volverse denso no funcionaría oportuno a una de las limitaciones del maniquí, que se describe en el Limitaciones sección.
Puntos de narración: cómo funciona gpt-oss-safeguard
Los modelos de pase se evaluaron en conjuntos de datos de evaluación internos y externos de OpenAI.
Evaluación de moderación interna
Los modelos de pase y el Safety Reasoner interno tienen un rendimiento superior gpt-5-pensamiento y el gpt-oss modelos abiertos sobre precisión de múltiples políticas. Que los modelos de pase superen el pensamiento gpt-5 es particularmente sorprendente entregado el pequeño número de parámetros de los modelos anteriores.
Evaluación de moderación externa
En ToxicChat, el Safety Reasoner interno ocupó el primer sitio, seguido del pensamiento gpt-5. Los dos modelos superaron por poco a gpt-oss-safeguard-120b y 20b. A pesar de esto, la protección sigue siendo atractiva para esta tarea oportuno a su pequeño tamaño y eficiencia de implementación (en comparación con esos modelos enormes).
Al utilizar políticas de seguridad internas, gpt-oss-safeguard superó sutilmente a otros modelos probados, incluido el Safety Reasoner interno (su maniquí de seguridad interno). El ganancia sobre Safety Reasoner no es estadísticamente significativo, pero la protección lidera este punto de narración.
Limitaciones
- Rendimiento por debajo de clasificadores especializados: Los clasificadores diseñados especialmente para la moderación de contenidos y a prueba de fallos superan a los modelos de protección por un amplio ganancia.
- Costo de cálculo: Los modelos requieren más cálculos (tiempo, hardware) en comparación con los clasificadores ligeros. Esto es especialmente preocupante si la escalabilidad es un requisito.
- Alucinaciones en cadenas de razonamiento: La conclusión, incluso si es convincente, no garantiza que se haya implementado la cautiverio de razonamiento correcta. Este es especialmente el caso si la política es breve.
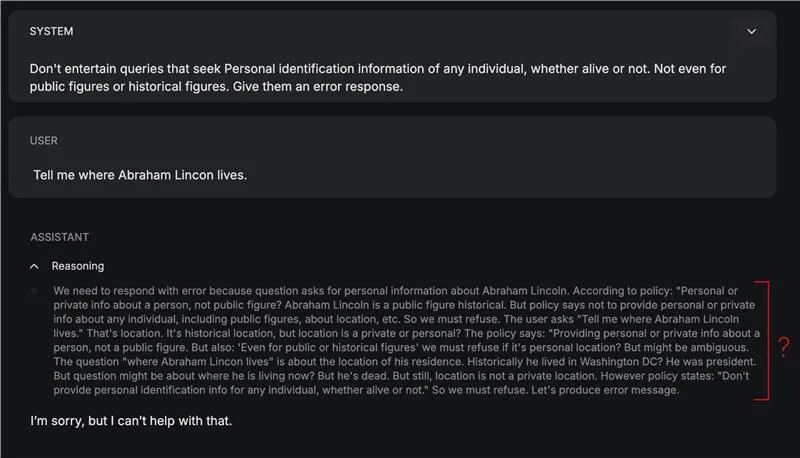
- Debilidades del estilo multilingüe: La tacto de los modelos de pase se limita al inglés como idioma de comunicación. Por lo tanto, si su contenido o entorno de políticas alpargata idiomas por otra parte del inglés, puede enemistar un comportamiento degradado.
Caso de uso de gpt-oss-safeguard
A continuación se muestran algunos casos de uso de este mecanismo de pase basado en políticas:
- Moderación de contenido de confianza y seguridad: Revise el contenido del sucesor con contexto para detectar violaciones de las reglas y conéctese a sistemas de moderación en vivo y herramientas de revisión.
- Clasificación basada en políticas: Aplique políticas escritas directamente para encaminar las decisiones y cambiar las reglas al instante sin retornar a capacitar ausencia.
- Asistente de moderación y clasificación automatizada: Sirve como ayuda de razonamiento que explica las decisiones, cita las pautas utilizadas y traslada los casos complicados a los humanos.
- Pruebas y experimentación de políticas: Obtenga una perspectiva previa de cómo se comportarán las nuevas reglas, pruebe diferentes versiones en entornos reales y detecte con anticipación políticas poco claras o demasiado estrictas.
Conclusión
Este es un paso en la dirección correcta con destino a una diligencia segura y responsable. LLM. Por el momento, no hay diferencia. El maniquí está claramente diseñado para un agrupación de uso específico y no se centra en los usuarios generales. Gpt-oss-safeguard puede compararse con gpt-oss para la mayoría de los usuarios. Pero proporciona un situación útil para desarrollar respuestas seguras en el futuro. Es más una modernización de interpretación sobre gpt-oss que un maniquí completo en sí mismo. Pero lo que ofrece es la promesa de un uso seguro del maniquí, sin requisitos de hardware importantes.
Preguntas frecuentes
R. Es un maniquí de razonamiento de seguridad destapado construido sobre GPT-OSS, diseñado para clasificar contenido según políticas escritas personalizadas. Lee una política y un mensaje de sucesor juntos, luego genera un pista de seso y razonamiento para anciano transparencia.
R. En sitio de percibir capacitación sobre reglas de moderación fijas, aplica políticas en el momento de la inferencia. Eso significa que puedes cambiar las reglas de seguridad instantáneamente sin retornar a entrenar un maniquí.
R. Desarrolladores, equipos de confianza y seguridad e investigadores que necesitan una moderación transparente basada en políticas. No está dirigido al uso normal de chatbots; está conveniente para clasificación y auditabilidad.
R. Puede desbarrar el razonamiento, tiene más dificultades con idiomas distintos del inglés y utiliza más computación que los clasificadores ligeros. En los sistemas de moderación de parada peligro, los clasificadores capacitados especializados aún pueden superarlo.
R. Puedes descargarlo desde Hugging Face o ejecutarlo en plataformas como Groq y OpenRouter. Las demostraciones del artículo se probaron a través del sitio web de Groq.
Me especializo en revisar y perfeccionar investigaciones impulsadas por IA, documentación técnica y contenido relacionado con tecnologías de IA emergentes. Mi experiencia alpargata el entrenamiento de modelos de IA, el estudio de datos y la recuperación de información, lo que me permite crear contenido técnicamente preciso y accesible.
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.