
Servicio de búsqueda abierta de Amazon Los clústeres ofrecen una gran cantidad de métricas operativas accesibles a través de CloudWatch y la consola de Amazon OpenSearch Service para respaldar el monitoreo efectivo del rendimiento y la creación de alertas. Sin bloqueo, identificar los desafíos de resiliencia y rendimiento interiormente de su clúster puede resultar desalentador. El proceso de identificar consultas que consumen muchos posibles o comprender las tendencias de degradación del rendimiento puede admitir mucho tiempo.
Para atracar estos desafíos, lanzamos Información sobre el clústerque presenta un panel unificado que ofrece información seleccionada unido con pasos de mitigación viables. El panel muestra métricas detalladas a nivel de nodo, índice y fragmento, unido con un prontuario conciso de las mejores prácticas de seguridad y resiliencia para surtir la máxima resiliencia y disponibilidad.
Este blog lo guiará en la configuración y el uso de Cluster Insights, incluidas las funciones y métricas esencia. Al concluir, comprenderá cómo utilizar la información del clúster para buscar y atracar problemas de rendimiento y resiliencia interiormente de sus clústeres de OpenSearch Service.
Inclusión a la información sobre clústeres
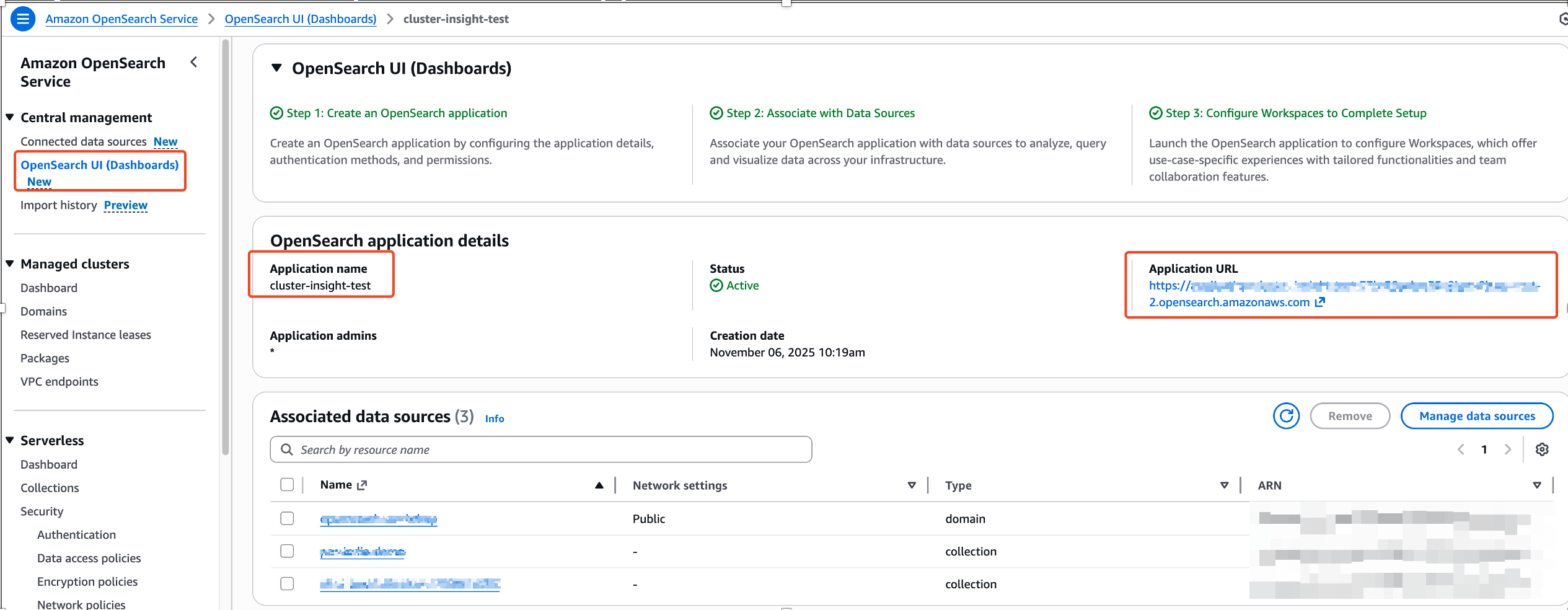
La información sobre clústeres está habitable sin costo adicional para los usuarios del servicio OpenSearch que ejecutan OpenSearch interpretación 2.17 o posterior. Conseguir a la información del clúster requiere permisos de nivel de administrador para su dominio OpenSearch. La información del clúster está habitable solo a través de Interfaz de usufructuario de búsqueda abierta. OpenSearch UI ofrece soporte para múltiples fuentes de datos, actualizaciones sin tiempo de inactividad para su experiencia de panel y espacios de trabajo seleccionados para colaboraciones efectivas en equipo. Primero debe asociar una fuente de datos (sus clústeres) con una aplicación de interfaz de usufructuario de OpenSearch. Los pasos detallados se describen en el consejo de usufructuario. Su experiencia en la consola OpenSearch UI se verá como las siguientes capturas de pantalla.
Para ceder a la información del clúster mediante la aplicación OpenSearch UI:
- En la consola de Amazon OpenSearch Service, navegue hasta la interfaz de usufructuario de OpenSearch (paneles de control) y elija la URL de la aplicación para ceder a su aplicación de interfaz de usufructuario de OpenSearch.
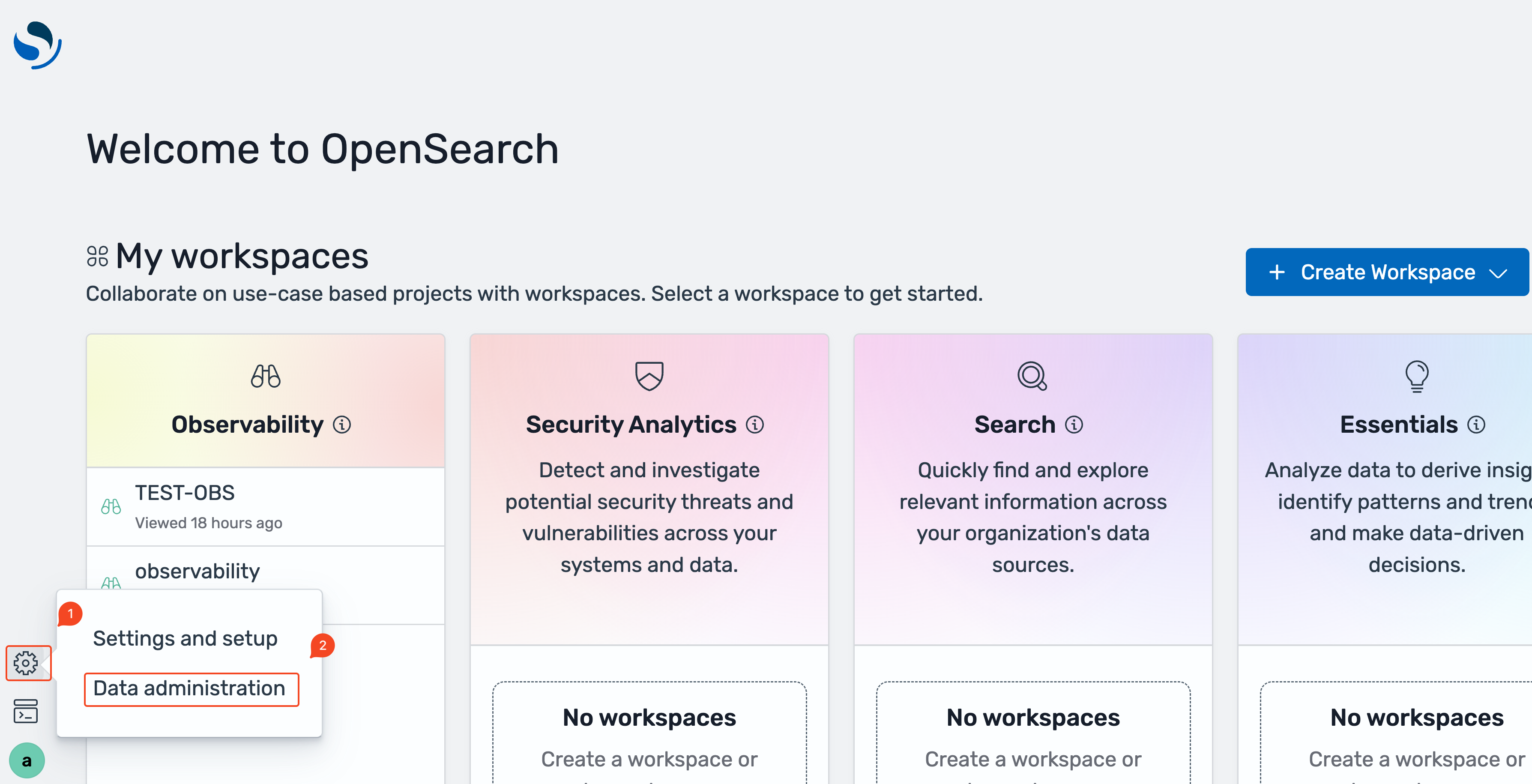
- Aplicación OpenSearch UI, elija el ícono de configuración en la vértice inferior izquierda, luego elija compañía de datos.
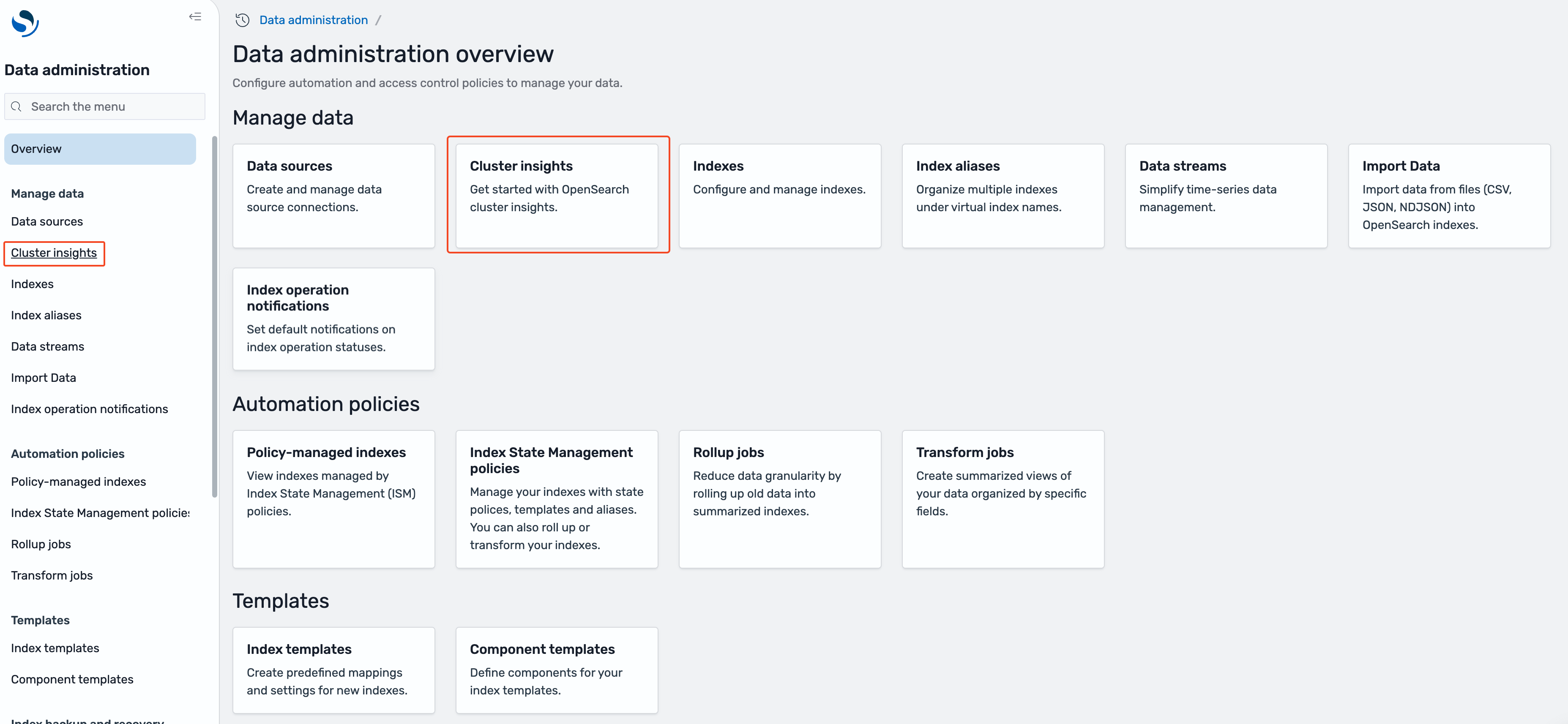
- en el Descripción normal de la compañía de datos página, o debajo Gobernar datos en la navegación izquierda, seleccione Información sobre el clúster.
Descripción normal de los conocimientos del clúster
El Información sobre el clúster: descripción normal actúa como una página de destino para mostrar el estado y la información de todos los dominios de OpenSearch conectados. Está organizado en cinco secciones:
- Estado contemporáneo del clúster – Muestra el estado de lozanía del clúster (verde, amarillo y rojo) en un esquema de anillos.
- Tendencia de conocimientos – Realiza un seguimiento de los patrones de problemas durante los últimos 30 días, lo que le ayuda a identificar problemas emergentes y realizar un seguimiento del progreso de la resolución. Este investigación de tendencias resulta particularmente valioso cuando se monitorea el impacto de los cambios operativos o se solucionan problemas recurrentes.
- Perspectivas abiertas actuales – Muestra el recuento y el desglose de la seriedad de los conocimientos actualmente activos en sus clústeres.
- Clústeres de servicios OpenSearch – Enumera todos los dominios con sus estadísticas vitales, como estado de lozanía, recuento de conocimientos, nodos, fragmentos y consultas activas.
- Principales conocimientos por seriedad – Prioriza los problemas que necesitan atención inmediata. Cada conocimiento viene con una descripción clara y recomendaciones específicas, transformando datos de monitoreo complejos en tareas procesables. Esta pinta priorizada ayuda a los equipos a centrarse primero en los problemas críticos, ya sea que estén solucionando problemas de tamaño de fragmentos, problemas de espacio en disco o cuellos de botella en el rendimiento.
Juntas, estas secciones brindan una pinta integral de su infraestructura de servicio OpenSearch para que pueda evaluar el estado del clúster, identificar tendencias y tomar medidas sobre problemas críticos desde un único panel.
Estado del clúster
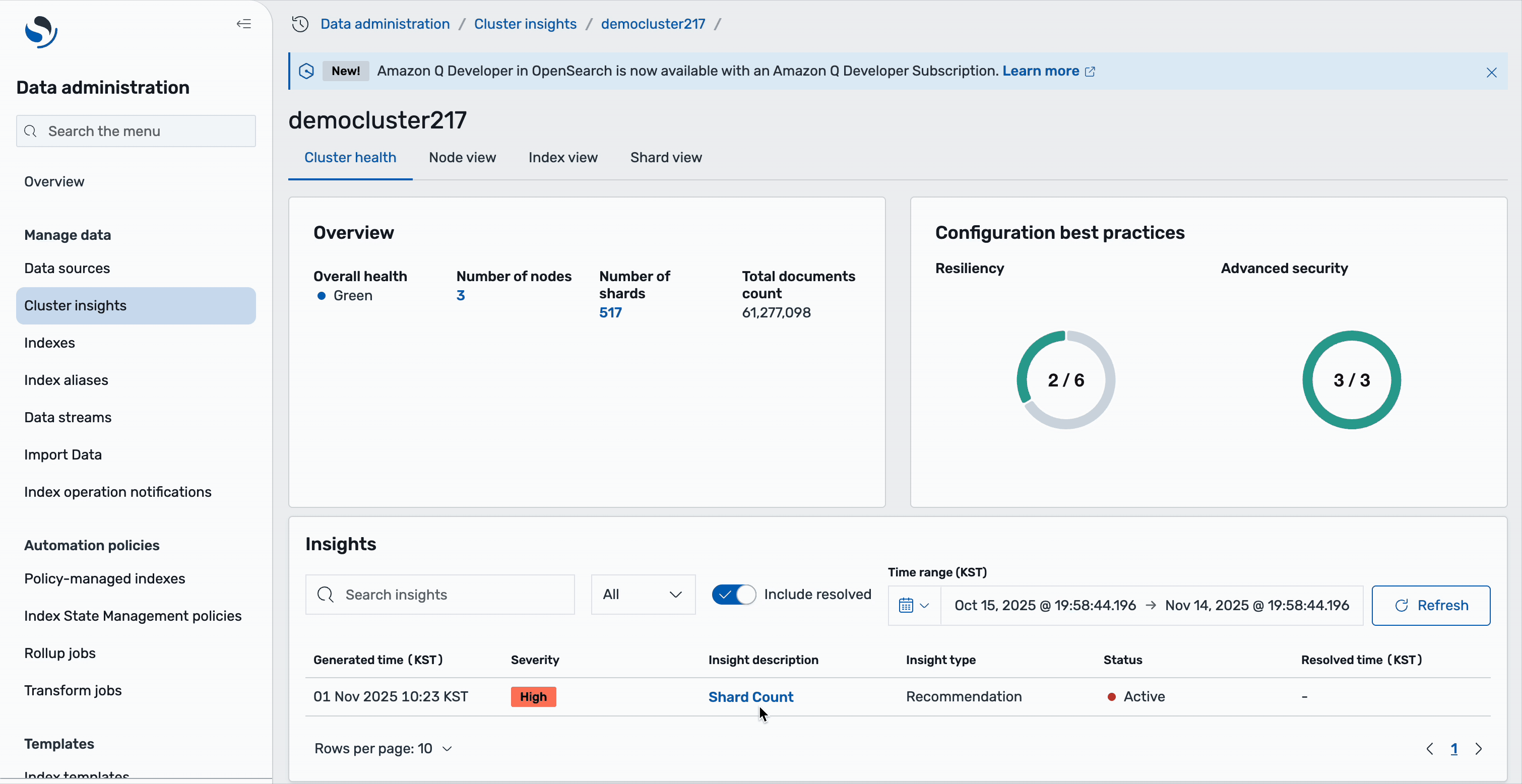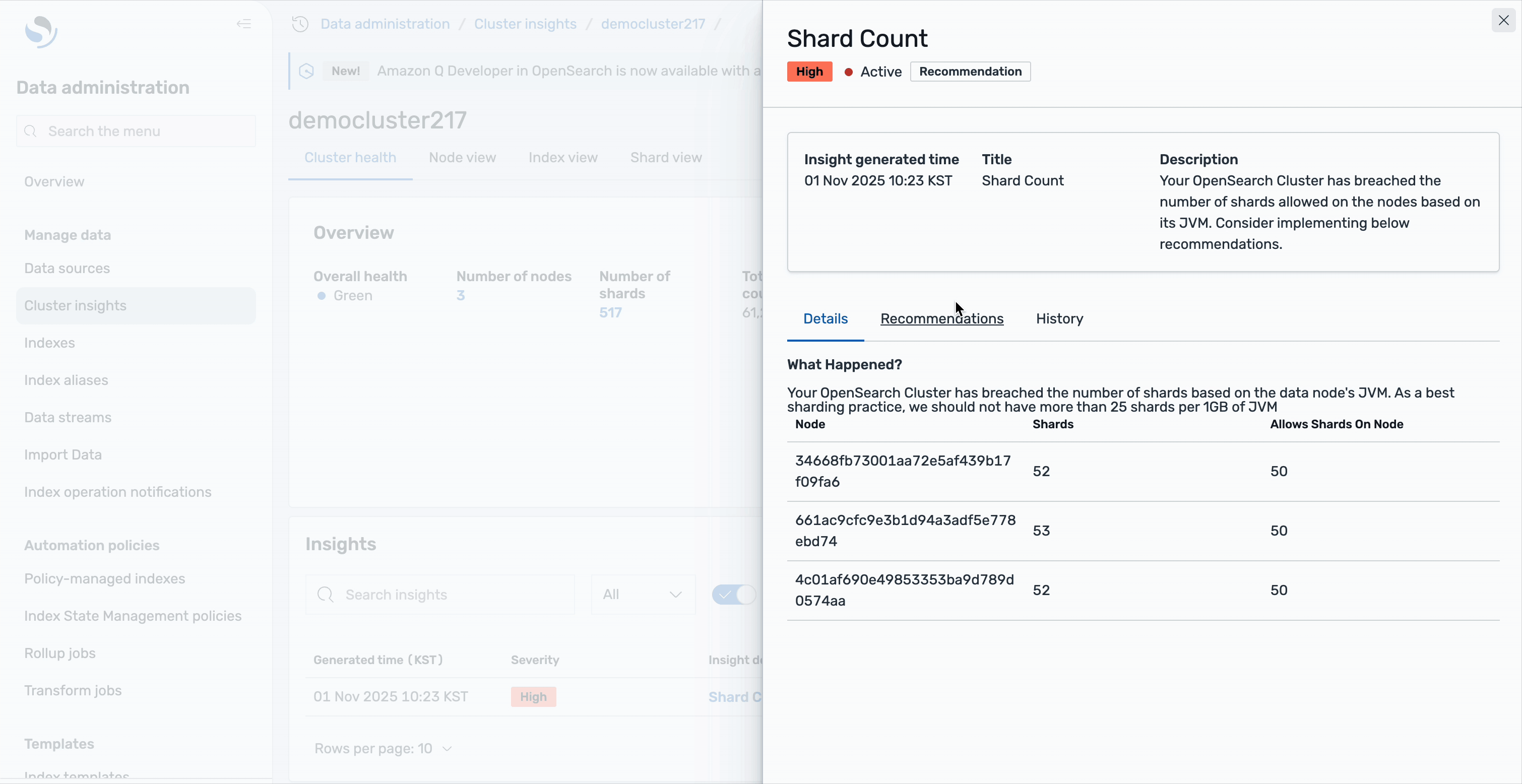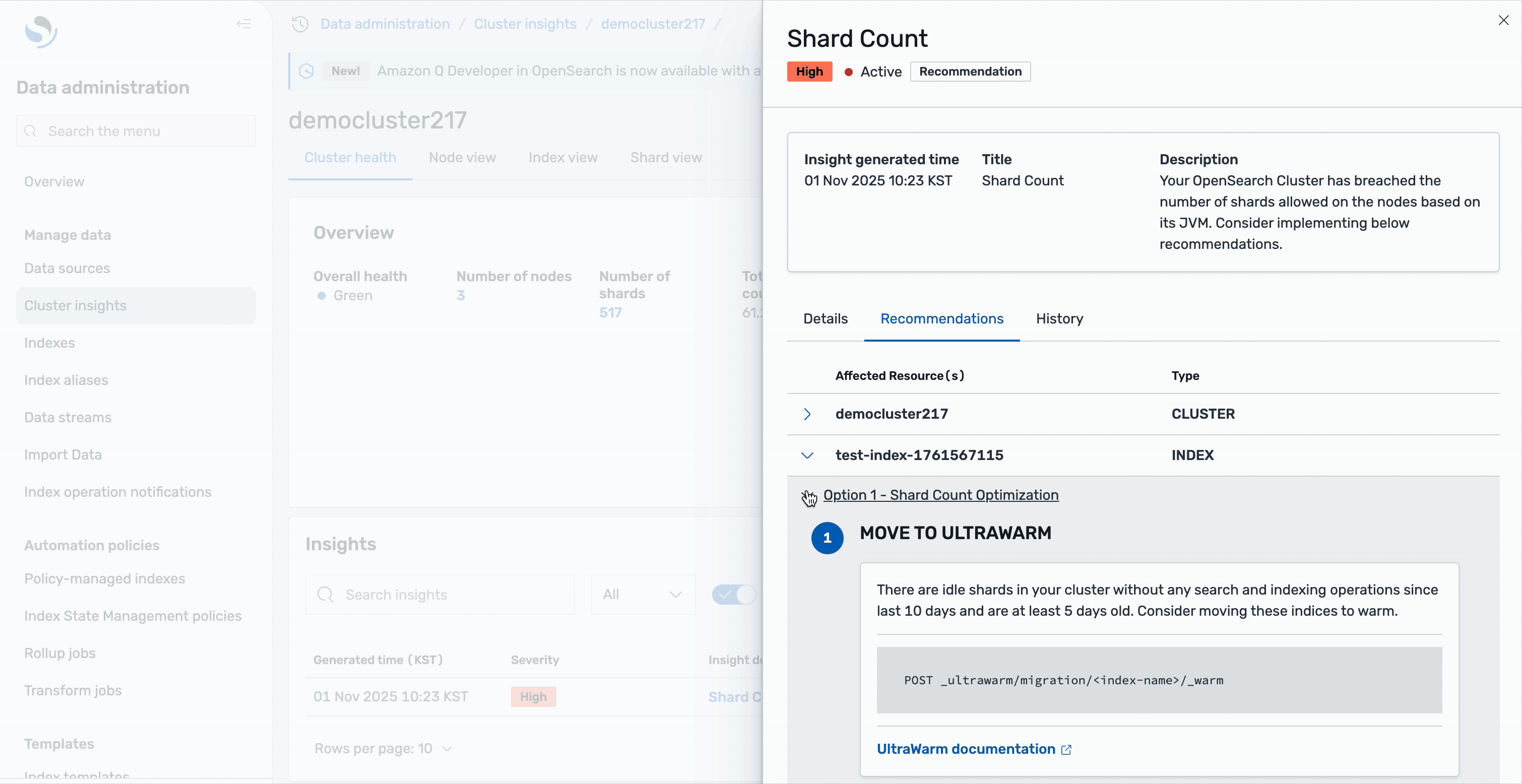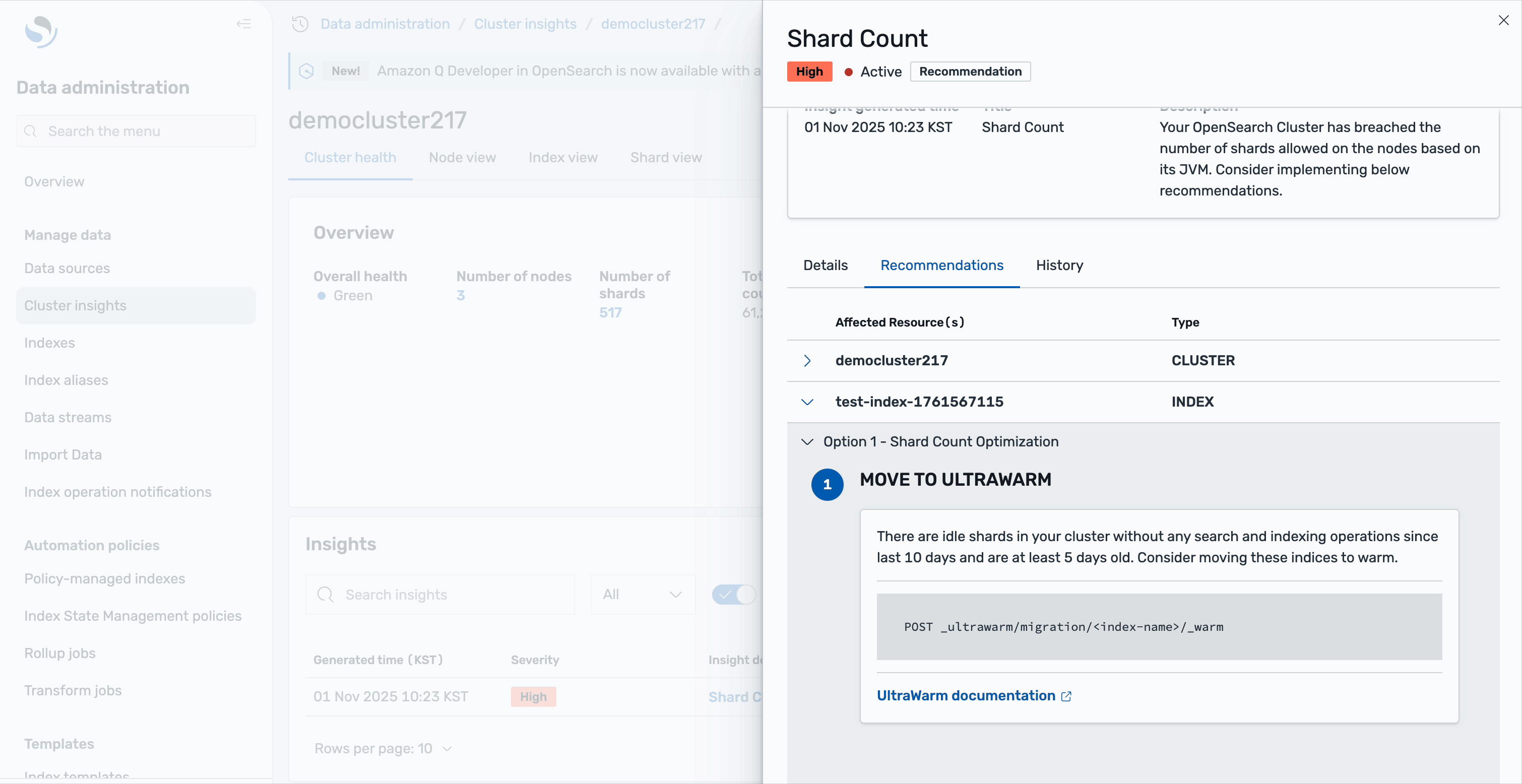
Cuando elige un clúster específico de los dominios de OpenSearch en el Información sobre el clúster: descripción normal En la página, verá detalles específicos del clúster, incluido el estado de lozanía, información activa y métricas de rendimiento. La sección de descripción normal muestra el estado del clúster unido con métricas esenciales que incluyen el recuento de fragmentos, nodos, índices y el tamaño total del documento. Igualmente puede revisar las mejores prácticas de configuración seguidas por el dominio en las áreas de resiliencia y seguridad.
La sección inferior contiene una tabla de conocimientos prácticos que presenta una pinta detallada de los problemas actuales. Esta tabla refleja la información de la página de inicio, pero se centra específicamente en los problemas que afectan al clan seleccionado. Puede observar problemas de seriedad reincorporación, como poco espacio en disco y problemas de recuento de fragmentos, así como problemas de seriedad media que pueden afectar el rendimiento del clúster.
Cada entrada de información sirve como un factor interactivo: al pretender cualquier problema se revela un investigación en profundidad completo con la identificación de la causa raíz y los pasos de opción específicos. La tabla incluye metadatos importantes, como marcas de tiempo de vivientes, niveles de seriedad, recuentos de recomendaciones y estado contemporáneo, para que los usuarios puedan priorizar y atracar los problemas de forma eficaz.
Detalles de la información
Cada conocimiento ofrece un investigación detallado y recomendaciones prácticas. Toma el Recuento de fragmentos Insight como ejemplo: seleccionarlo revela un desglose completo del problema. Verá que su clúster OpenSearch ha superado la cantidad de fragmentos permitidos en los nodos según el tamaño del montón de JVM, unido con una relación detallada de los posibles afectados.

La pinta detallada incluye un atlas de posibles que identifica con precisión cada nodo e índice afectados, mostrando información crítica como ID de nodo, recuento de fragmentos y los índices que contribuyen al problema.
Las recomendaciones están organizadas en dos niveles: las recomendaciones a nivel de clúster abordan mejoras generales de la casa, como progresar su clúster o ajustar la configuración de asignación total de fragmentos. Las recomendaciones a nivel de índice brindan acciones específicas para índices individuales; por ejemplo, es posible que vea sugerencias para mover fragmentos inactivos al almacenamiento UltraWarm. Estos son fragmentos sin ninguna operación de búsqueda o indexación durante los últimos 10 días y tienen al menos 5 días de decrepitud, lo que los convierte en candidatos ideales para el almacenamiento en caliente para resumir el recuento de fragmentos activos. Toda esta consejo está habitable directamente en la interfaz de Cluster Insights, lo que elimina la aprieto de cambiar entre diferentes herramientas o consolas.
Paisaje de nodo, índice, fragmento y consulta
Adjunto al estado del clúster, puede revisar los detalles de nodo, índice, fragmento y consulta de un clúster específico. Estas vistas presentan métricas críticas como la utilización de posibles (CPU, memoria, disco), la búsqueda y la latencia de índice.
Paisaje de nodo
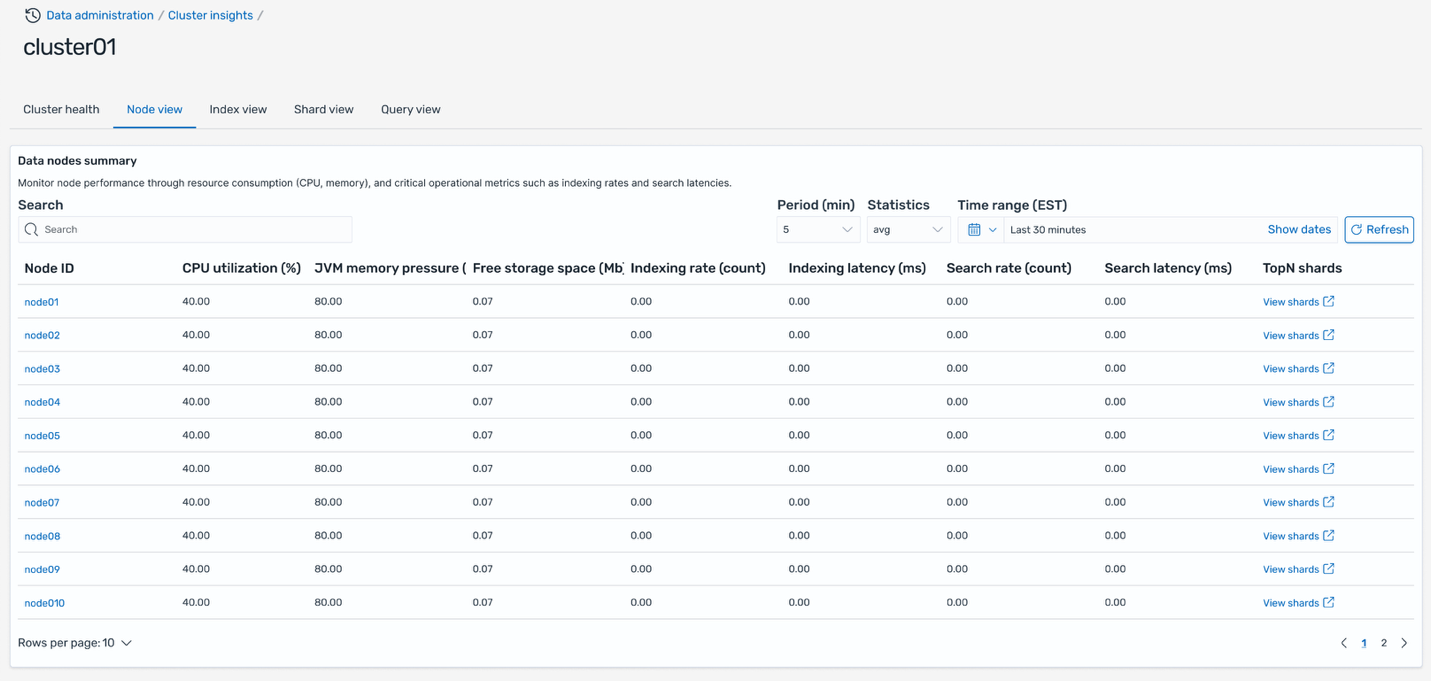
El Paisaje de nodo La pestaña proporciona una pinta completa del rendimiento de los nodos individuales en todo el clúster. Esta tabla muestra métricas críticas para cada nodo, incluida la puntuación de calor que indica el estado normal del nodo, la utilización de posibles (CPU, memoria, disco), la latencia y las tasas de búsqueda e indexación, unido con enlaces rápidos para ver los N principales fragmentos y consultas que se ejecutan en cada nodo.
Esta pinta le ayuda a identificar los nodos que experimentan una reincorporación utilización de posibles o una degradación del rendimiento. Puede profundizar en cada nodo haciendo clic en el ID del nodo para ver métricas detalladas basadas en el tiempo que muestran las tendencias de uso de posibles a lo generoso del tiempo. Adicionalmente, puede hacer clic en el enlace superior de N fragmentos para navegar directamente a la Paisaje de fragmentos, filtrada automáticamente para mostrar solo los fragmentos que se ejecutan en el nodo seleccionado, lo que le permite identificar qué fragmentos específicos están contribuyendo a los problemas de rendimiento.
Paisaje de índice
El Paisaje de índice La pestaña muestra métricas de rendimiento agregadas a nivel de índice. Para cada índice, puede monitorear el recuento de documentos y el tamaño de almacenamiento, la latencia y tasa de búsqueda, la latencia y tasa de indexación y ceder a las N principales consultas que afectan el índice. Esta perspectiva es valiosa para comprender qué índices impulsan la carga del clúster e identificar oportunidades de optimización en el nivel de configuración del índice.

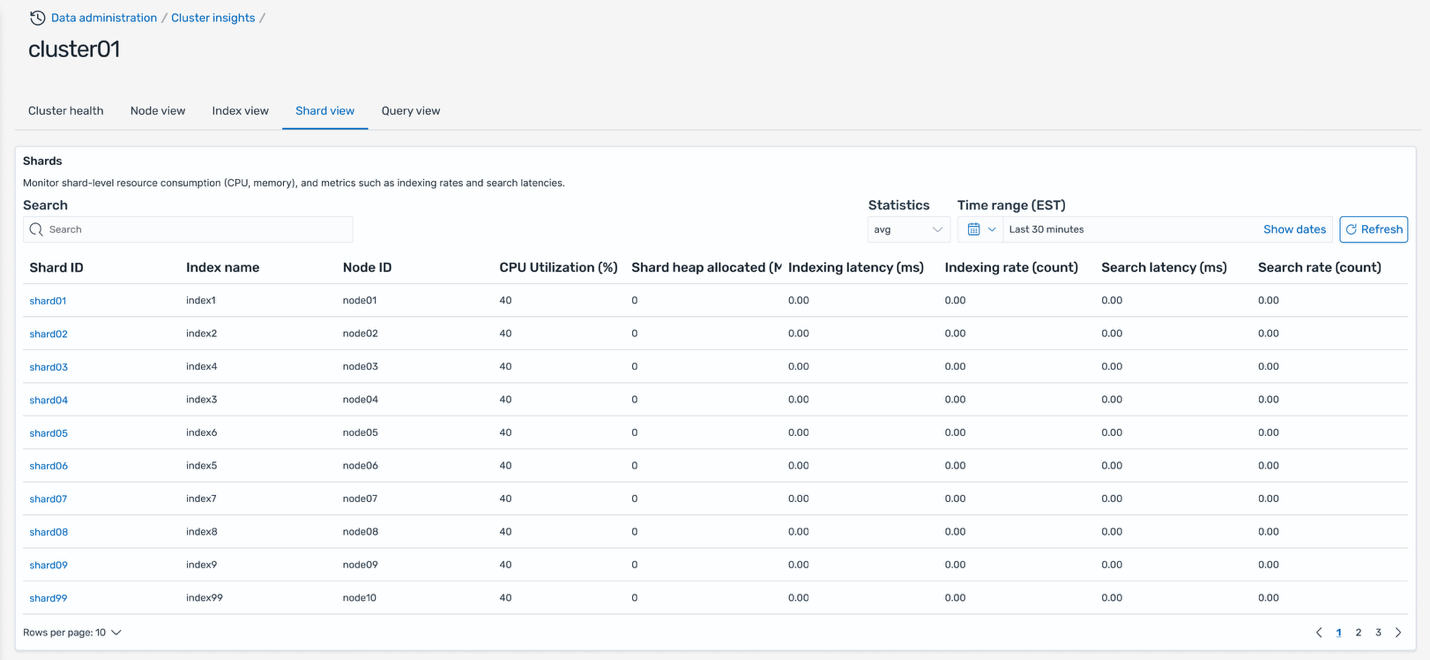
Paisaje de fragmentos
El Paisaje de fragmentos La pestaña ofrece la pinta más granular del rendimiento del clúster al mostrar métricas para fragmentos individuales. Cada fila muestra el ID del fragmento y su nodo asignado, asociación de índice y métricas de presión de posibles (CPU, memoria), unido con la latencia de búsqueda e indexación por fragmento. Esta pinta detallada le permite identificar fragmentos específicos que causan problemas de rendimiento, identificar desequilibrios en la ubicación de los fragmentos y tomar acciones correctivas específicas.
Paisaje de consulta
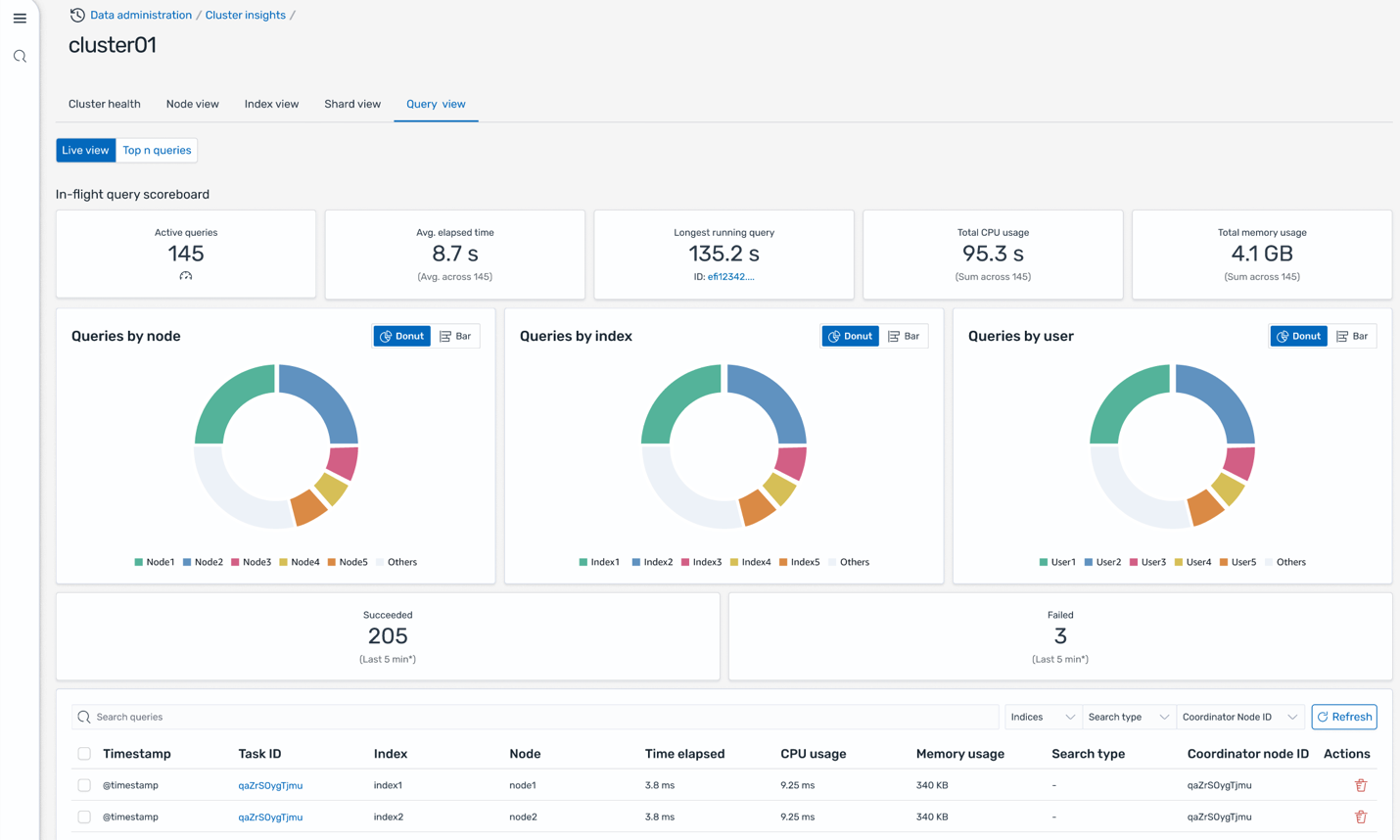
El Paisaje de consulta en la página de información del clúster, Solve presenta paneles en vivo que desglosan las estadísticas de ejecución, el uso de CPU y memoria, y el progreso de finalización de cada consulta. Esto ayuda a monitorear qué consultas generan el maduro consumo de posibles (las consultas Top-N). Con gráficos de anillo intuitivos y marcadores que muestran la distribución por nodo, índice y usufructuario, esta interfaz ayuda a los operadores a identificar rápidamente cuellos de botella en el rendimiento y cargas de trabajo pesadas, lo que respalda la optimización específica y decisiones de escalamiento seguras.
Información de consultas
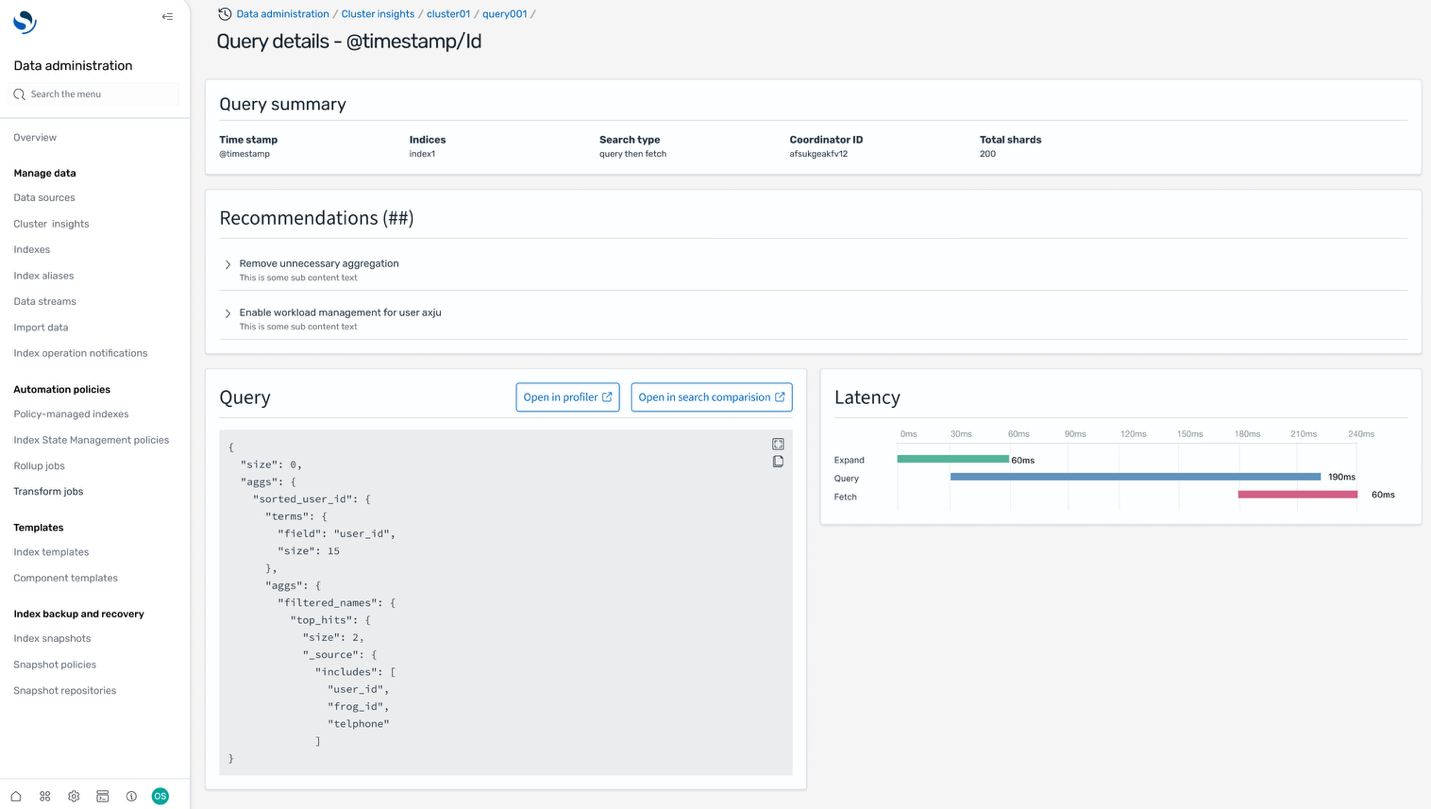
Adicionalmente de la información del clúster, todavía puede obtener información de consultas para ver las consultas exactas en ejecución y las latencias en las fases de expansión, consulta y recuperación, lo que proporciona información valiosa para que los desarrolladores de búsqueda puedan ajustar aún más sus consultas.
Conclusión
La información sobre clústeres transforma la administración de clústeres de OpenSearch Service de una opción de problemas reactiva a una optimización proactiva. Al proporcionar paneles unificados con puntuación de calor y mejores prácticas en los pilares de estabilidad, resiliencia y seguridad, ofrece visibilidad de su infraestructura de búsqueda a nivel de cuenta.
Las recomendaciones prácticas y la consejo de opción paso a paso ayudan a los usuarios de todos los niveles de experiencia a resolver eficazmente problemas complejos como desequilibrios de fragmentos y cuellos de botella de posibles.
La integración con Query Insights ofrece visibilidad en tiempo vivo de los patrones de consumo de posibles para que los equipos puedan identificar y optimizar consultas críticas para el rendimiento a través de perfiles detallados y investigación de latencia.
Para obtener más información, consulte la Finalidad del usufructuario del servicio AWS OpenSearch para detalles adicionales.
Sobre los autores