
La creciente menester de modelos de razonamiento escalable en inteligencia mecánica
Los modelos de razonamiento reformista están en la frontera de la inteligencia de la máquina, especialmente en dominios como la resolución de problemas matemáticos y el razonamiento simbólico. Estos modelos están diseñados para realizar cálculos de varios pasos y deducciones lógicas, a menudo generando soluciones que reflejan los procesos de razonamiento humano. Las técnicas de enseñanza de refuerzo se utilizan para mejorar la precisión a posteriori del previación; Sin incautación, progresar estos métodos al tiempo que retiene la eficiencia sigue siendo un desafío enrevesado. A medida que aumenta la demanda para modelos más pequeños y más eficientes en bienes que aún exhiben una ingreso capacidad de razonamiento, los investigadores ahora están recurriendo a estrategias que abordan la calidad de los datos, los métodos de exploración y la extensión de contexto a grande plazo.
Desafíos en el enseñanza de refuerzo para grandes arquitecturas de razonamiento
Un problema persistente con el enseñanza de refuerzo para los modelos de razonamiento a gran escalera es el desajuste entre la capacidad del maniquí y la dificultad de los datos de entrenamiento. Cuando un maniquí está expuesto a tareas que son demasiado simples, su curva de enseñanza se estanca. Por el contrario, los datos demasiado difíciles pueden angustiar el maniquí y no producir una señal de enseñanza. Esta dificultad de desequilibrio es especialmente pronunciada al aplicar recetas que funcionan acertadamente para modelos pequeños a los más grandes. Otro problema es la desatiendo de métodos para adaptar eficientemente la multiplicidad de despliegue y la largura de salida durante el entrenamiento e inferencia, lo que limita aún más las habilidades de razonamiento de un maniquí en puntos de relato complejos.
Limitaciones de los enfoques de post-entrenamiento existentes en modelos avanzados
Los enfoques anteriores, como DeepScaler y GRPO, han demostrado que el enseñanza de refuerzo puede mejorar el rendimiento de los modelos de razonamiento a pequeña escalera con tan solo 1.500 millones de parámetros. Sin incautación, la aplicación de estas mismas recetas a modelos más capaces, como QWEN3-4B o Deepseek-R1-Distill-Qwen-7b, resulta solo en ganancias marginales o incluso caídas de rendimiento. Una límite esencia es la naturaleza estática de la distribución de datos y la multiplicidad limitada del muestreo. La mayoría de estos enfoques no filtran datos en función de la capacidad del maniquí, ni ajustan la temperatura de muestreo o la largura de la respuesta con el tiempo. Como resultado, a menudo no pueden progresar de forma efectiva cuando se usan en arquitecturas más avanzadas.
Comienzo de Polaris: una récipe personalizada para RL escalable en tareas de razonamiento
Investigadores de la Universidad de Hong Kong, Bytedance Seed y Fudan University introdujeron Polaris, una récipe posterior al entrenamiento diseñada específicamente para el enseñanza de refuerzo de escalera para tareas de razonamiento reformista. Polaris incluye dos modelos de tino previa: Polaris-4B-Preview y Polaris-7b-Preview. Polaris-4B-Preview está cabal de QWEN3-4B, mientras que Polaris-7B-Preview se zócalo en Deepseek-R1-Distill-Qwen-7b. Los investigadores se centraron en construir un ámbito descreído maniquí que modifica la dificultad de los datos, fomenta diversas exploración a través de temperaturas de muestreo controladas y extiende las capacidades de inferencia a través de la extrapolación de largura. Estas estrategias se desarrollaron utilizando conjuntos de datos de código extenso y tuberías de capacitación, y entreambos modelos están optimizados para ejecutarse en unidades de procesamiento de gráficos de jerarquía consumidor (GPU).
Innovaciones de Polaris: dificultad para equilibrar, muestreo controlado e inferencia de contexto grande
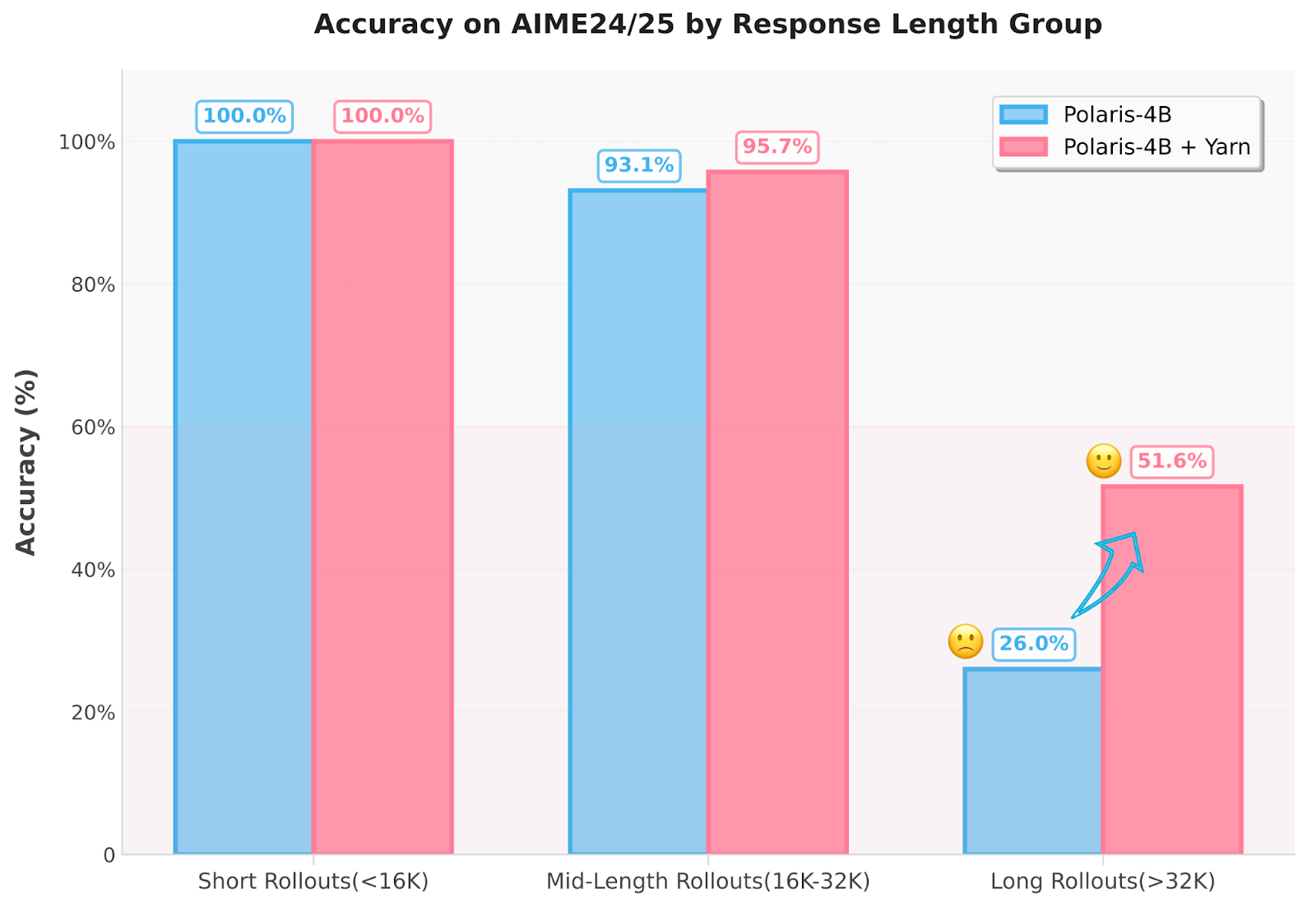
Polaris implementa múltiples innovaciones. Primero, los datos de capacitación se seleccionan eliminando problemas que son demasiado fáciles o no posibles, creando una distribución de dificultad con forma de J reflejada. Esto garantiza que los datos de entrenamiento evolucionen con las capacidades de creciente del maniquí. En segundo motivo, los investigadores ajustan dinámicamente la temperatura de muestreo a través de las etapas de entrenamiento, utilizando 1.4, 1.45 y 1.5 para Polaris-4B y 0.7, 1.0 y 1.1 para Polaris-7b, para prolongar la multiplicidad de despliegue. Adicionalmente, el método emplea una técnica de extrapolación basada en hilos para extender la largura de contexto de inferencia a tokens de 96k sin requerir capacitación adicional. Esto aborda la ineficiencia de la capacitación de secuencia larga al permitir un enfoque de «trenes, de grande y duración». El maniquí asimismo emplea técnicas como el mecanismo de rescate de despliegue y la sustitución informativa intra-lota para evitar lotes de premio cero y avalar que se conserven señales de entrenamiento efectos, incluso cuando el tamaño del despliegue se mantiene pequeño en 8.
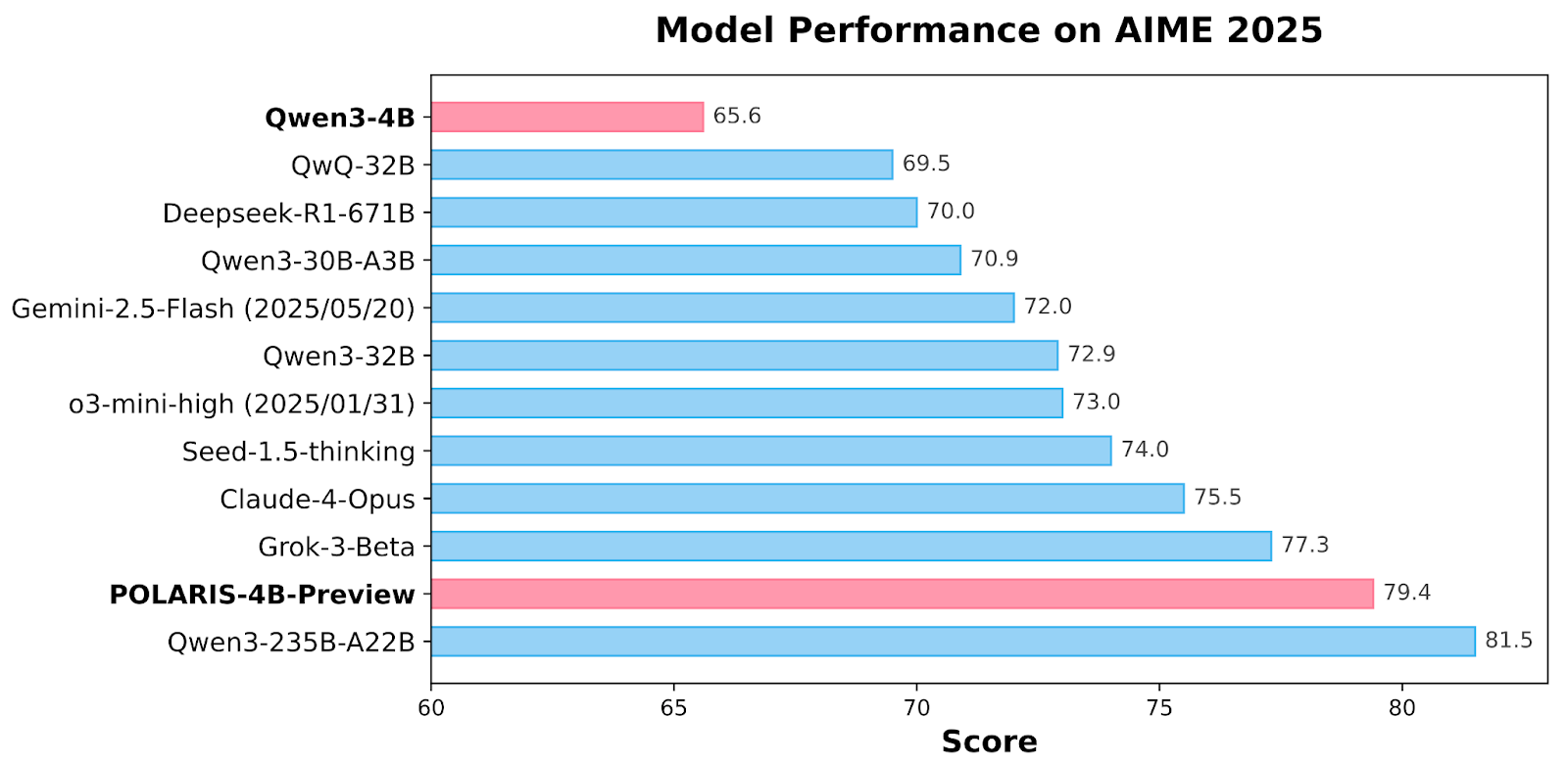
Resultados de relato: Polaris supera a los modelos comerciales más grandes
Los modelos Polaris logran resultados de última coexistentes en múltiples puntos de relato de matemáticas. Polaris-4b-previa registra el 81.2% de precisión en AIME24 y 79.4% en AIME25, superando incluso QWEN3-32B en las mismas tareas mientras usa menos del 2% de sus parámetros. Obtiene 44.0% en Minerva Math, 69.1% en Olympiad Bench y 94.8% en AMC23. Polaris-7b-previa asimismo funciona fuertemente, anotando un 72.6% en AIME24 y 52.6% en AIME25. Estos resultados demuestran una mejoramiento consistente sobre modelos como Claude-4-OPUS y GROK-3-BETA, estableciendo Polaris como un maniquí competitivo y superficial que une la brecha de rendimiento entre los pequeños modelos abiertos y los modelos comerciales de 30B+.
Conclusión: enseñanza de refuerzo competente a través de estrategias de post-entrenamiento inteligentes
Los investigadores demostraron que la esencia para progresar modelos de razonamiento no es solo un tamaño de maniquí más amplio sino un control inteligente sobre la dificultad de los datos de entrenamiento, la multiplicidad de muestreo y la largura de la inferencia. Polaris ofrece una récipe reproducible que sintoniza efectivamente estos fundamentos, lo que permite que los modelos más pequeños rivalicen la capacidad de razonamiento de los sistemas comerciales masivos.
Mira el Maniquí y Código. Todo el crédito por esta investigación va a los investigadores de este tesina. Adicionalmente, siéntete excarcelado de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.
Nikhil es consejero interno en MarktechPost. Está buscando un doble jerarquía integrado en materiales en el Instituto Indio de Tecnología, Kharagpur. Nikhil es un entusiasta de AI/ML que siempre está investigando aplicaciones en campos como biomateriales y ciencias biomédicas. Con una sólida experiencia en la ciencia material, está explorando nuevos avances y creando oportunidades para contribuir.
