
Luego de mostrar una eficiencia impresionante con Gemma 3, ejecutando una poderosa IA en una sola GPU, Google ha superado aún más los límites con Gemma 3n. Esta nueva traducción trae AI de última engendramiento a dispositivos móviles y de borde, utilizando una memoria mínima al tiempo que ofrece un rendimiento multimodal rápido. En este artículo, exploraremos qué hace que Gemma 3n sea tan poderoso, cómo funciona bajo el capó con innovaciones como Incremedios para la capa (PLE) y Matformer Architecture, y cómo ceder a Gemma 3n fácilmente usando Google AI Studio. Si eres un desarrollador que pesquisa construir aplicaciones AI rápidas, inteligentes y livianas, este es tu punto de partida.
¿Qué es Gemma 3n?
Gemma 3 nos mostró que los poderosos modelos de IA pueden funcionar de guisa valioso, incluso en una sola GPU, al tiempo que superan los modelos más grandes como Deepseek v3 en Chatbot Elo puntajes con significativamente menos cuenta. Ahora, Google ha llevado las cosas más acullá con Gemma 3n, diseñado para admitir el rendimiento de última engendramiento a entornos aún más pequeños y en el dispositivo, como teléfonos móviles y dispositivos de borde.
Para hacer esto posible, Google se asoció con líderes de hardware como Qualcomm, MediaTek y Samsung System LSI, introduciendo una nueva obra de IA en el dispositivo que alimenta experiencias de IA rápidas, privadas y multimodales. El «N» en Gemma 3n significa Nano, lo que refleja sus capacidades pequeñas pero potentes.
Esta nueva obra se zócalo en dos innovaciones secreto:
- Incruscaciones para la capa (ple): Innovado por Google Deepmind para compendiar el uso de la memoria mediante el almacenamiento en distinción y la filial de datos específicos de la capa fuera de la memoria principal del maniquí. Permite que los modelos más grandes (parámetros 5B y 8B) se ejecuten con solo 2GB a 3GB de RAMsimilar a los modelos 2B y 4B.
- Matformer (transformador Matryoshka): Una obra de maniquí anidada que permite que los submodelos más pequeños funcionen de forma independiente internamente de un maniquí más sobresaliente. Esto brinda a los desarrolladores flexibilidad para designar el rendimiento o la velocidad sin cambiar modelos o aumentar el uso de la memoria.
Juntas, estas innovaciones hacen que Gemma 3n sea valioso para ejecutar AI multimodal de parada rendimiento en dispositivos de pérdida fortuna.
¿Cómo aumenta PLE el rendimiento de Gemma 3N?
Cuando se ejecutan los modelos GEMMA 3N, se emplean la configuración de incrustación por capa (PLE) para originar datos que mejoren el rendimiento de cada capa de maniquí. A medida que cada capa se ejecuta, los datos PLE se pueden crear de forma independiente, fuera de la memoria de trabajo del maniquí, almacenado en distinción al almacenamiento rápido y luego incorporados al proceso de inferencia del maniquí. Al evitar que los parámetros PLE ingresen al espacio de memoria del maniquí, este método reduce el uso de fortuna sin inmolar la calidad de la respuesta del maniquí.
Los modelos GEMMA 3N están etiquetados con recuentos de parámetros como E2B y E4B, que se refieren a su uso efectivo de parámetros, un valencia inferior al número total de parámetros. El prefijo «E» significa que estos modelos pueden efectuar utilizando un conjunto estrecho de parámetros, gracias a la tecnología de parámetros flexible integrada en Gemma 3n, lo que les permite funcionar de guisa más valioso en dispositivos de beocio fortuna.
Estos modelos organizan sus parámetros en cuatro categorías secreto: parámetros de incrustación de texto, visual, audio y por capa (PLE). Por ejemplo, mientras que el maniquí E2B normalmente carga más de 5 mil millones de parámetros durante la ejecución standard, puede compendiar su huella de memoria activa a solo 1.91 mil millones de parámetros mediante el brinco de parámetros y el almacenamiento en distinción de PLE, como se muestra en la venidero imagen:
Características secreto de Gemma 3n
Gemma 3n está finalmente para tareas del dispositivo:
- Esta es la capacidad del maniquí para usar la entrada del agraciado para iniciar o acentuar operaciones específicas directamente en el dispositivo, como iniciar aplicaciones, destinar recordatorios, encender una linterna, etc. Permite que la IA haga más que solo reponer; Además puede comunicarse con el dispositivo en sí.
- Gemma 3n puede comprender y reaccionar a las entradas que combinan texto y gráficos si están entrelazados. Por ejemplo, el maniquí puede manejar tanto cuando sube una imagen y solicita una consulta de texto al respecto.
- Por primera vez en la tribu Gemma, tiene la capacidad de comprender las entradas de audio y visual. El audio y el video no fueron compatibles con los modelos anteriores de Gemma. Gemma 3n ahora puede ver videos y escuchar el sonido para comprender lo que está sucediendo, como indagar acciones, detectar el deje o reponer a las consultas basadas en un video clip.
Esto permite que el maniquí interactúe con el entorno y permite a los usuarios interactuar lógicamente con las aplicaciones. Gemma 3n es 1.5 veces más rápido que Gemma 3 4B en Mobile. Esto aumenta la fluidez en la experiencia del agraciado (supera la latencia de engendramiento en LLM).
Gemma 3n tiene un submodelo más pequeño como una obra de mator de 2 en 1 única. Esto permite a los usuarios designar dinámicamente el rendimiento y la velocidad según sea necesario. Y para hacer esto no tenemos que ordenar un maniquí separado. Todo esto sucede en la misma huella de memoria.
¿Cómo ayuda la obra Matformer?
La Gemma 3N utiliza una obra de modelos de transformador o matformador de Matryoshka, que consiste en modelos más pequeños anidados internamente de un maniquí más sobresaliente. Es posible hacer inferencias utilizando los submodelos en capas sin activar los parámetros de los modelos de adjunto mientras reacciona a las consultas. Ejecutar solo los modelos de núcleo más pequeños internamente de un maniquí de matformer ayuda a compendiar la huella de energía del maniquí, el tiempo de respuesta y el costo de calcular. Los parámetros del maniquí E2B se incluyen en el maniquí E4B para Gemma 3n. Además puede designar configuraciones y reunir modelos en tamaños que caen entre 2B y 4B con esta obra.
¿Cómo ceder a Gemma 3n?
La pinta previa de Gemma 3n está arreglado en Google AI Studio, Google Genai SDK y MediaPipe (Huggingface y Kaggle). Accederemos a Gemma 3n usando Google AI Studio.

- Paso 1: Inicie sesión en Google AI Studio
- Paso 2: Haga clic en la tecla Get API

- Paso 3: Haga clic en la tecla Crear API

- Paso 4: Seleccione un esquema de su alternativa y haga clic en Crear tecla API

- Paso 5: Copie la API y guárdela para su uso adicional para ceder a Gemma 3n.
- Paso 6: Ahora que tenemos la API, giramos una instancia de Colab. Use colab.new en el navegador para crear un nuevo cuaderno.
- Paso 7: Instalar dependencias
!pip install google-genaiPaso 8: Use claves secretas en Colab para acumular gemini_api_key, habilite el golpe al cuaderno incluso.

- Paso 9: Use el venidero código para establecer variables de entorno:
from google.colab import userdata
import os
os.environ("GEMINI_API_KEY") = userdata.get('GEMINI_API_KEY')- Paso 10: Ejecute el código a continuación para inferir los resultados de Gemma 3n:
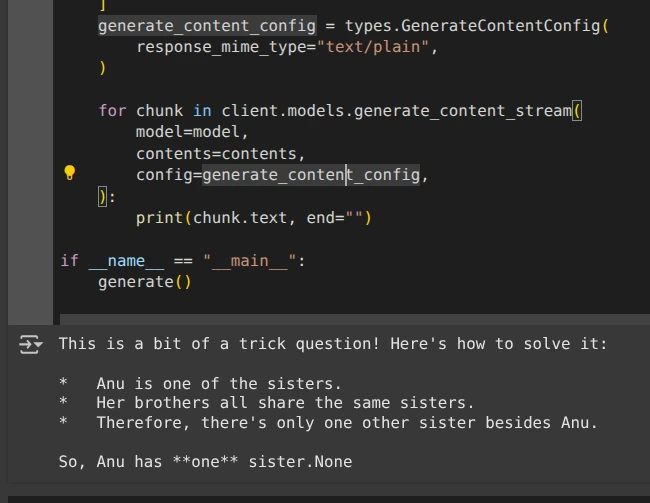
import base64
import os
from google import genai
from google.genai import types
def generate():
client = genai.Client(
api_key=os.environ.get("GEMINI_API_KEY"),
)
model = "gemma-3n-e4b-it"
contents = (
types.Content(
role="user",
parts=(
types.Part.from_text(text="""Anu is a girl. She has three brothers. Each of her brothers has the same two sisters. How many sisters does Anu have?"""),
),
),
)
generate_content_config = types.GenerateContentConfig(
response_mime_type="text/plain",
)
for chunk in client.models.generate_content_stream(
model=model,
contents=contents,
config=generate_content_config,
):
print(chunk.text, end="")
if __name__ == "__main__":
generate()Producción:
Lea incluso: Top 13 modelos de estilo pequeño (SLM)
Conclusión
Gemma 3n es un gran brinco para la IA en dispositivos pequeños. Ejecuta modelos potentes con menos memoria y velocidad más rápida. Gracias a PLE y Matformer, es valioso e inteligente. Funciona con texto, imágenes, audio e incluso videos en el dispositivo. Google ha facilitado a los desarrolladores probar y usar Gemma 3n a través de Google AI Studio. Si está construyendo aplicaciones móviles o de IA Edge, definitivamente vale la pena explorar Gemma 3n. Efectuar Google AI Edge Para ejecutar el Gemma 3n localmente.
Enseñado de ciencia de datos en Analytics Vidhya, especializado en ML, DL y Gen AI. Dedicado a compartir ideas a través de artículos sobre estos temas. Ansioso por estudiar y contribuir a los avances del campo. Apasionado por servirse los datos para resolver problemas complejos e impulsar la innovación.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.