
Nos complace anunciar que se pueden realizar bucles para tareas en flujos de trabajo de Databricks con Para cada uno ¡Ahora está disponible de manera basic! Este nuevo tipo de tarea facilita más que nunca la automatización de tareas repetitivas al realizar un bucle sobre un conjunto dinámico de parámetros definidos en tiempo de ejecución y es parte de nuestra inversión continua en Funciones de flujo de management mejoradas en Flujos de trabajo de Databricks. Con Para cada unoPuede optimizar la eficiencia y la escalabilidad del flujo de trabajo, liberando tiempo para centrarse en los conocimientos en lugar de en la lógica compleja.
Los bucles mejoran drásticamente el manejo de tareas repetitivas
La gestión de flujos de trabajo complejos suele implicar la gestión de tareas repetitivas que requieren el procesamiento de múltiples conjuntos de datos o la realización de múltiples operaciones. Las herramientas de orquestación de datos que no admiten bucles presentan varios desafíos.
Simplificando la lógica compleja
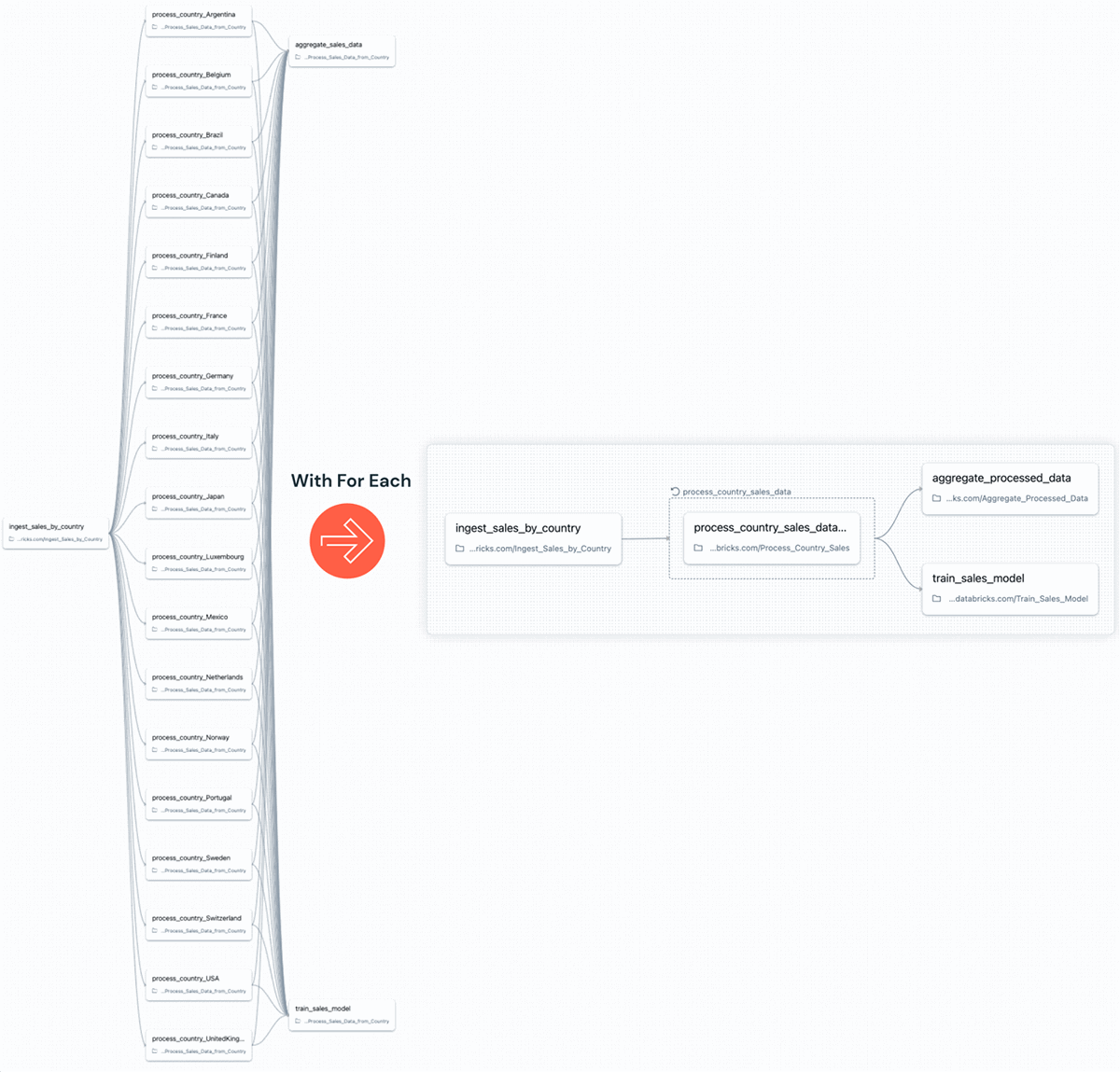
Anteriormente, los usuarios solían recurrir a una lógica guide y difícil de mantener para gestionar tareas repetitivas (ver más arriba). Esta solución alternativa suele implicar la creación de una única tarea para cada operación, lo que sobrecarga el flujo de trabajo y es propenso a errores.
Con For Every, la lógica complicada que se requería anteriormente se simplifica enormemente. Los usuarios pueden definir fácilmente bucles dentro de sus flujos de trabajo sin recurrir a scripts complejos para ahorrar tiempo de creación. Esto no solo agiliza el proceso de configuración de flujos de trabajo, sino que también scale back la posibilidad de errores, lo que hace que los flujos de trabajo sean más fáciles de mantener y eficientes. En el siguiente ejemplo, los datos de ventas de 100 países diferentes se procesan antes de la agregación con los siguientes pasos:
- Ingestión de datos de ventas,
- Procesamiento de datos de los 100 países utilizando For Every
- Agregar los datos y entrenar un modelo de ventas.
Mayor flexibilidad con parámetros dinámicos
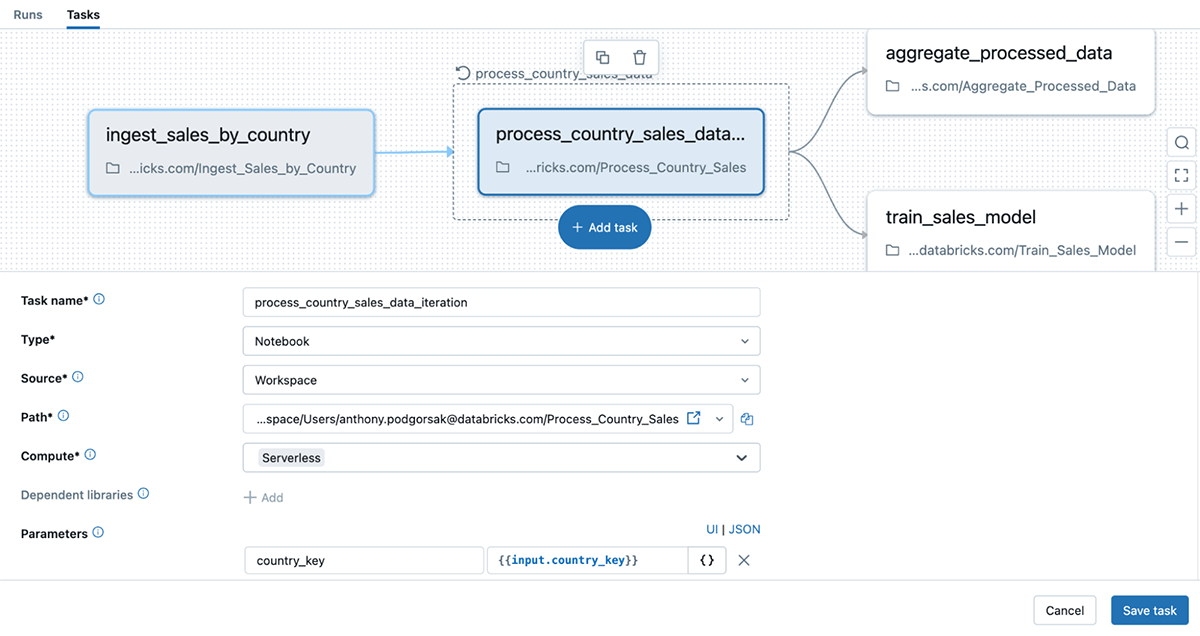
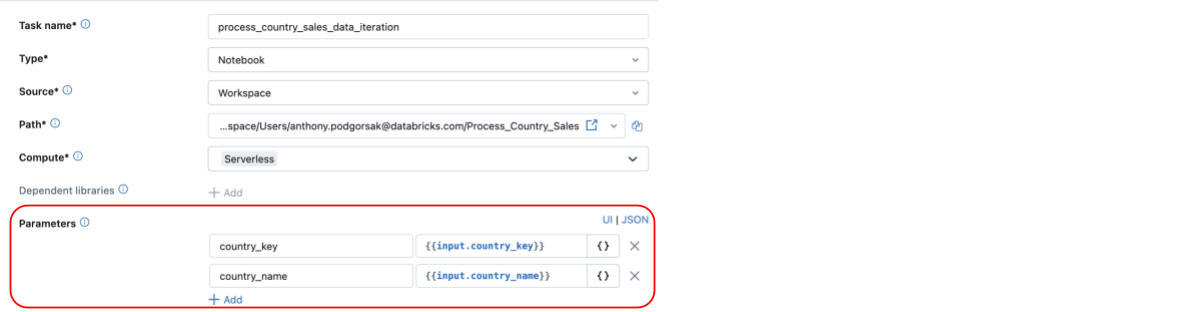
Sin For Every, los usuarios están limitados a escenarios en los que los parámetros no cambian con frecuencia. Con For Every, la flexibilidad de los flujos de trabajo de Databricks se mejora significativamente a través de la capacidad de realizar un bucle sobre parámetros totalmente dinámicos definidos en tiempo de ejecución con valores de la tarealo que scale back la necesidad de codificación rígida. A continuación, vemos que los parámetros de la tarea del cuaderno se definen dinámicamente y se pasan al bucle For Every (también puede notar que utiliza Computación sin servidor, ahora disponible de manera basic!).
Procesamiento eficiente con concurrencia
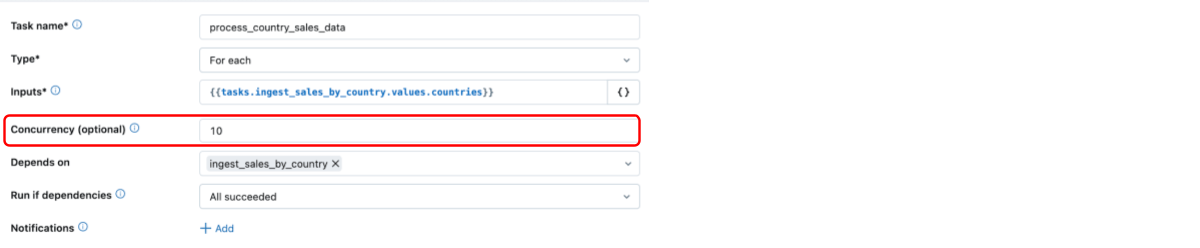
Para cada uno se apoya computación verdaderamente concurrentelo que lo distingue de otras herramientas de orquestación importantes. Con For Every, los usuarios pueden especificar cuántas tareas se ejecutarán en paralelo, lo que mejora la eficiencia al reducir el tiempo de ejecución de principio a fin. A continuación, vemos que la concurrencia del bucle For Every está establecida en 10, con soporte para hasta 100 bucles simultáneos. De forma predeterminada, la concurrencia está establecida en 1 y las tareas se ejecutan de forma secuencial.
Depurar con facilidad
La depuración y el monitoreo de flujos de trabajo se vuelven más difíciles sin soporte de bucles. Los flujos de trabajo con una gran cantidad de tareas pueden ser difíciles de depurar, lo que scale back el tiempo de actividad.
Secundario refacción Dentro de For Every, la depuración y el monitoreo son mucho más fluidos. Si una o más iteraciones fallan, solo se volverán a ejecutar las iteraciones fallidas, no todo el bucle. Esto ahorra costos de procesamiento y tiempo, lo que facilita el mantenimiento de flujos de trabajo eficientes. La visibilidad mejorada de la ejecución del flujo de trabajo permite una resolución de problemas más rápida y scale back el tiempo de inactividad, lo que en última instancia mejora la productividad y garantiza información oportuna. A continuación, se muestra el resultado remaining del ejemplo anterior.
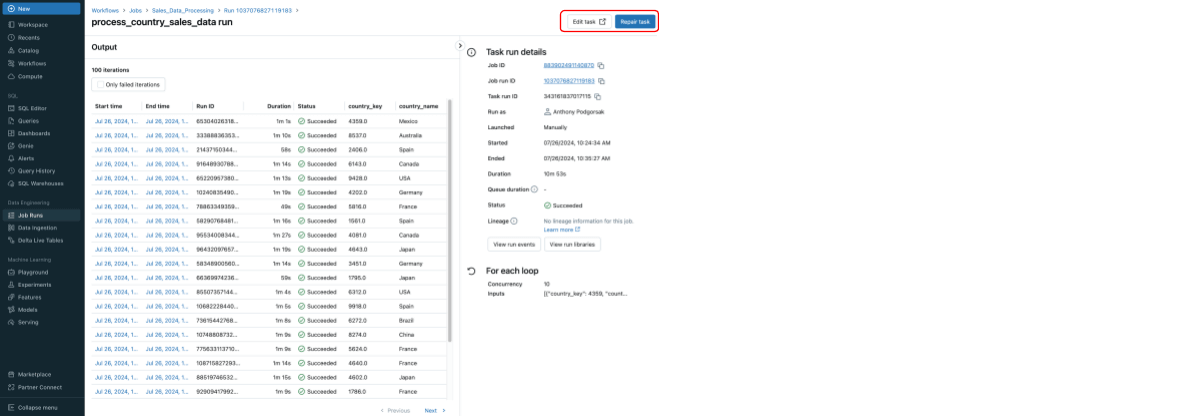
Estas mejoras amplían aún más el amplio conjunto de capacidades que ofrece Databricks Workflows para la orquestación en la Plataforma de Inteligencia de Datos, mejorando drásticamente la experiencia del usuario y haciendo que los flujos de trabajo de los clientes sean más eficientes, flexibles y manejables.
Empezar
¡Estamos muy emocionados de ver cómo usas For Every para optimizar tus flujos de trabajo y potenciar tus operaciones de datos!
Para obtener más información sobre los diferentes tipos de tareas y cómo configurarlas en la interfaz de usuario de flujos de trabajo de Databricks, consulte el producto documentos