
Presentación
El problema del empaquetado de contenedores es un desafío clásico de optimización que tiene implicaciones de desprendido envergadura para las organizaciones empresariales de todos los sectores. En esencia, el problema se centra en encontrar la forma más efectivo de empaquetar un conjunto de objetos en un número finito de contenedores o «contenedores», con el objetivo de minimizar el espacio desperdiciado.
Este desafío es generalizado en las aplicaciones del mundo vivo, desde la optimización de envíos y abastecimiento hasta la asignación efectivo de capital en centros de datos y entornos de computación en la abundancia. Hexaedro que las organizaciones suelen manejar grandes cantidades de artículos y contenedores, encontrar soluciones de embalaje óptimas puede difundir ahorros de costos y eficiencias operativas importantes.
Para un importante fabricante de equipos industriales valorado en 10.000 millones de dólares, el embalaje en contenedores es una parte integral de su cautiverio de suministro. Es habitual que esta empresa envíe contenedores a los proveedores para que los llenen con piezas compradas que luego se utilizan en el proceso de fabricación de equipos pesados y vehículos. Con la creciente complejidad de las cadenas de suministro y los objetivos de producción variables, el equipo de ingeniería de embalaje necesitaba certificar que las líneas de montaje tuvieran la cantidad correcta de piezas disponibles y, al mismo tiempo, utilizaran el espacio de forma efectivo.
Por ejemplo, una tendencia de montaje necesita tener a mano suficientes pernos de espada para que la producción nunca disminuya, pero es un desperdicio de espacio en la planta tener un contenedor de remisión atiborrado de ellos cuando solo se necesitan unas pocas docenas por día. El primer paso para resolver este problema es el empaquetado en contenedores, o modelar cómo encajan miles de piezas en todos los contenedores posibles, de modo que los ingenieros puedan automatizar el proceso de selección de contenedores para mejorar la productividad.
| Desafío ❗Espacio desperdiciado en contenedores de embalaje ❗Carga excesiva de camiones y huella de carbono |
Objetivo ✅ Minimizar el espacio hueco en el contenedor del embalaje ✅ Maximizar la capacidad de carga de los camiones para ceñir la huella de carbono |
|---|---|
 |
 |
Desafíos técnicos
Si correctamente el problema del empaquetamiento de contenedores se ha estudiado ampliamente en un entorno escolar, simularlo y resolverlo de forma efectivo en conjuntos de datos complejos del mundo vivo y a escalera sigue siendo un desafío para muchas organizaciones.
En cierto sentido, este problema es lo suficientemente simple como para que cualquiera lo entienda: poner cosas en una caja hasta que se llene. Pero, como sucede con la mayoría de los problemas de big data, surgen desafíos adecuado a la gran escalera de los cálculos que se deben realizar. Para la simulación de empaquetado de contenedores de este cliente de Databricks, podemos usar un maniquí mental simple para la tarea de optimización. Usando pseudocódigo:
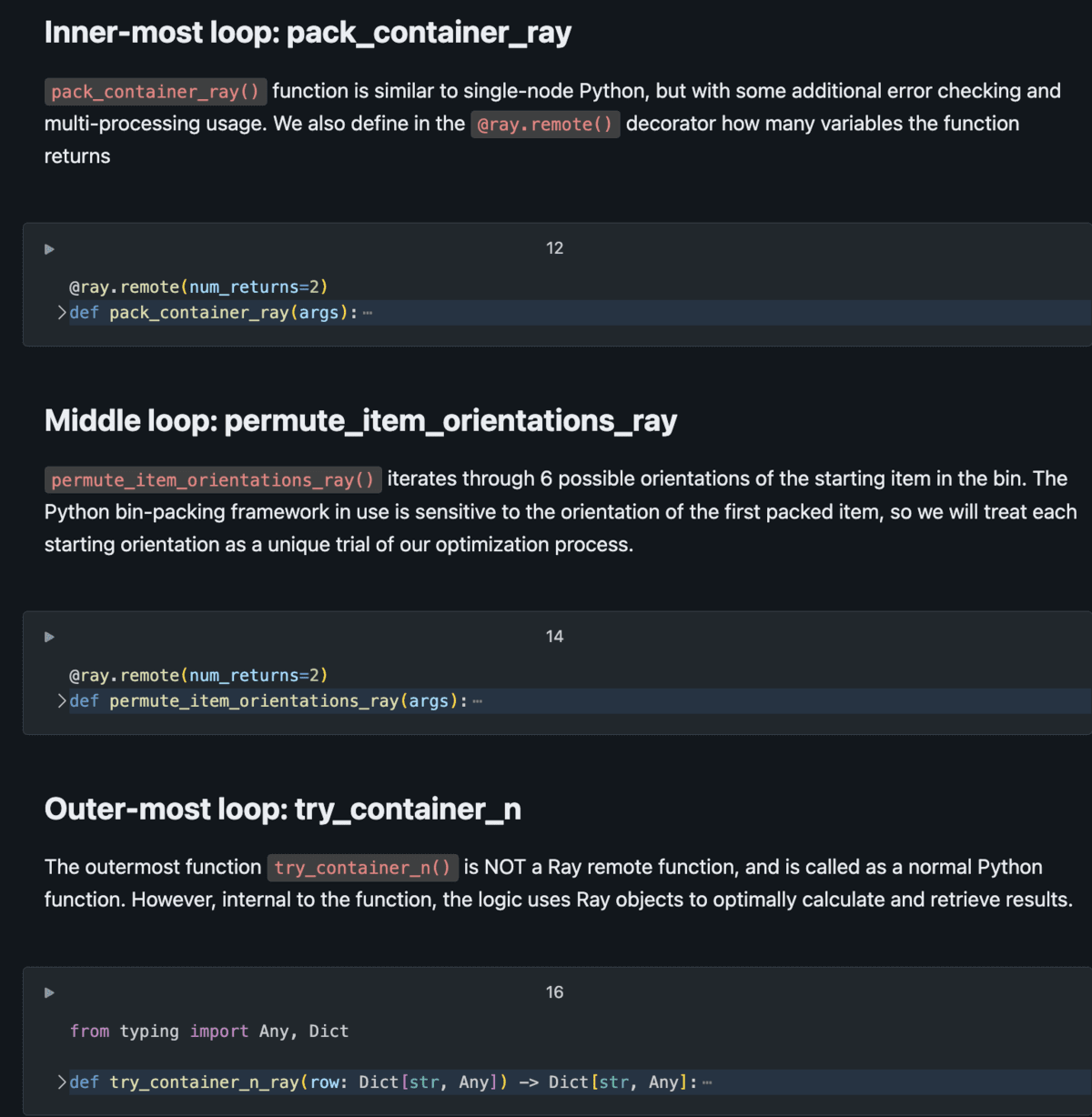
For (i in items): The process needs to run for every item in inventory (~1,000’s)
↳ For (c in containers): Try the fit for every type of container (~10’s)
↳ For (o in orientations): The starting orientations of the first item must each be modeled (==6)
↳ Pack_container Finally, try filling a container with items with a starting orientation¿Qué sucedería si ejecutáramos este proceso de caracolillo de forma secuencial utilizando Python de un solo nodo? Si tenemos millones de iteraciones (por ejemplo, 20 000 fundamentos x 20 contenedores x 6 orientaciones iniciales = 2,4 millones de combinaciones), esto podría arrostrar cientos de horas de cálculo (por ejemplo, 2,4 millones de combinaciones x 1 segundo cada una / 3600 segundos por hora = ~660 horas = 27 días). Esperar casi un mes para obtener estos resultados, que son en sí mismos una entrada para un paso de modelado posterior, es insostenible: debemos encontrar una forma más efectivo de calcular en lado de un proceso serial/secuencial.
Computación científica con Ray
Como plataforma informática, Databricks siempre ha brindado soporte para estos casos de uso de computación científica, pero escalarlos plantea un desafío: la mayoría de las bibliotecas de optimización y simulación están escritas asumiendo un entorno de procesamiento de un solo nodo, y escalarlas con Spark requiere experiencia con herramientas como Pandas UDF.
Con Ray Disponibilidad común en Databricks A principios de 2024, los clientes tendrán una nueva utensilio en su caja de herramientas de computación científica para prosperar problemas de optimización complejos. Si correctamente asimismo admite capacidades de IA avanzadas como educación de refuerzo y ML distribuido, este blog se centra en Núcleo de rayos para mejorar los flujos de trabajo personalizados de Python que requieren anidación, orquestación compleja y comunicación entre tareas.
Modelado de un problema de empaquetado de contenedores
Para utilizar Ray de forma eficaz para prosperar la computación científica, el problema debe ser lógicamente paralelizable. Es opinar, si se puede modelar un problema como una serie de simulaciones o ensayos simultáneos que se deben ejecutar, Ray puede ayudar a escalarlo. El empaquetamiento de contenedores es ideal para esto, ya que se pueden probar diferentes fundamentos en diferentes contenedores en diferentes orientaciones, todo al mismo tiempo. Con Ray, este problema de empaquetamiento de contenedores se puede modelar como un conjunto de funciones remotas anidadas, lo que permite ejecutar miles de ensayos simultáneos de forma simultánea, con el graduación de paralelismo circunscrito por la cantidad de núcleos en un clúster.
El diagrama a continuación demuestra la configuración básica de este problema de modelado.

El script de Python consta de tareas anidadas, donde las tareas externas llaman a las tareas internas varias veces por iteración. Al usar tareas remotas (en lado de las funciones normales de Python), tenemos la capacidad de distribuir masivamente estas tareas en el clúster con Ray Core administrando el descriptivo de ejecución y devolviendo resultados de forma efectivo. Vea el acelerador de soluciones de Databricks computación científica ray on spark para obtener detalles completos de implementación.
Rendimiento y resultados
Con las técnicas descritas en este blog y demostradas en el repositorio de Github asociadoEste cliente pudo:
- Disminuir el tiempo de selección de contenedores: La prohijamiento del cálculo de empaquetado de contenedores 3D marca un avance significativo, ofreciendo una alternativa que no solo es más precisa sino asimismo considerablemente más rápida, reduciendo el tiempo requerido para la selección de contenedores en un multiplicador de 40x en comparación con los procesos tradicionales.
- Avanzar el proceso linealmente: Con Ray, el tiempo necesario para finalizar el proceso de modelado se puede prosperar linealmente con la cantidad de núcleos en nuestro clúster. Si tomamos el ejemplo con 2,4 millones de combinaciones desde en lo alto (que habrían llevado 660 horas para completarse en un solo hilo), si queremos que el proceso se ejecute durante la tinieblas en 12 horas, necesitamos: 2,4 millones / (12 h x 3600 s) = 56 núcleos; para completarlo en 3 horas, necesitaríamos 220 núcleos. En Databricks, esto se controla fácilmente a través de una configuración de clúster.
- Disminuir significativamente la complejidad del código: Ray simplifica la complejidad del código y ofrece una alternativa más intuitiva a la tarea de optimización llamativo creada con las bibliotecas de subprocesamiento y multiprocesamiento de Python. La implementación mencionado requería un conocimiento enredado de estas bibliotecas adecuado a las estructuras lógicas anidadas. Por el contrario, el enfoque de Ray simplifica la saco de código y la hace más accesible para los miembros del equipo de datos. El código resultante no solo es más sencillo de comprender, sino que asimismo se alinea más estrechamente con las prácticas idiomáticas de Python, lo que perfeccionamiento la capacidad de mantenimiento y la eficiencia generales.
Extensibilidad para computación científica
La combinación de automatización, procesamiento por lotes y selección optimizada de contenedores ha generado mejoras mensurables para este fabricante industrial, incluida una reducción significativa en los costos de remisión y embalaje, y un aumento espectacular en la eficiencia del proceso. Una vez resuelto el problema del embalaje en contenedores, los miembros del equipo de datos están pasando a otros dominios de la computación científica para su negocio, incluidos los desafíos centrados en la optimización y la programación directo. Las capacidades que ofrece la plataforma Databricks Lakehouse ofrecen una oportunidad no solo de modelar nuevos problemas comerciales por primera vez, sino asimismo de mejorar drásticamente las técnicas de computación científica heredadas que se han utilizado durante abriles.
Adyacente con Spark, el habitual de facto para tareas paralelas de datos, Ray puede ayudar a que cualquier problema de “paralelismo racional” sea más efectivo. Los procesos de modelado que dependen exclusivamente de la cantidad de cuenta adecuado son una utensilio poderosa para que las empresas creen negocios basados en datos.
Vea el acelerador de soluciones Databricks computación científica ray on spark.