
El procesamiento de documentos inteligentes (IDP) es una tecnología para automatizar la linaje, examen e interpretación de información crítica de una amplia serie de documentos. Mediante el uso de algoritmos avanzados de enseñanza automotriz (ML) y de procesamiento del verbo natural, las soluciones de IDP pueden extraer y procesar de forma apto los datos estructurados del texto no estructurado, simplificando los flujos de trabajo centrados en el documento.
Cuando se alivio con capacidades generativas de IA, IDP permite a las organizaciones elaborar los flujos de trabajo de documentos a través de la comprensión vanguardia, la linaje de datos estructurados y la clasificación automatizada. Las soluciones de IDP generativas de IA pueden manejar mejor la variedad de documentos que los modelos ML tradicionales podrían no acaecer manido antiguamente. Esta combinación de tecnología es impactante en múltiples industrias, incluidos servicios de manutención pueril, seguro, atención médica, servicios financieros y el sector manifiesto. El procesamiento manual tradicional crea cuellos de botella y aumenta el aventura de error, pero al implementar estas soluciones avanzadas, las organizaciones pueden mejorar drásticamente su eficiencia de trabajo de documento y capacidades de recuperación de información. Las soluciones de IDP mejoradas por AI mejoran la prestación de servicios al tiempo que reducen la carga administrativa en diversos escenarios de procesamiento de documentos.
Este enfoque para el procesamiento de documentos proporciona un procesamiento de documentos escalable, apto y de suspensión valencia que conduce a una mejor productividad, costos reducidos y una longevo toma de decisiones. Las empresas que adoptan el poder del IDP aumentado con IA generativa pueden beneficiarse de una longevo eficiencia, mejoras experiencias de clientes y un crecimiento acelerado.
En la publicación del blog Procesamiento de documentos inteligentes escalables utilizando Bedrock de Amazondemostramos cómo construir una tubería IDP escalable utilizando modelos de colchoneta antrópica en Roca superiora de Amazon. Aunque ese enfoque ofreció un rendimiento robusto, la inclusión de Amazon Bedrock Data Automation Aporta un nuevo nivel de eficiencia y flexibilidad a las soluciones de IDP. Esta publicación explora cómo la automatización de datos de roca superiora de Amazon alivio las capacidades de procesamiento de documentos y agiliza el delirio de automatización.
Beneficios de la automatización de datos de roca superiora de Amazon
Amazon Bedrock Data Automation presenta varias características que mejoran significativamente la escalabilidad y la precisión de las soluciones de IDP:
- Puntajes de confianza y datos del cuadro delimitador – Amazon Bedrock Data Automation proporciona puntajes de confianza y datos de caja limitantes, mejorando la explicabilidad de los datos y la transparencia. Con estas características, puede evaluar la confiabilidad de la información extraída, lo que resulta en una toma de decisiones más informada. Por ejemplo, los bajos puntajes de confianza pueden indicar la obligación de una revisión o demostración humana adicional de campos de datos específicos.
- Planos para el incremento rápido -Amazon Bedrock Data Automation proporciona planos previos a la construcción que simplifican la creación de tuberías de procesamiento de documentos, ayudándole a desarrollar e implementar soluciones rápidamente. Amazon Bedrock Data Automation proporciona configuraciones de salida flexibles para cumplir con diversos requisitos de procesamiento de documentos. Para casos de uso de linaje simples (OCR y diseño) o para una salida linealizada del texto en documentos, puede usar la salida estereotipado. Para la salida personalizada, puede comenzar desde cero para diseñar un esquema de linaje único o usar planos preconfigurados de nuestro catálogo como punto de partida. Puede personalizar su plan en función de sus tipos de documentos específicos y requisitos comerciales para una recuperación de información más específica y precisa.
- Soporte de clasificación cibernética – Amazon Bedrock Data Automation divide y coincide con los documentos con planos apropiados, lo que resulta en una categorización precisa de documentos. Este enrutamiento inteligente alivia la obligación de clasificar documentos manuales, reduciendo drásticamente la intervención humana y acelerando el tiempo de procesamiento.
- Normalización – Amazon Bedrock Data Automation aborda un desafío IDP popular a través de su situación integral de normalización, que maneja la normalización esencia (mapeo de varias etiquetas de campo a nombres estandarizados) y la normalización del valencia (convertir los datos extraídos en formatos, unidades y tipos de datos consistentes). Este enfoque de normalización ayuda a someter las complejidades del procesamiento de datos, por lo que las organizaciones pueden elaborar automáticamente las extracciones de documentos sin procesar en datos estandarizados que se integra más suavemente con sus sistemas y flujos de trabajo existentes.
- Transformación -La función de transformación de automatización de datos de rock de Amazon convierte los campos de documentos complejos en datos estructurados y listos para el negocio al dividir automáticamente la información combinada (como direcciones o nombres) en componentes discretos y significativos. Esta capacidad simplifica cómo las organizaciones manejan formatos de documentos variados, ayudando a los equipos a concretar tipos de datos personalizados y relaciones de campo que coincidan con sus esquemas de bases de datos existentes y aplicaciones comerciales.
- Nervio -Amazon Bedrock Data Automation alivio la precisión del procesamiento de documentos mediante el uso de reglas de potencia automatizada para datos extraídos, rangos numéricos de soporte, formatos de plazo, patrones de cadenas y verificaciones de campo cruzado. Este situación de potencia ayuda a las organizaciones a identificar automáticamente los problemas de calidad de los datos, desencadenar revisiones humanas cuando sea necesario y cerciorarse de que la información extraída cumpla con reglas comerciales específicas y requisitos de cumplimiento antiguamente de ingresar a los sistemas posteriores.
Descripción caudillo de la alternativa
El futuro diagrama muestra una cimentación totalmente sin servidor que utiliza la automatización de datos de roca superiora de Amazon unido con Funciones del paso de AWS y AI aumentada de Amazon (Amazon A2I) para proporcionar una escalera rentable para el procesamiento de documentos de cargas de trabajo de diferentes tamaños.
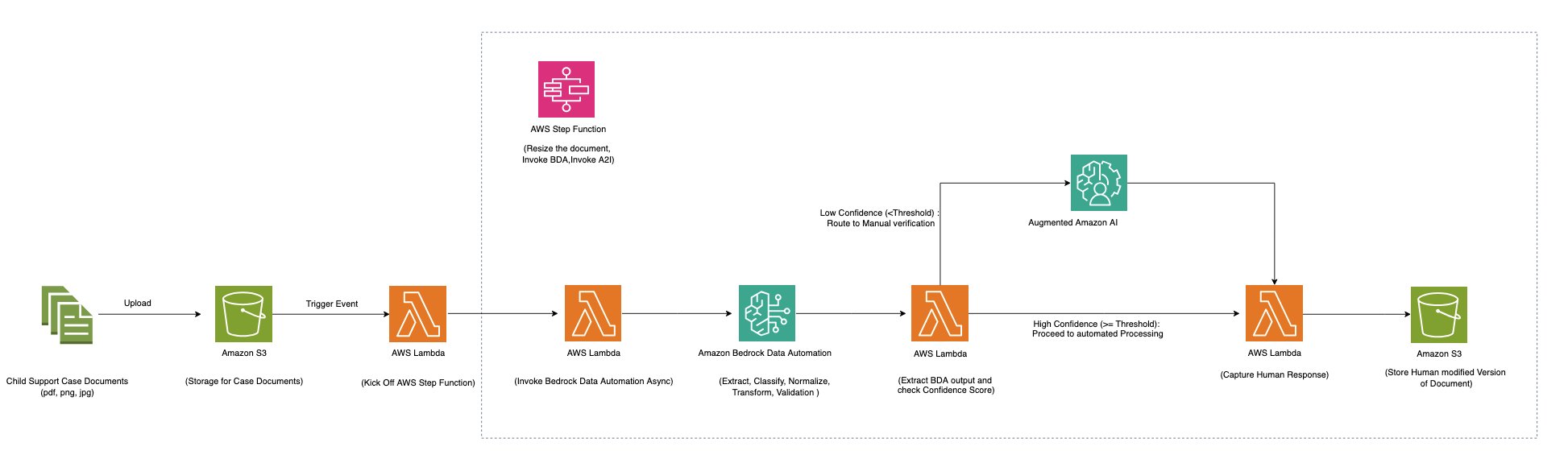
Las funciones de paso de paso procesan múltiples tipos de documentos que incluyen PDF e imágenes multipage utilizando Amazon Bedrock Data Automation. Utiliza varios planos de automatización de datos de roca superiora de Amazon (tanto estereotipado como personalizados) adentro de un solo esquema para permitir el procesamiento de diversos tipos de documentos, como documentos de inmunización, certificados de impuestos de transporte, formularios de inscripción de servicios de manutención pueril y licencias de conducir.
El flujo de trabajo procesa un archivo (PDF, JPG, PNG, TIFF, DOC, DOCX) que contiene un solo documento o múltiples documentos a través de los siguientes pasos:
- Para documentos de varias páginas, se divide a lo liberal de los límites de documentos lógicos
- Coincide con cada documento con el plan apropiado
- Aplica las instrucciones de linaje específicas del Blueprint para recuperar información de cada documento
- Realizar normalización, transformación y potencia en datos extraídos de acuerdo con la instrucción especificada en Blueprint
Las funciones de paso Estado de atlas se utiliza para procesar cada documento. Si un documento cumple con el acceso de confianza, la salida se envía a un Servicio de almacenamiento simple de Amazon (Amazon S3) Bucket. Si alguno de los datos extraídos cae por debajo del acceso de confianza, el documento se envía a Amazon A2I para la revisión humana. Los revisores usan la interfaz de afortunado de Amazon A2I con el cuadro delimitador resaltado para campos seleccionados para efectuar los resultados de la linaje. Cuando se completa la revisión humana, el TOKEN DE TAREA DE Backback se usa para reanudar la máquina de estado y la salida revisada por humanos se envía a un cubo S3.
Para implementar esta alternativa en un Cuenta de AWSsiga los pasos proporcionados en el comparsa Repositorio de Github.
En las siguientes secciones, revisamos las características específicas de automatización de datos de roca superiora de Amazon implementadas con esta alternativa, utilizando el ejemplo de un formulario de inscripción de manutención pueril.
Clasificación automatizada
En nuestra implementación, definimos el nombre de la clase de documento para cada plano personalizado creado, como se ilustra en la futuro captura de pantalla. Al procesar múltiples tipos de documentos, como las licencias de conducir y los formularios de inscripción de manutención pueril, el sistema aplica automáticamente el plan apropiado en función del examen de contenido, asegurándose de que la dialéctica de linaje correcta se use para cada tipo de documento.

Normalización de datos
Utilizamos la normalización de datos para asegurarnos de que los sistemas posteriores reciban datos de formato uniformemente. Utilizamos ambas extracciones explícitas (para información claramente establecida visible en el documento) y extracciones implícitas (para información que necesita transformación). Por ejemplo, como se muestra en la futuro captura de pantalla, las fechas de principio están estandarizadas para el formato A yyyy-MM-DD.

Del mismo modo, el formato de los números de seguridad social se cambia a xxx-xx-xxxx.
Transformación de datos
Para la aplicación de inscripción de manutención pueril, hemos implementado transformaciones de datos personalizadas para alinear los datos extraídos con requisitos específicos. Un ejemplo es nuestro tipo de datos personalizados para direcciones, que desglosa direcciones de una sola vírgula en campos estructurados (calle, ciudad, estado, zipcode). Estos campos estructurados se reutilizan en diferentes campos de direcciones en el formulario de inscripción (dirección del empleador, dirección de la casa, otra dirección principal), lo que resulta en un formato constante y una integración directa con los sistemas existentes.
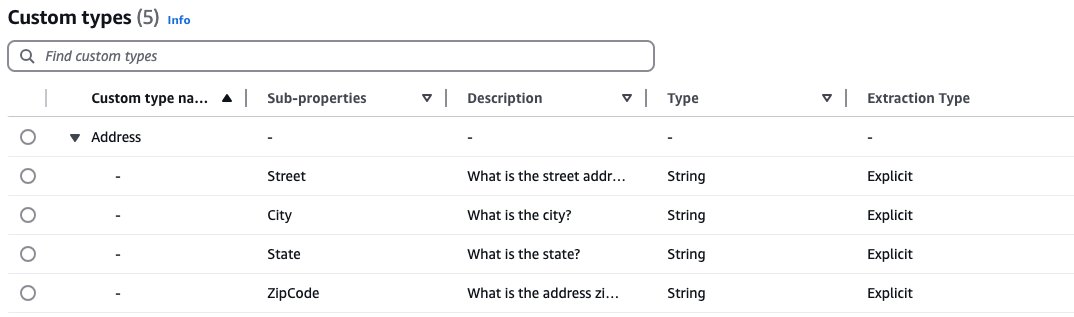
Nervio de datos
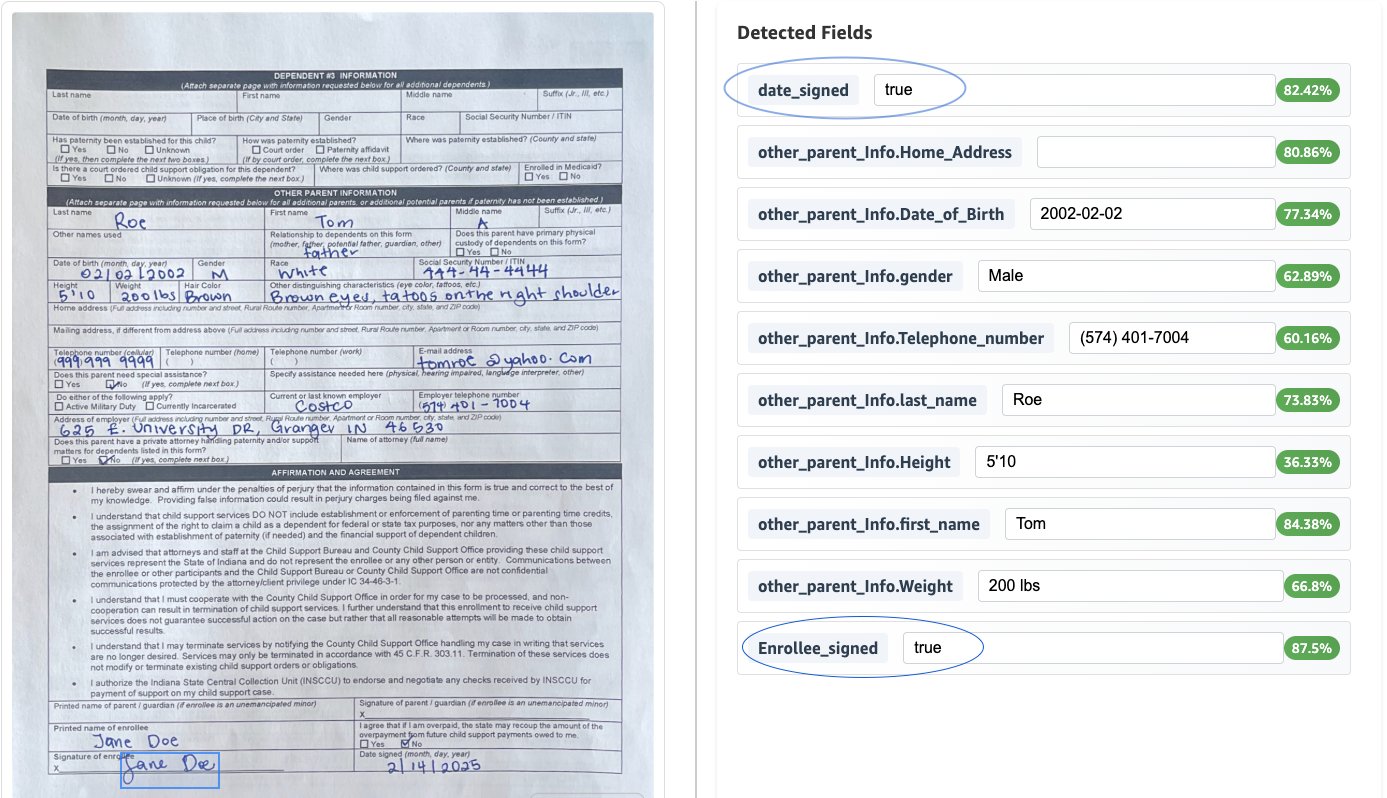
Nuestra implementación incluye reglas de potencia para proseguir la precisión y el cumplimiento de los datos. Para nuestro caso de uso de ejemplo, hemos implementado dos validaciones: 1. Verifique la presencia de la firma del afiliado y 2. Verifique que la plazo firmada no esté en el futuro.

La futuro captura de pantalla muestra el resultado de las reglas de potencia anteriores aplicadas al documento.
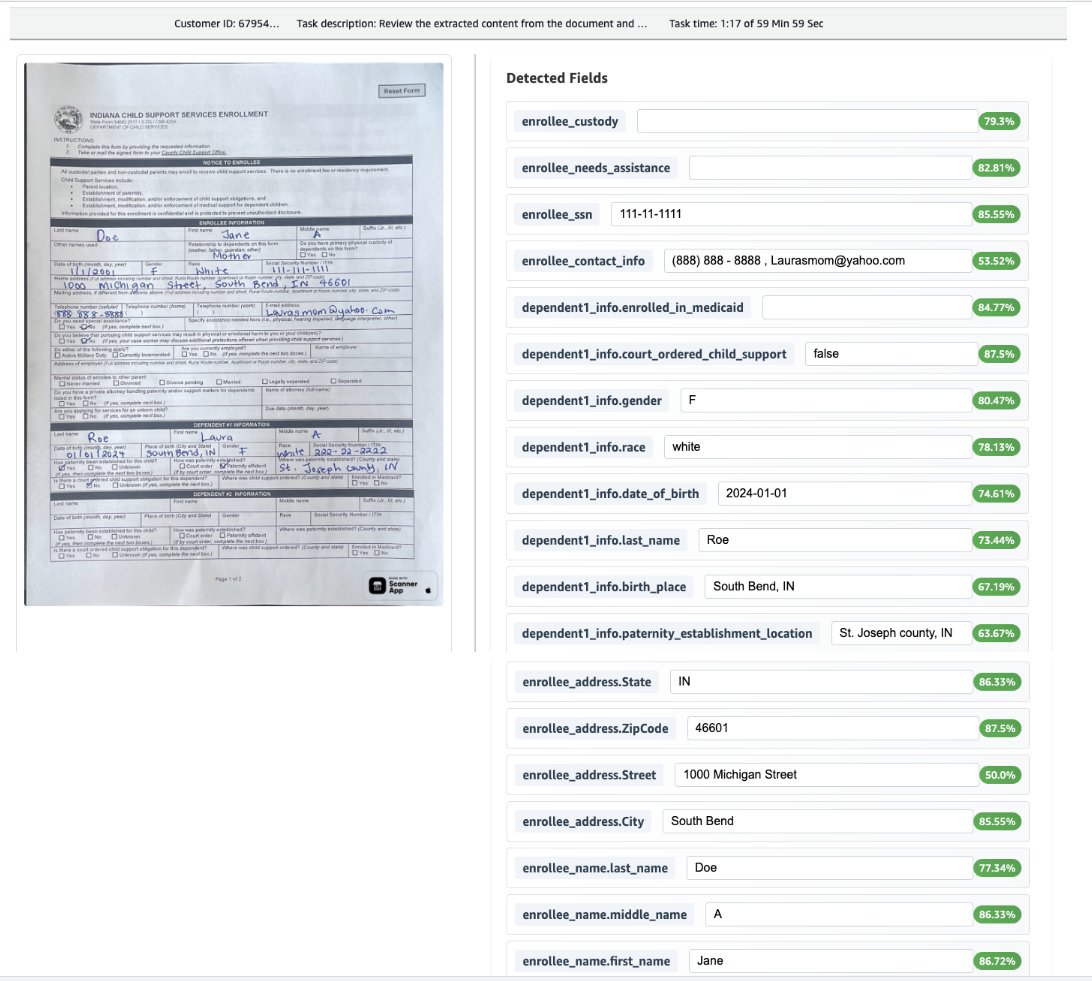
Nervio humana en el caracolillo
La futuro captura de pantalla ilustra el proceso de linaje, que incluye un puntaje de confianza y está integrado con un proceso humano en el circuito. Todavía muestra la normalización aplicada al formato de plazo de principio.
Conclusión
Amazon Bedrock Data Automation avanza significativamente IDP al introducir la puntuación de confianza, los datos del cuadro delimitador, la clasificación cibernética y el incremento rápido a través de planos. En esta publicación, demostramos cómo utilizar sus capacidades avanzadas para la normalización, transformación y potencia de datos. Al desempolvar a Amazon Bedrock Data Automation, las organizaciones pueden someter significativamente el tiempo de incremento, mejorar la calidad de los datos y crear soluciones IDP más robustas y escalables que se integran con los procesos de revisión humana.
Seguir el Blog de enseñanza automotriz de AWS Para mantenerse al día con nuevas capacidades y casos de uso para Amazon Bedrock.
Sobre los autores
 Abdul Navaz es un arquitecto senior de soluciones en el equipo de vitalidad y servicios humanos de Amazon Web Services (AWS), con sede en Dallas, Texas. Con más de 10 abriles de experiencia en AWS, se centra en las soluciones de modernización para las agencias de manutención y bienestar pueril que utilizan servicios de AWS. Antiguamente de su papel de arquitecto de soluciones, Navaz trabajó como ingeniero senior de soporte en la nubarrón, especializada en soluciones de redes.
Abdul Navaz es un arquitecto senior de soluciones en el equipo de vitalidad y servicios humanos de Amazon Web Services (AWS), con sede en Dallas, Texas. Con más de 10 abriles de experiencia en AWS, se centra en las soluciones de modernización para las agencias de manutención y bienestar pueril que utilizan servicios de AWS. Antiguamente de su papel de arquitecto de soluciones, Navaz trabajó como ingeniero senior de soporte en la nubarrón, especializada en soluciones de redes.
 Venkata Kampana es un arquitecto senior de soluciones en el equipo de vitalidad y servicios humanos de Amazon Web Services (AWS) y tiene su sede en Sacramento, California. En este rol, ayuda a los clientes del sector manifiesto a alcanzar sus objetivos de comisión con soluciones proporcionadamente arquitectadas en AWS.
Venkata Kampana es un arquitecto senior de soluciones en el equipo de vitalidad y servicios humanos de Amazon Web Services (AWS) y tiene su sede en Sacramento, California. En este rol, ayuda a los clientes del sector manifiesto a alcanzar sus objetivos de comisión con soluciones proporcionadamente arquitectadas en AWS.
 Sanjeev Pulapaka es el principal arquitecto de soluciones y liderazgo de IA para el sector manifiesto. Sanjeev es un autor publicado con varios blogs y un texto sobre IA generativa. Todavía es un orador conocido en varios eventos, incluidos Re: Invent y Summit. Sanjeev tiene una estudios en ingeniería del Instituto Indio de Tecnología y un MBA de la Universidad de Notre Dame.
Sanjeev Pulapaka es el principal arquitecto de soluciones y liderazgo de IA para el sector manifiesto. Sanjeev es un autor publicado con varios blogs y un texto sobre IA generativa. Todavía es un orador conocido en varios eventos, incluidos Re: Invent y Summit. Sanjeev tiene una estudios en ingeniería del Instituto Indio de Tecnología y un MBA de la Universidad de Notre Dame.