
¿Por qué LLMS secuenciales golpean un cuello de botella?
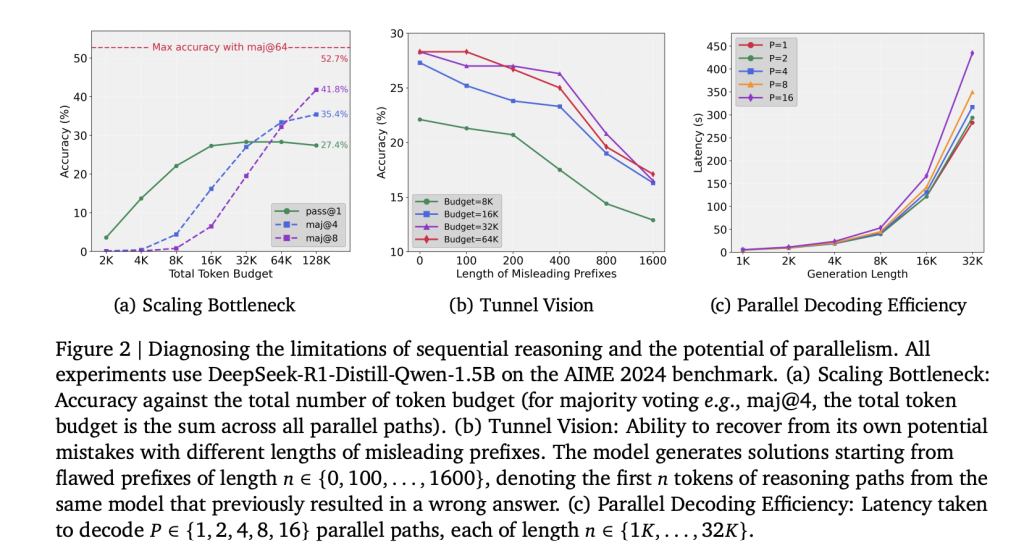
La escalera de enumeración de tiempo de prueba en LLMS se ha basado tradicionalmente en extender rutas de razonamiento individuales. Si admisiblemente este enfoque prosperidad el razonamiento para un rango menguado, el rendimiento se vienta rápidamente. Los experimentos sobre Deepseek-R1-Distill-Qwen-1.5b muestran que el aumento de los presupuestos de tokens más allá de 32k (hasta 128k) produce ganancias de precisión insignificantes. El cuello de botella surge de Compromiso de token tempranodonde los errores iniciales se propagan a través de toda la condena de pensamiento. Este intención, denominado Visión del túnel, indica que el problema de escalera es metodológico más que un final fundamental de la capacidad del maniquí.
Visión del túnel y cómo se diagnostica?
Los investigadores cuantificaron la capacidad de recuperación al forzar modelos a continuar con prefijos erróneos de longitudes variables (100-1600 tokens). La precisión disminuyó monotónicamente a medida que aumentaba la largo del prefijo, lo que demuestra que una vez comprometido con una trayectoria defectuosa, el maniquí no puede recuperarse, incluso cuando se le da un presupuesto de cálculo adicional. Esto confirma que la escalera secuencial asigna calculadora de modo ineficiente.
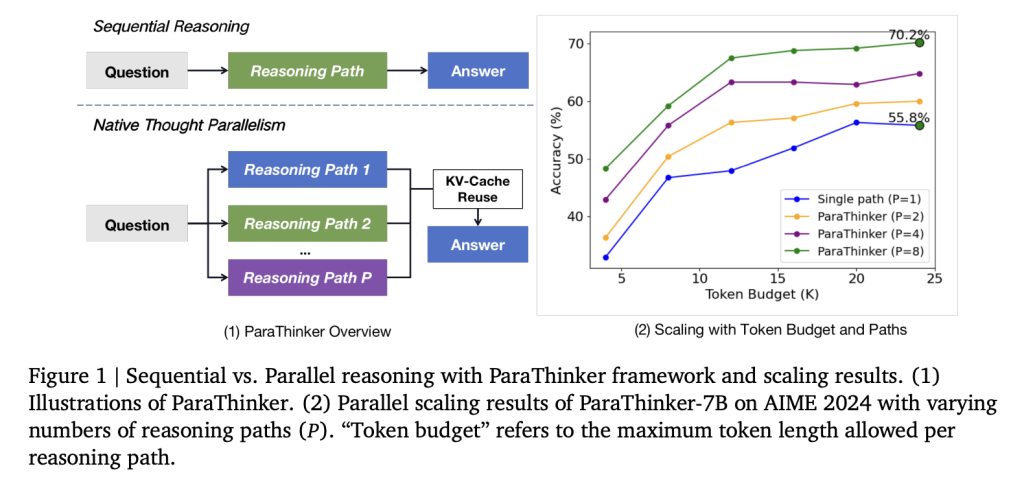
¿Cómo introduce Parathinker el pensamiento paralelo?
Un equipo de investigadores de la Universidad de Tsinghua presentan a Parathinker, un situación de extremo a extremo que entrena a un LLM para difundir múltiples y diversas rutas de razonamiento en paralelo y sintetizarlos en una respuesta final superior. Parathinker operacionaliza Paralelismo del pensamiento nativo Al difundir múltiples trayectorias de razonamiento en paralelo y fusionarlas en una respuesta final.
Los componentes arquitectónicos esencia incluyen:
- Tokens de control especializados (
- Incruscaciones posicionales específicas de la consejo para desambiguar los tokens a través de las rutas y evitar el colapso durante el extracto.
- Máscaras de atención en dos fases Hacer cumplir la independencia de la ruta durante el razonamiento y la integración controlada durante la vivientes de respuestas.
Una lucro de eficiencia crítica proviene de la reutilización Caches KV Desde la etapa de razonamiento en la período de extracto, eliminando la reorganización redundante.
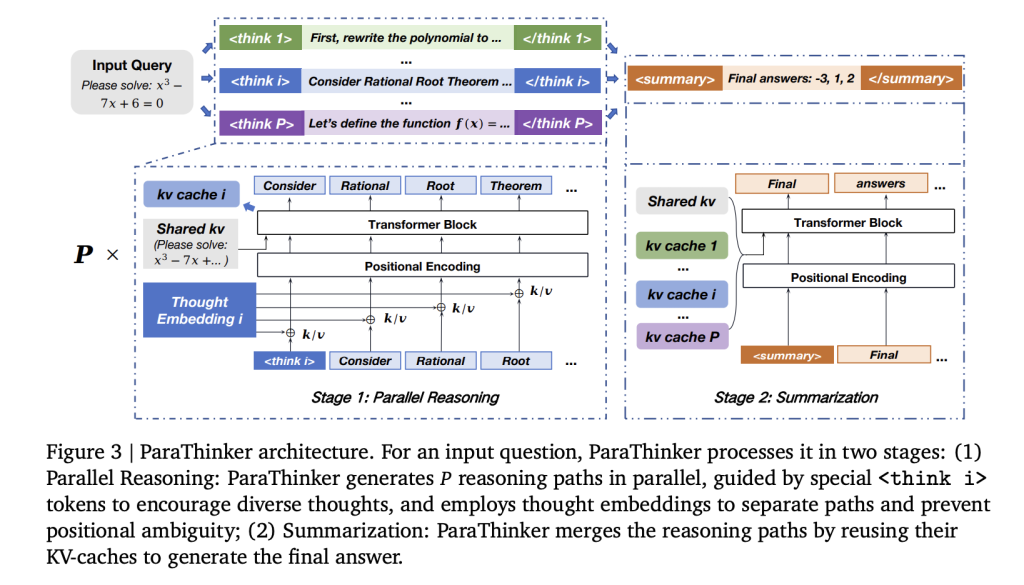
¿Cómo se entrena a Parathinker para el razonamiento paralelo?
El ajuste fino (SFT) supervisado se realizó utilizando conjuntos de datos de razonamiento de múltiples rutas. Los datos de capacitación se construyeron muestreando múltiples rutas de soluciones de modelos de maestros (Deepseek-R1, GPT-OSS-20B). Cada ejemplo incluyó varios
El ajuste fino utilizó modelos QWEN-2.5 (parámetros 1.5B y 7B), con tokens de 28k de largo máxima de largo de contexto. Las fuentes de datos incluyeron Open-R1, Deepmath, S1K y Limo, complementado con soluciones adicionales muestreadas a temperatura 0.8. El entrenamiento se ejecutó en múltiples GPU A800.
¿Cuáles son los resultados experimentales?
La evaluación en AIME 2024, AIME 2025, AMC 2023 y Math-500 produce lo posterior:
- Exactitud:
- 1,5B Parathinker rematado +12.3% de precisión sobre líneas de colchoneta secuenciales y +4.3% sobre la mayoría de votación.
- 7b Parathinker rematado +7.5% de precisión sobre secuencial y +2.0% sobre la mayoría de votación.
- Con 8 rutas de razonamiento, Parathinker-1.5b alcanzó 63.2% pase@1excediendo modelos secuenciales 7B en presupuestos equivalentes.
- Eficiencia:
- La latencia sobrecarga del razonamiento paralelo fue 7.1% de término medio.
- Crear 16 rutas fue inferior a 2 × la latencia de difundir una sola ruta conveniente a una mejor utilización de la memoria de GPU.
- Organización de terminación: El Primer rematado Enfoque, donde el razonamiento termina cuando el primer camino termina, superó las estrategias de última hora y medio final tanto en precisión como de latencia.
¿Qué indican los estudios de separación?
- Ajuste de datos de datos (sin modificaciones de Parathinker) no logró mejorar el rendimiento, confirmando que las ganancias se derivan de las innovaciones arquitectónicas en circunstancia de los datos de capacitación solo.
- Eliminar incrustaciones de pensamiento La precisión corta, mientras que las codificaciones aplanadas ingenuas causaron una degradación severa conveniente a la descomposición posicional de generoso talento.
- Reorganizar las líneas de colchoneta Degradado a medida que aumentó el número de rutas, validando los beneficios computacionales de la reutilización de KV-Cache.
¿Cómo se compara Parathinker con otros métodos?
Las estrategias paralelas convencionales, como la votación mayoritaria, la autoconsistencia y el árbol de los pensamientos, requieren verificadores externos o selección post-hoc, limitando la escalabilidad. Los métodos de token-paralelo basados en difusión funcionan mal en las tareas de razonamiento conveniente a la dependencia secuencial. Enfoques arquitectónicos como la parcala demandan los cambios estructurales y el preadoo. En contraste, Parathinker conserva la columna vertebral del transformador e introduce el paralelismo en la etapa de razonamiento, integrando múltiples cachés de KV en un paso de extracto unificado.
Síntesis
Parathinker demuestra que los cuellos de botella de escalera en el tiempo de prueba son un artefacto de estrategias de razonamiento secuencial. Asignando enumeración a través de ufano (trayectorias paralelas) en circunstancia de profundidad (cadenas más largas), los modelos más pequeños pueden exceder las líneas de colchoneta significativamente más grandes con una sobrecarga de latencia mínima. Esto establece Paralelismo del pensamiento nativo Como una dimensión crítica para la escalera futura de LLM.
Mira el Papel aquí. No dude en ver nuestro Página de Github para tutoriales, códigos y cuadernos. Por otra parte, siéntete librado de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.

Michal Sutter es un profesional de la ciencia de datos con una Destreza en Ciencias en Ciencias de Datos de la Universidad de Padova. Con una colchoneta sólida en observación estadístico, enseñanza maquinal e ingeniería de datos, Michal se destaca por transfigurar conjuntos de datos complejos en ideas procesables.