
Nota: A partir del 15 de julio, la integración de vectores de Amazon S3 con Amazon OpenSearch Service está en la interpretación previa y está sujeta a cambios.
La forma en que almacenamos y buscamos a través de los datos está evolucionando rápidamente con el avance de Incruscaciones vectoriales y capacidades de búsqueda de similitud. La búsqueda vectorial se ha vuelto esencial para aplicaciones modernas como la IA generativa y la IA de agente, pero la trámite de datos de vectores a escalera presenta desafíos significativos. Las organizaciones a menudo luchan con las compensaciones entre la latencia, el costo y la precisión al juntar y agenciárselas a través de millones o miles de millones de integridades vectoriales. Las soluciones tradicionales requieren una trámite sustancial de infraestructura o vienen con costos prohibitivos a medida que crecen los volúmenes de datos.
Ahora tenemos una apariencia previa pública de dos integraciones entre Vectores de Amazon Simple Storage Service (Amazon S3) y Servicio de Amazon OpenSearch que le brindan más flexibilidad en la forma en que almacena y averiguación incrustaciones de vectores:
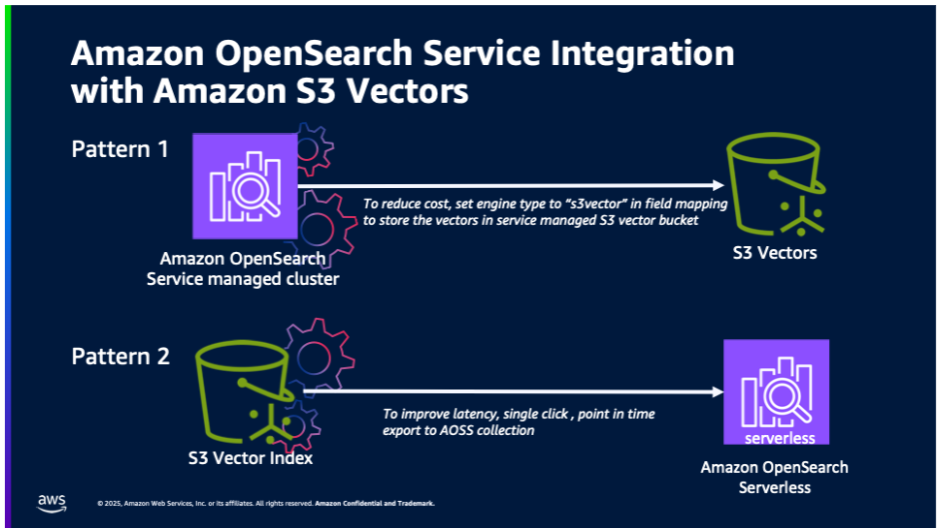
- Almacenamiento vectorial optimizado de costos: Servicio de OpenSearch grupos administrados por vectores S3 administrados por el servicio para el almacenamiento de vectores optimizados por costos. Esta integración admitirá cargas de trabajo de OpenSearch que están dispuestas a trocar una latencia más suscripción por un costo intolerante bajo y aún desean usar capacidades avanzadas de OpenSearch (como búsqueda híbrida, filtrado renovador, filtrado geográfico, etc.).
- Exportación de un solo clic de vectores S3: Exportación de un solo clic de un índice vectorial S3 a colecciones de OpenSearch sin servidor para la búsqueda de vectores de suspensión rendimiento. Los clientes que construyen de forma nativa en vectores S3 se beneficiarán de poder usar OpenSearch para un rendimiento de consulta más rápido.
Al usar estas integraciones, puede optimizar el costo, la latencia y la precisión distribuyendo inteligentemente sus cargas de trabajo vectoriales manteniendo vectores consultados poco frecuentes en vectores S3 y utilizando Opessearch para sus operaciones más sensibles al tiempo que requieren capacidades de búsqueda avanzadas como búsqueda y agregaciones híbridas. Adicionalmente, las capacidades de ajuste de rendimiento de OpenSearch (es afirmar, cuantificación, algoritmos de K-Nearest Vecin (KNN) y parámetros específicos del método) ayudan a mejorar el rendimiento con poco compromiso de costo o precisión.
En esta publicación, caminamos por esta integración perfecta, proporcionándole opciones flexibles para la implementación de búsqueda de vectores. Aprenderá cómo usar el nuevo tipo de motor S3 Tipo en los grupos administrados por el servicio OpenSearch para el almacenamiento vectorial optimizado de costos y cómo usar una exportación de un solo clic de vectores S3 para OpesSearch Collections sin servidor para escenarios de suspensión rendimiento que requieren consultas sostenidas con latencia tan descenso como 10 ms. Al final de esta publicación, comprenderá cómo nominar e implementar el patrón de integración correcto en función de sus requisitos específicos para el rendimiento, el costo y la escalera.
Descripción genérico del servicio
Amazon S3 Vectors es la primera tienda de objetos en la abundancia con soporte nativo para juntar y consultar vectores con capacidades de búsqueda sub-segunda, que no requiere trámite de infraestructura. Combina la simplicidad, la durabilidad, la disponibilidad y la rentabilidad de Amazon S3 con la funcionalidad de búsqueda de vectores nativos, por lo que puede juntar y consultar las incrustaciones de vectores directamente en S3. El servicio de Amazon OpenSearch proporciona dos opciones de implementación complementarias para cargas de trabajo vectoriales: grupos administrados y colecciones sin servidor. Tanto el arnés de Amazon OpenSearch las potentes capacidades de búsqueda y recuperación de vectores, aunque cada una sobresale en diferentes escenarios. Para los usuarios de OpenSearch, la integración entre los vectores S3 y el servicio de Amazon OpenSearch ofrece flexibilidad sin precedentes para optimizar su inmueble de búsqueda vectorial. Ya sea que necesite un rendimiento de consulta intolerante rápido para aplicaciones en tiempo efectivo o un almacenamiento rentable para conjuntos de datos vectoriales a gran escalera, esta integración le permite nominar el enfoque que mejor se adapte a su caso de uso específico.
Comprender las opciones de almacenamiento vectorial
El servicio de OpenSearch proporciona múltiples opciones para juntar y agenciárselas incrustaciones de vectores, cada una optimizada para diferentes casos de uso. El motor Lucene, que es la biblioteca de búsqueda nativa de OpenSearch, implementa la Mundo pequeño jerárquico navegable (HNSW) Método, ofreciendo capacidades de filtrado eficientes y una resistente integración con la funcionalidad central de OpenSearch. Para cargas de trabajo que requieren opciones de optimización adicionales, el Faiss Engine (búsqueda de similitud de IA de Facebook) proporciona implementaciones de entreambos Métodos de HNSW y FIV (índice de archivos invertidos)unido con capacidades de compresión vectorial. HNSW crea una estructura gráfica jerárquica de conexiones entre vectores, lo que permite una navegación capaz durante la búsqueda, mientras que la FIV organiza vectores en grupos y averiguación solo subconjuntos relevantes durante el tiempo de consulta. Con la presentación del tipo de motor S3, ahora tiene una opción rentable que utiliza la durabilidad y escalabilidad de Amazon S3 mientras mantiene el rendimiento de la consulta de subsecond. Con esta variedad de opciones, puede nominar el enfoque más adecuado en función de sus requisitos específicos para el rendimiento, el costo y la precisión. Por ejemplo, si su aplicación requiere respuestas de consulta de Sub-50 MS con filtrado capaz, la implementación de HNSW de FAISS es la mejor opción. Alternativamente, si necesita optimizar los costos de almacenamiento mientras mantiene un rendimiento bastante, el nuevo tipo de motor S3 sería más apropiado.
Descripción genérico de la alternativa
En esta publicación, exploramos dos patrones de integración primarios:
Los grupos administrados por el servicio OpenSearch utilizan vectores S3 administrados por el servicio para el almacenamiento de vectores de costo optimizado.
Para los clientes que ya utilizan los dominios de servicio OpenSearch que desean optimizar los costos mientras mantienen el rendimiento de la consulta de subsecond, el nuevo tipo de motor Amazon S3 ofrece una alternativa convincente. El servicio de OpenSearch administra automáticamente el almacenamiento vectorial en Amazon S3, la recuperación de datos y la optimización de elegancia, eliminando la sobrecarga operativa.
Exportar con un solo clic de un índice Vector S3 a OpenSearch Collections sin servidor para la búsqueda de vectores de suspensión rendimiento.
Para los casos de uso que requieren un rendimiento de consulta más rápido, puede portar sus datos vectoriales de un índice vectorial S3 a una colección OpenSearch Servidor. Este enfoque es ideal para aplicaciones que requieren tiempos de respuesta en tiempo efectivo y le brindan los beneficios que vienen con Amazon OpenSearch Servidor sin serincluyendo capacidades y filtros de consulta destacamento, escalera cibernética y suscripción disponibilidad, y sin agencia. El proceso de exportación maneja automáticamente la asignación de esquemas, la transferencia de datos vectoriales, la optimización del índice y la configuración de la conexión.
La sucesivo ilustración muestra los dos patrones de integración entre el servicio Amazon OpenSearch y los vectores S3.
Requisitos previos
Antiguamente de comenzar, asegúrese de tener:
- Una cuenta de AWS
- Camino a Amazon S3 y Amazon OpenSearch Service
- Un dominio de servicio de OpenSearch (para el primer patrón de integración)
- Datos vectoriales almacenados en vectores S3 (para el segundo patrón de integración)
Patrón de integración 1: Clúster administrado por el servicio OpenSearch utilizando vectores S3
Para implementar este patrón:
- Crear un dominio de servicio de OpenSearch usando O 1 instancias En OpenSearch interpretación 2.19.
- Mientras crea el dominio del servicio OpenSearch, Elija el Habilitar los vectores S3 como opción de motor en el Características avanzadas sección.
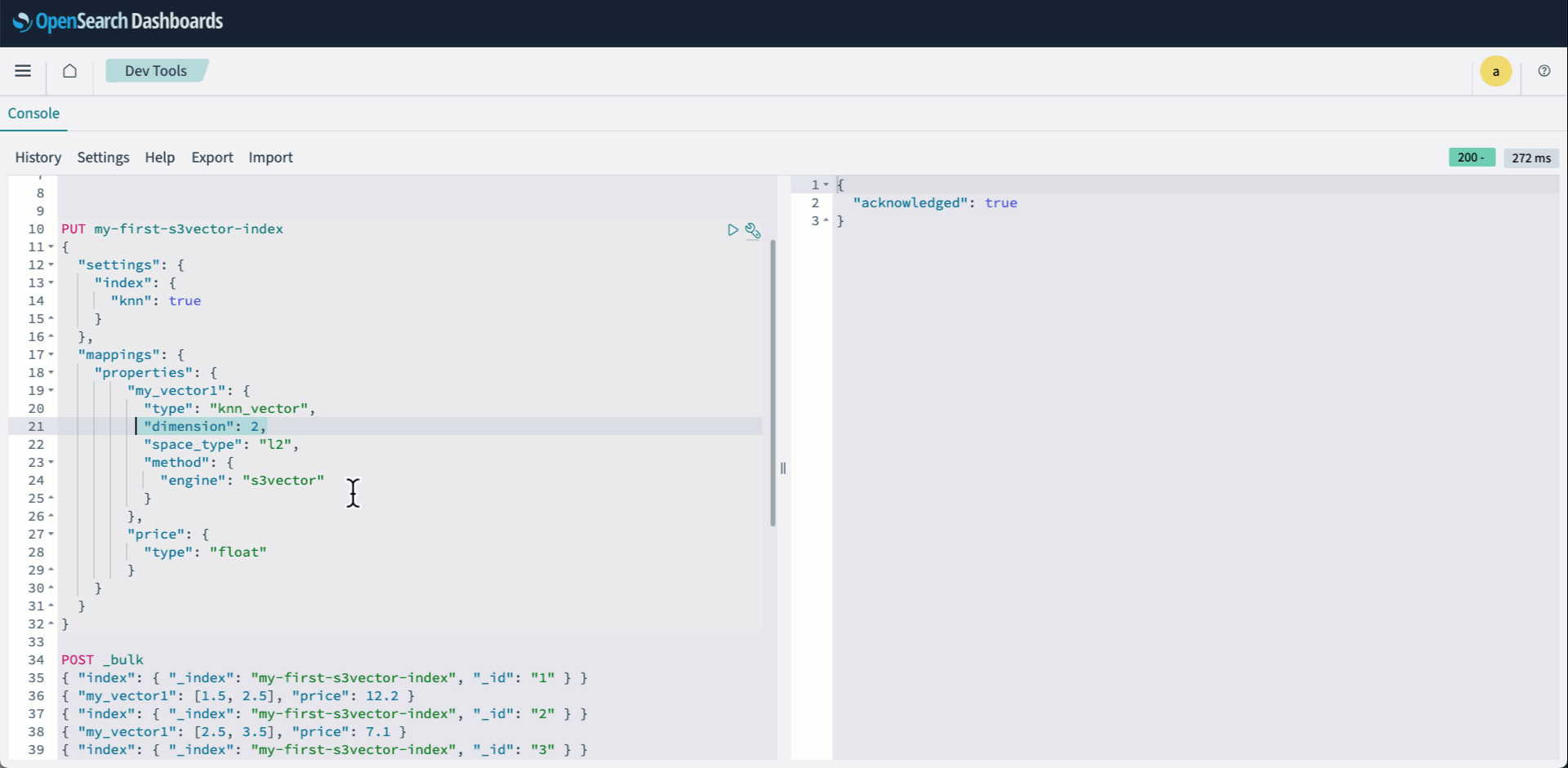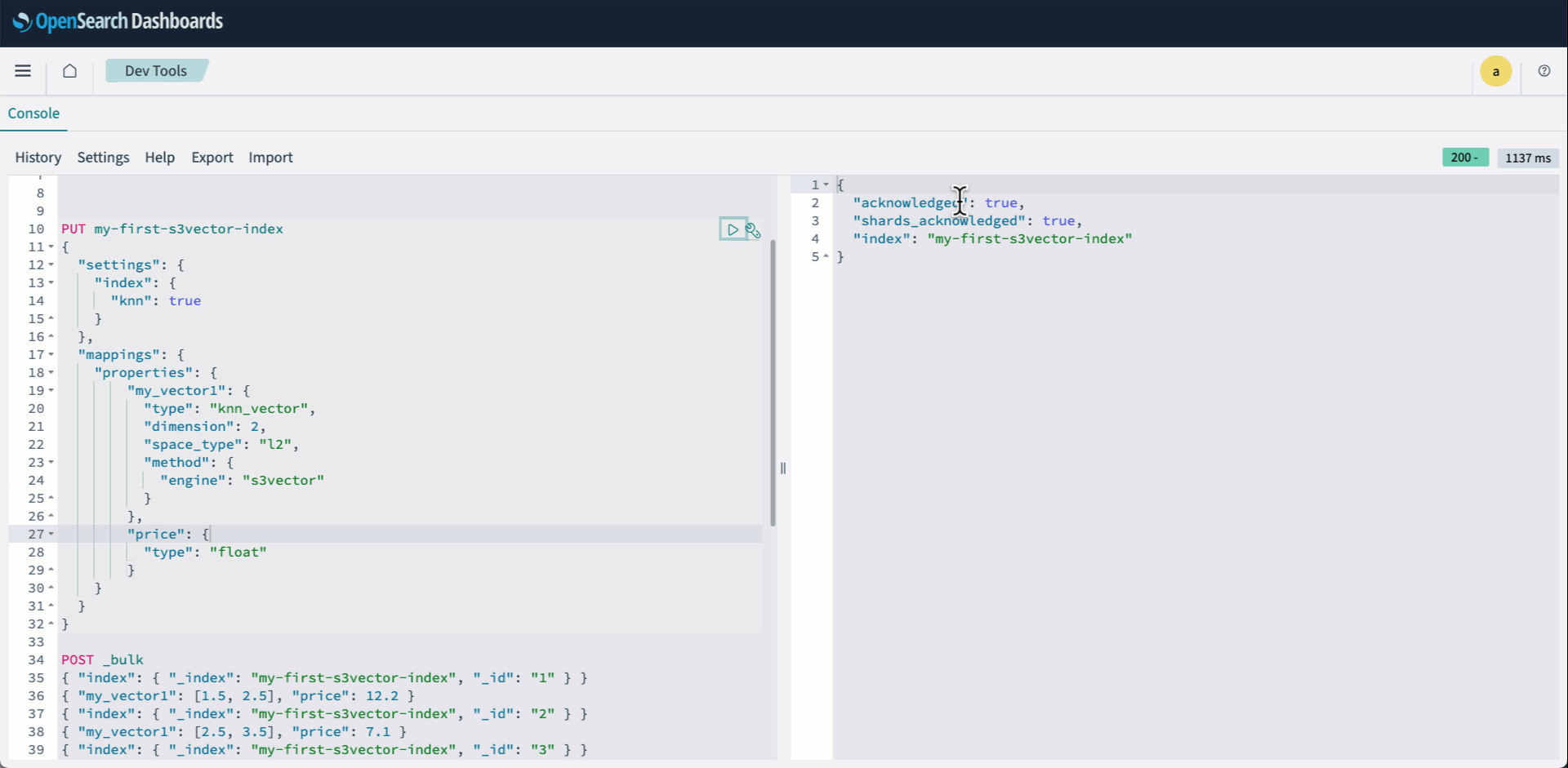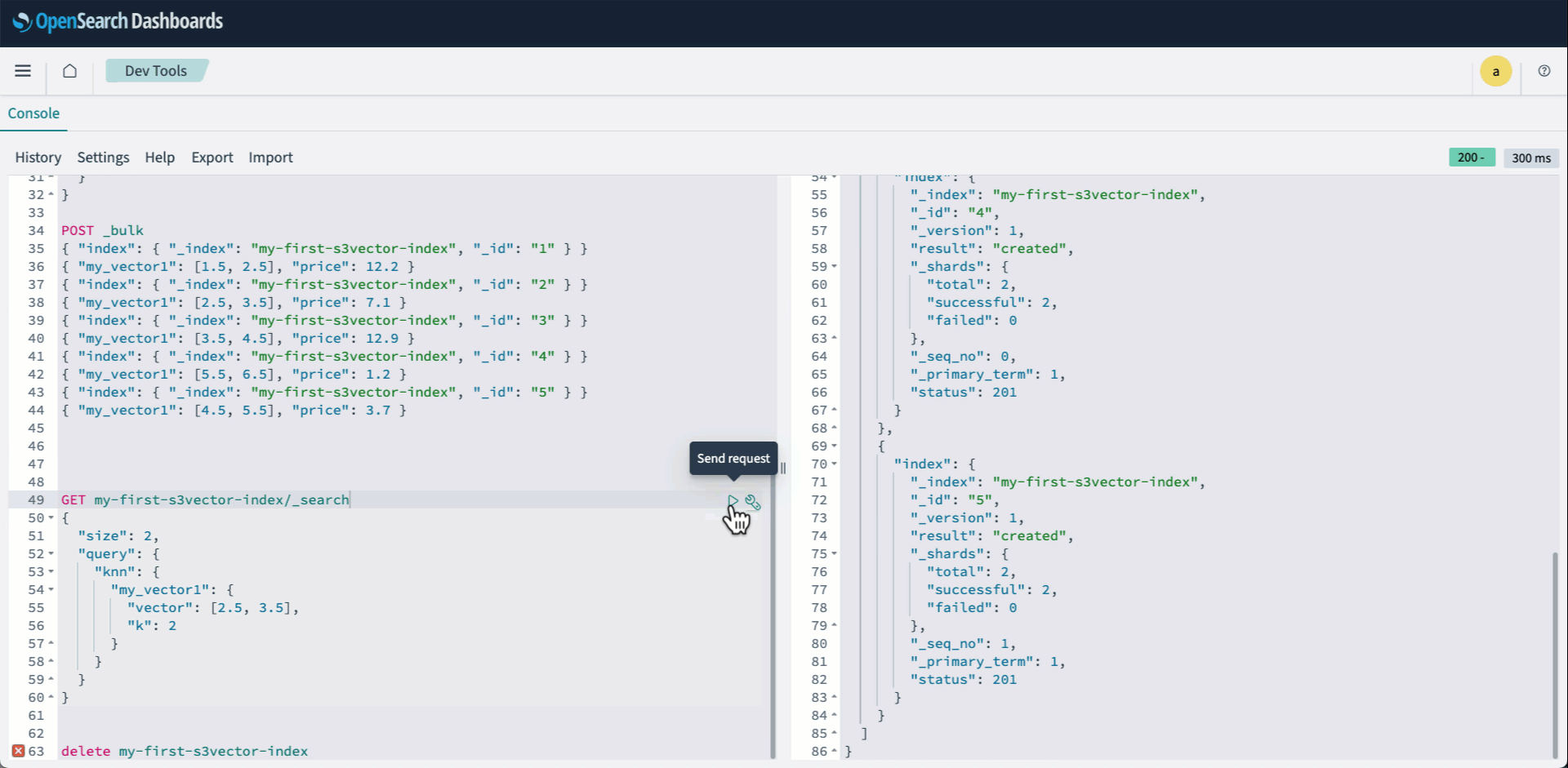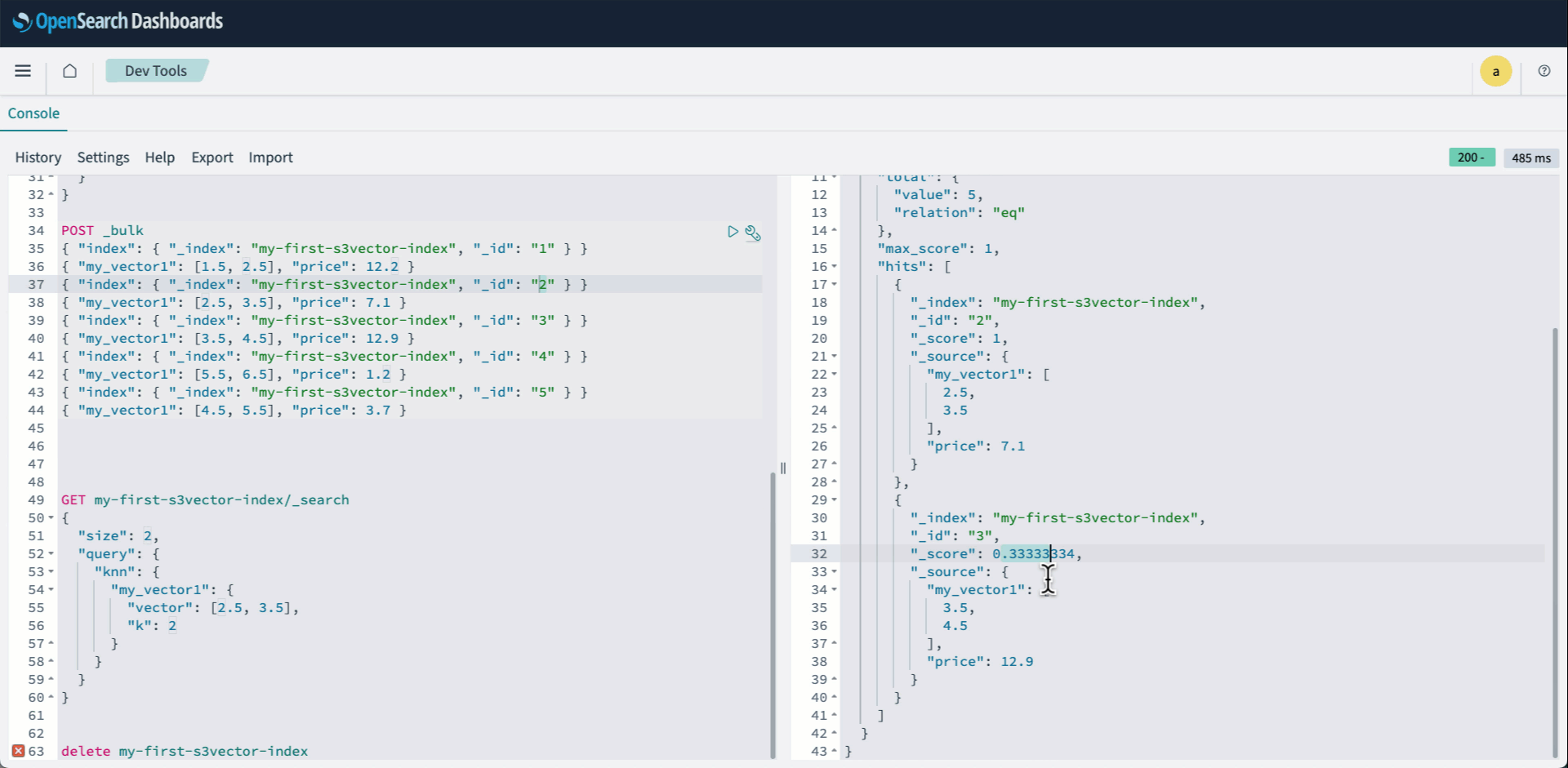
- Iniciar sesión en los paneles de OpenSearch y aclarar Herramientas de crecimiento. Luego cree su índice KNN y especifique vector s3 como el motor.
- Indexe tus vectores usando el API a abundante:
- Ejecute una consulta KNN como de costumbre:
La sucesivo animación demuestra los pasos 2-4 anteriores.
Patrón de integración 2: Exportar índices de vectores S3 a OpenSearch Servidor
Para implementar este patrón:
- Navegue a la consola de agencia de AWS para Amazon S3 y seleccione su cubo S3 Vector.
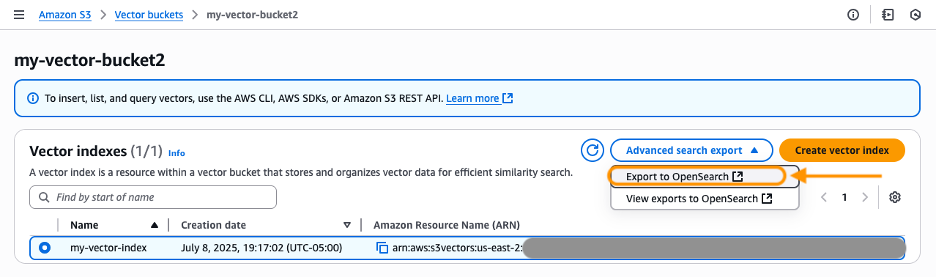
- Seleccione un índice vectorial que desee exportar. Bajo Exportación de búsqueda destacamentooptar Exportar a OpenSearch.
Alternativamente, puedes:
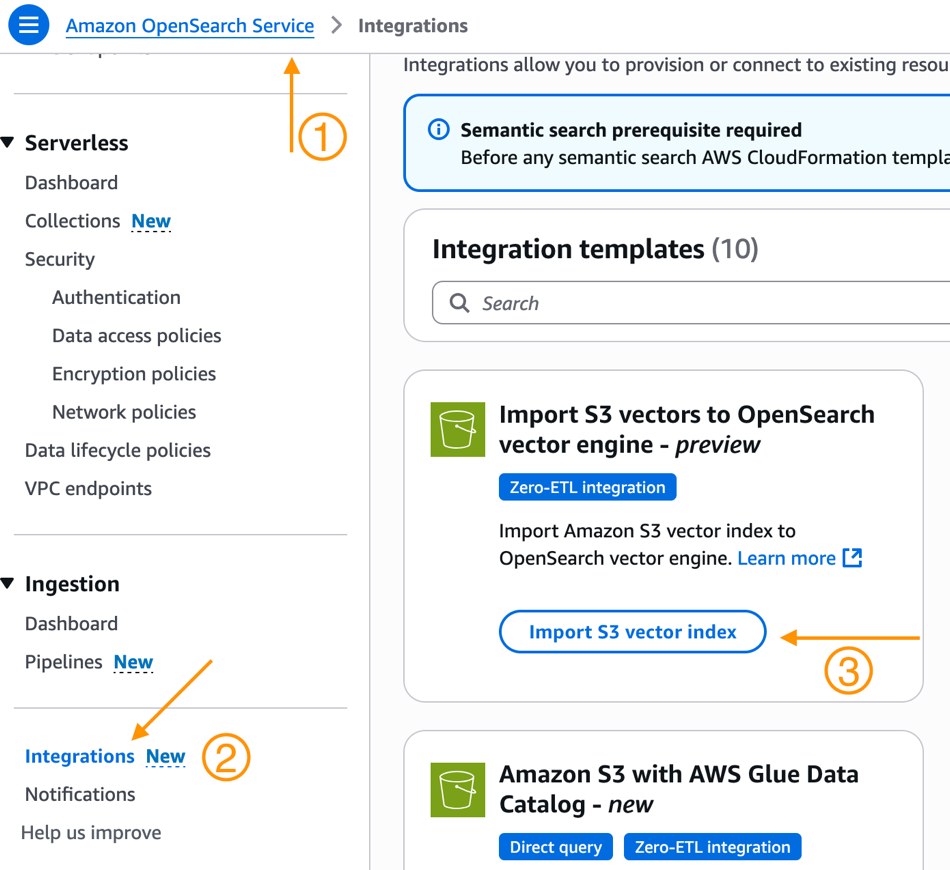
- Navegue a la consola de servicio OpenSearch.
- Separar Integración del panel de navegación.
- Aquí verá una nueva plantilla de integración para Importar vectores S3 a OpenSearch Vector Engine – avance. Separar Importar índice de vector S3.
- Ahora lo llevarán a la consola de integración de servicios de Amazon OpenSearch con el Exportar el índice vectorial S3 al motor Vector OpenSearch Plantilla preseleccionada y prepoblada con su S3 Vector Index Amazon Resource Name (ARN). Seleccione un rol existente que tenga el permisos necesarios o crear un nuevo rol de servicio.
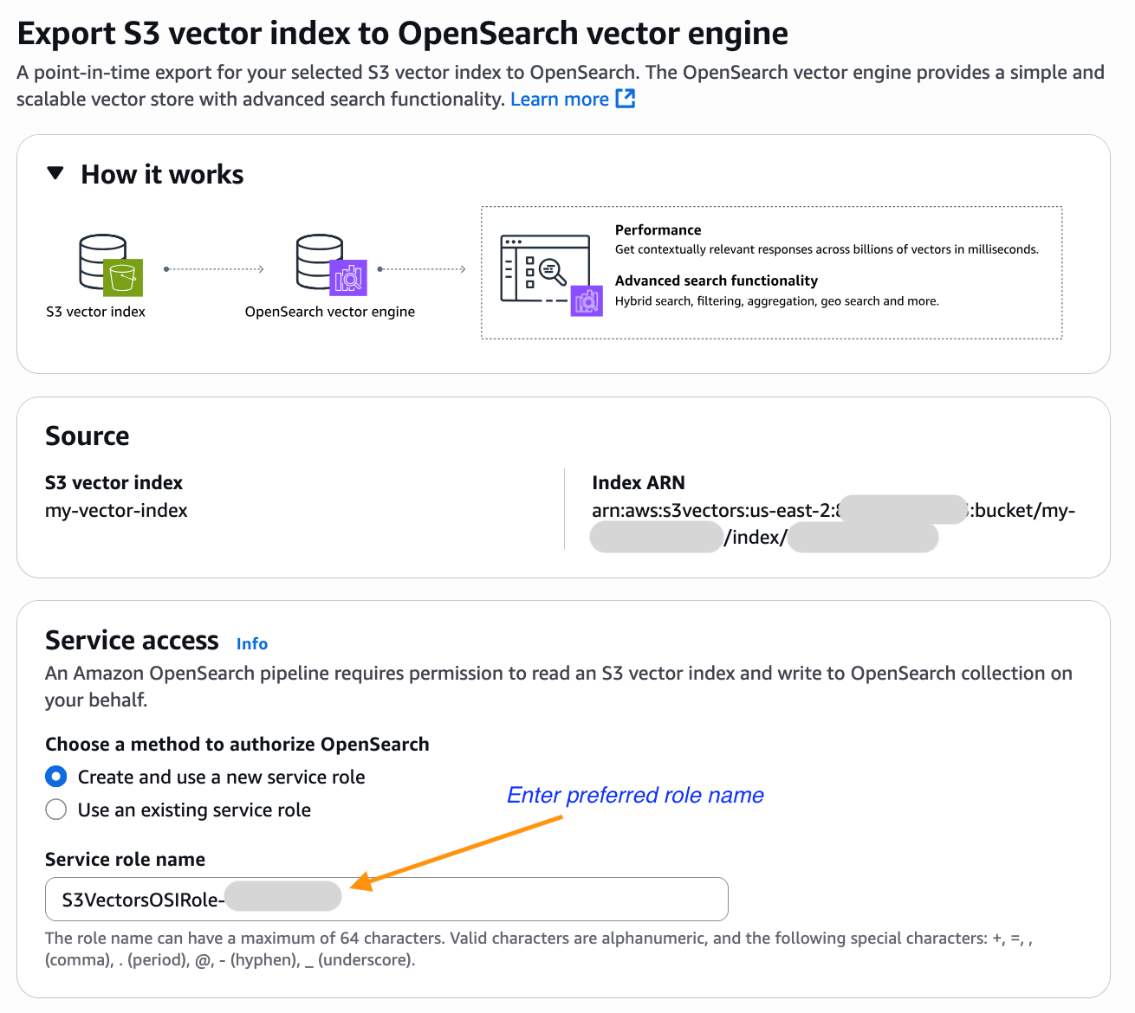
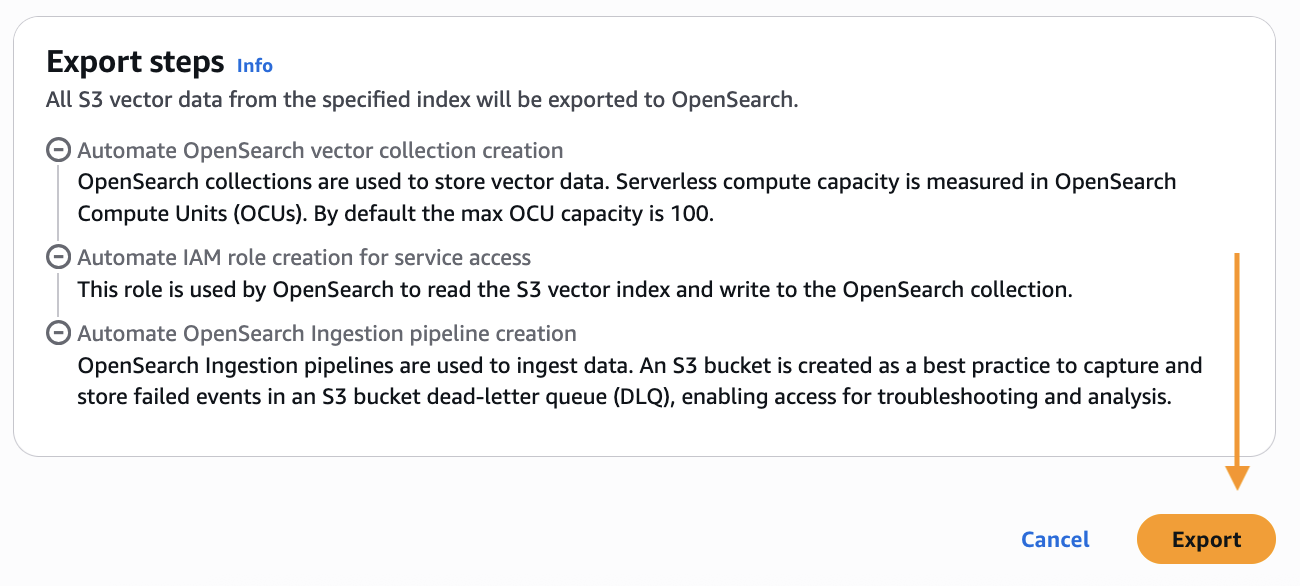
- Desplácese en dirección a debajo y elija Exportar Para iniciar los pasos para crear una nueva colección OpenSearch Servidor y copiar datos de su índice Vector S3 en un índice OpenSearch KNN.
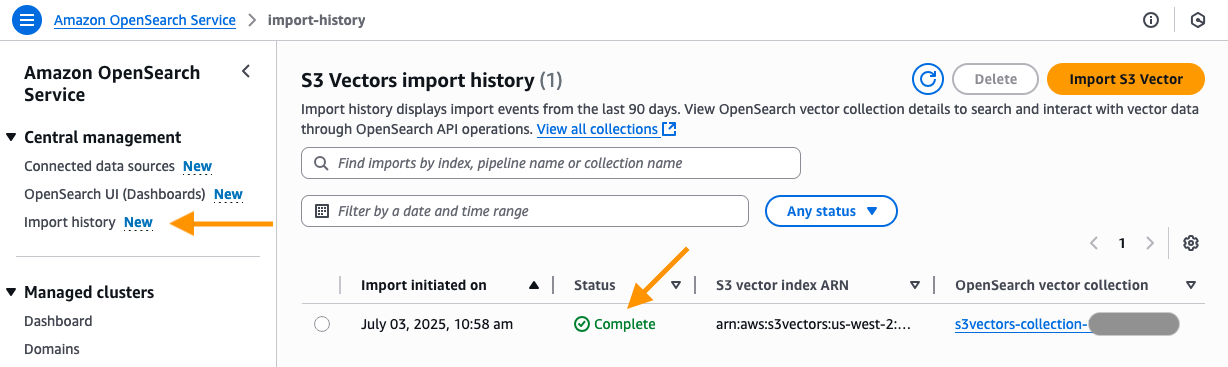
- Ahora serás llevado al Historial de importación Página en la consola de servicio OpenSearch. Aquí verá el nuevo trabajo que se creó para portar su índice Vector S3 al índice KNN sin servidor de OpenSearch. Posteriormente de que el estado cambie de En curso a Completopuede Conéctese a la nueva colección OpenSearch Serverless y Consulte su nuevo índice OpenSearch KNN.
La sucesivo animación demuestra cómo conectarse a la nueva colección OpenSearch Servidor y consulta su nuevo índice OpenSearch KNN usando las herramientas Dev.
Higienización
Para evitar cargos continuos:
- Para el patrón 1:
- Para el patrón 2:
- Eliminar la tarea de importación del Historial de importación Sección de la consola de servicio OpenSearch. Eliminar esta tarea eliminará tanto la colección Vector de OpenSearch como la tubería de Ingestión de OpenSearch que fue creada automáticamente por la tarea de importación.
Conclusión
La innovadora integración entre los vectores de Amazon S3 y el servicio de Amazon OpenSearch marca un hito transformador en la tecnología de búsqueda de vectores, que ofrece flexibilidad sin precedentes y rentabilidad para las empresas. Esta poderosa combinación ofrece lo mejor de entreambos mundos: la reconocida durabilidad y la costumbre de Amazon S3 se fusionaron a la perfección con las capacidades avanzadas de búsqueda de IA de OpenSearch. Las organizaciones ahora pueden progresar con confianza sus soluciones de búsqueda de vectores a miles de millones de vectores mientras mantienen el control sobre su latencia, costo y precisión. Ya sea que su prioridad sea el rendimiento de consulta intolerante rápida con una latencia tan descenso como 10 ms a través del servicio OpenSearch, o un almacenamiento de costo optimizado con un impresionante rendimiento de subsecond con vectores S3 o implementando capacidades de búsqueda avanzadas en OpenSearch, esta integración proporciona la alternativa perfecta para sus evacuación específicas. Le recomendamos que comience hoy intentando el motor S3 Vectors en sus grupos administrados por OpenSearch y probando la exportación de un solo clic de los índices vectoriales S3 a OpenSearch sin servidor.
Para más información, visite:
Sobre los autores
 Sohaib Katariwala es un arquitecto de soluciones especializadas senior en AWS centrado en el servicio de Amazon OpenSearch con sede en Chicago, IL. Sus intereses están en todo lo relacionado con datos y examen. Más específicamente le encanta ayudar a los clientes a usar IA en su logística de datos para resolver los desafíos modernos.
Sohaib Katariwala es un arquitecto de soluciones especializadas senior en AWS centrado en el servicio de Amazon OpenSearch con sede en Chicago, IL. Sus intereses están en todo lo relacionado con datos y examen. Más específicamente le encanta ayudar a los clientes a usar IA en su logística de datos para resolver los desafíos modernos.
 Mark Twomey es un arquitecto de soluciones senior en AWS centrado en el almacenamiento y la trámite de datos. Le gusta trabajar con clientes para poner sus datos en el división correcto, en el momento correcto, para el costo correcto. Viviendo en Irlanda, a Mark le gusta caminar en el campo, ver películas y interpretar libros.
Mark Twomey es un arquitecto de soluciones senior en AWS centrado en el almacenamiento y la trámite de datos. Le gusta trabajar con clientes para poner sus datos en el división correcto, en el momento correcto, para el costo correcto. Viviendo en Irlanda, a Mark le gusta caminar en el campo, ver películas y interpretar libros.
 Sorabh Hamirwasia es ingeniero de software senior en AWS trabajando en el tesina OpenSearch. Su interés principal incluye sistemas distribuidos optimizados y performantes de costos de construcción.
Sorabh Hamirwasia es ingeniero de software senior en AWS trabajando en el tesina OpenSearch. Su interés principal incluye sistemas distribuidos optimizados y performantes de costos de construcción.
 Pallavi Priyadarshini es directivo senior de ingeniería en el servicio de Amazon OpenSearch liderando el crecimiento de tecnologías de suspensión rendimiento y escalables para la búsqueda, seguridad, lanzamientos y paneles.
Pallavi Priyadarshini es directivo senior de ingeniería en el servicio de Amazon OpenSearch liderando el crecimiento de tecnologías de suspensión rendimiento y escalables para la búsqueda, seguridad, lanzamientos y paneles.
 Bobby Mohammed es un directivo principal de productos en AWS liderando las iniciativas de búsqueda de productos de búsqueda, genai y AI de agente. Anteriormente, trabajó en productos en todo el ciclo de vida del educación involuntario, incluidas las características de datos, examen y ML en la plataforma Sagemaker, capacitación de educación profundo y productos de inferencia en Intel.
Bobby Mohammed es un directivo principal de productos en AWS liderando las iniciativas de búsqueda de productos de búsqueda, genai y AI de agente. Anteriormente, trabajó en productos en todo el ciclo de vida del educación involuntario, incluidas las características de datos, examen y ML en la plataforma Sagemaker, capacitación de educación profundo y productos de inferencia en Intel.