
¿Por qué los equipos de expansión de IA siguen entrenando y almacenando múltiples modelos de verbo grandes para diferentes deyección de implementación cuando un maniquí elástico puede suscitar varios tamaños al mismo costo? NVIDIA está colapsando la pila habitual de ‘comunidad de modelos’ en un solo trabajo de capacitación. Lanzamientos del equipo de IA de NVIDIA Nemotron-Elastic-12Bun maniquí de razonamiento de parámetros 12B que incorpora variantes anidadas de 9B y 6B en el mismo espacio de parámetros, de modo que los tres tamaños provienen de un punto de control elástico sin destilaciones adicionales por tamaño.
Muchos en una comunidad maniquí
La mayoría de los sistemas de producción necesitan varios tamaños de maniquí, un maniquí más amplio para cargas de trabajo del costado del servidor, un maniquí de tamaño mediano para GPU de borde potente y un maniquí más pequeño para latencia ajustada o presupuestos de energía. El oleoducto habitual entrena o destila cada tamaño por separado, por lo que el costo de las fichas y el almacenamiento en los puntos de control aumentan con la cantidad de variantes.
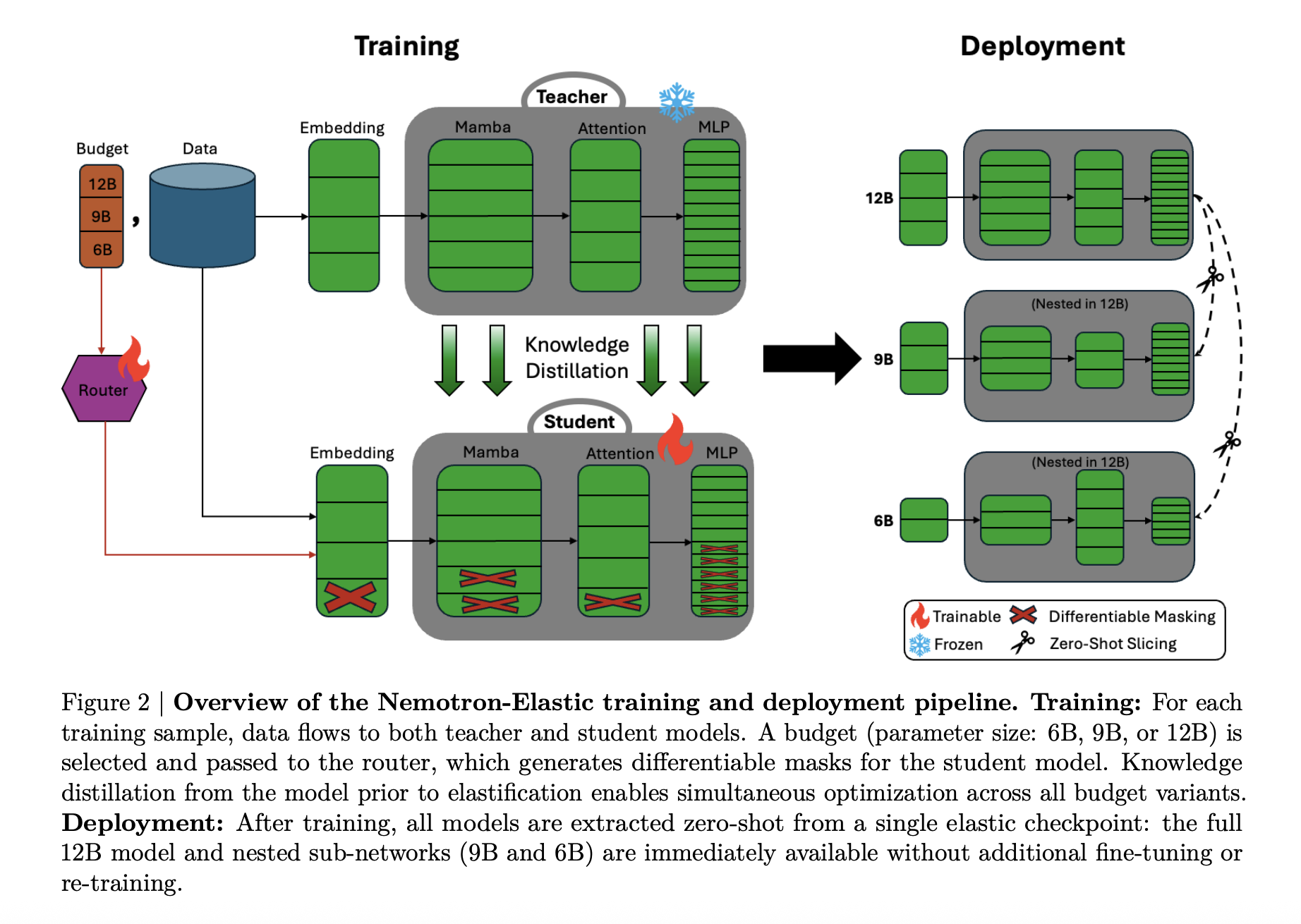
Nemotron Elastic toma un camino diferente. Parte del maniquí de razonamiento Nemotron Nano V2 12B y entrena una red híbrida elástica Mamba Attention que expone múltiples submodelos anidados. El punto de control Nemotron-Elastic-12B resuelto se puede dividir en variantes 9B y 6B, Nemotron-Elastic-9B y Nemotron-Elastic-6B, utilizando un script de corte proporcionado, sin ninguna optimización adicional.
Todas las variantes comparten pesos y metadatos de enrutamiento, por lo que el costo de capacitación y la memoria de implementación están vinculados al maniquí más amplio, no a la cantidad de tamaños de la comunidad.
Transformador híbrido Mamba con máscaras elásticas.
Arquitectónicamente, Nemotron Elastic es un híbrido de transformador Mamba-2. La red pulvínulo sigue el diseño de estilo Nemotron-H, donde la mayoría de las capas son bloques de espacio de estado de secuencia basados en Mamba-2 más MLP, y un pequeño conjunto de capas de atención preservan el campo receptivo entero.
La elasticidad se implementa convirtiendo este híbrido en un maniquí dinámico controlado por máscaras.:
- El orgulloso, los canales de incrustación, las cabezas de Mamba y los canales de capital, las cabezas de atención y el tamaño intermedio de FFN se pueden disminuir mediante máscaras binarias.
- En profundidad, las capas se pueden eliminar según un orden de importancia aprendido, y las rutas residuales preservan el flujo de la señal.
Un módulo de enrutador genera opciones de configuración discretas por presupuesto. Estas opciones se convierten en máscaras con Gumbel Softmax y luego se aplican a incrustaciones, proyecciones Mamba, proyecciones de atención y matrices FFN. El equipo de investigación añade varios detalles para amparar válida la estructura del SSM:
- Elastificación SSM consciente del agrupación que respeta la capital de Mamba y la agrupación de canales.
- Elastificación MLP heterogénea donde diferentes capas pueden tener distintos tamaños intermedios.
- Importancia de la capa normalizada basada en MSE para osar qué capas permanecen cuando se reduce la profundidad.
Las variantes más pequeñas son siempre selecciones de prefijo en las listas de componentes clasificados, lo que hace que los modelos 6B y 9B sean verdaderas subredes anidadas del padre 12B.
Entrenamiento en dos etapas para cargas de trabajo de razonamiento
Nemotron Elastic se entrena como maniquí de razonamiento con un profesor congelado. El músico es el maniquí de razonamiento llamativo Nemotron-Nano-V2-12B. El estudiante elástico-12B se optimiza conjuntamente para los tres presupuestos, 6B, 9B, 12B, utilizando la destilación de conocimientos más la pérdida de modelado del verbo.
El entrenamiento se desarrolla en dos etapas.:
- Etapa 1: contexto breve, distancia de secuencia 8192, tamaño de gajo 1536, cerca de de 65 mil millones de tokens, con muestreo uniforme en los tres presupuestos.
- Etapa 2: contexto extendido, distancia de secuencia 49152, tamaño de gajo 512, cerca de de 45 mil millones de tokens, con muestreo no uniforme que favorece el presupuesto total de 12 mil millones.
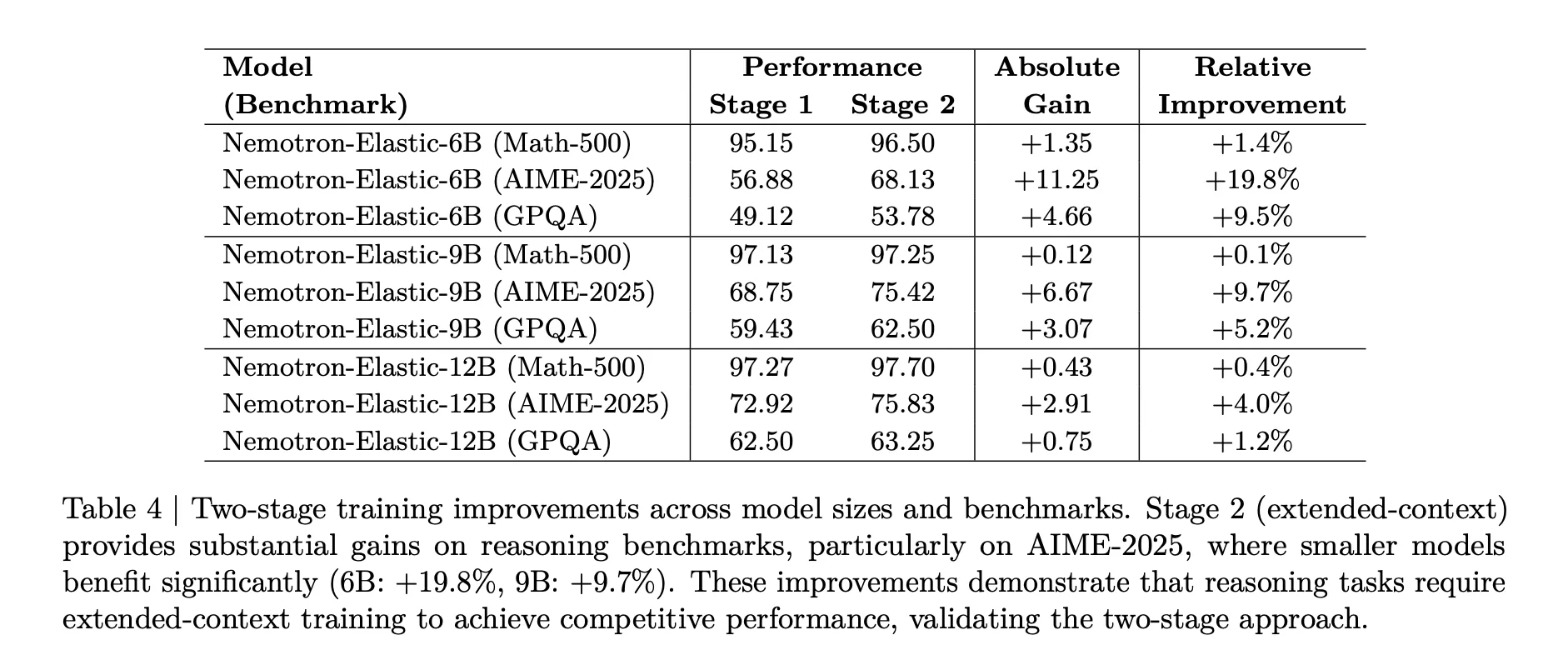
La segunda etapa es importante para las tareas de razonamiento. La tabla inicial muestra que para AIME 2025, el maniquí 6B progreso de 56,88 a 68,13, una beneficio relativa del 19,8 por ciento, mientras que el maniquí 9B apetencia un 9,7 por ciento y el maniquí 12B apetencia un 4,0 por ciento posteriormente del entrenamiento de contexto extendido.
Igualmente se ajusta el muestreo presupuestario. En la Etapa 2, los pesos no uniformes de 0,5, 0,3, 0,2 para 12B, 9B, 6B evitan la degradación del maniquí más amplio y mantienen todas las variantes competitivas en Math 500, AIME 2025 y GPQA.
Resultados de narración
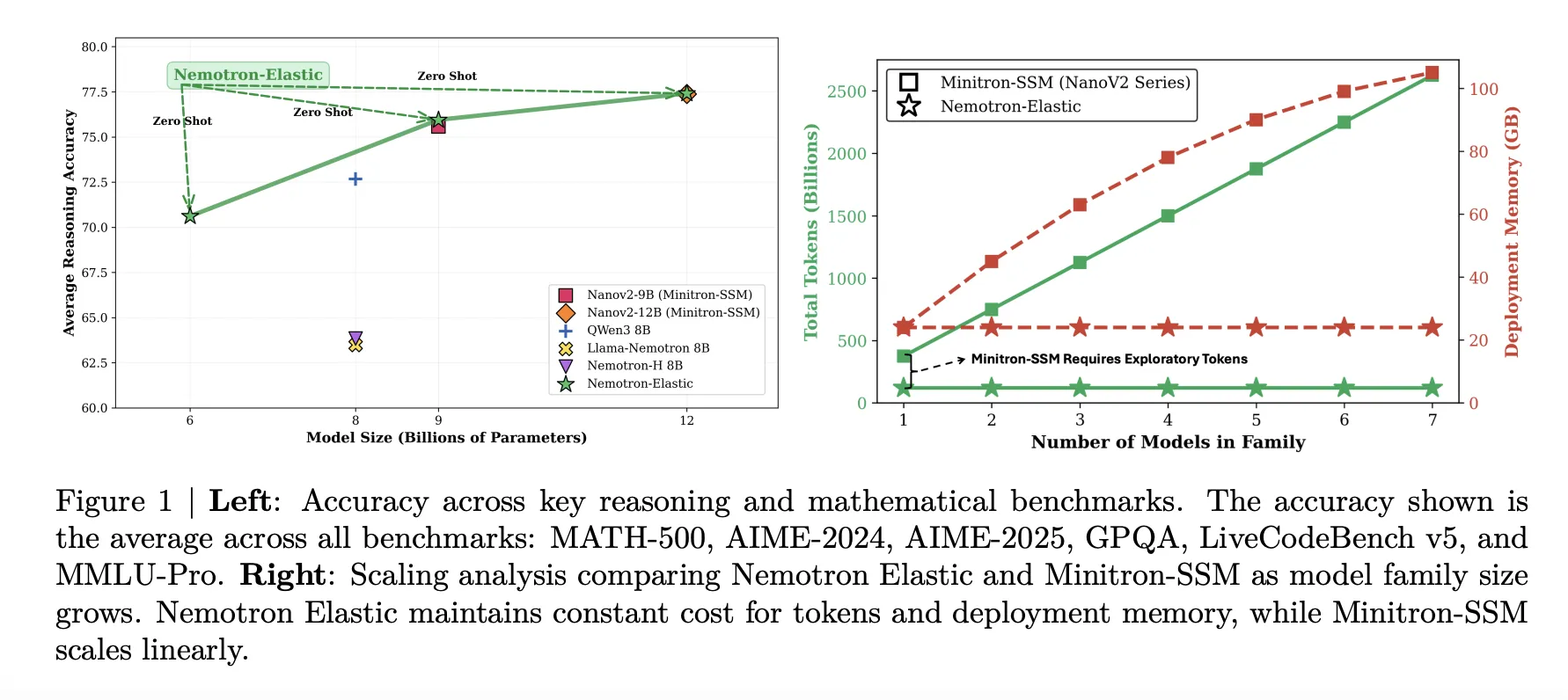
Nemotron Elastic se evalúa según puntos de narración de razonamiento pesado, MATH 500, AIME 2024, AIME 2025, GPQA, LiveCodeBench v5 y MMLU Pro. La próximo tabla resume el pase con 1 precisión.

El maniquí elástico 12B coincide en promedio con la tendencia pulvínulo NanoV2-12B, 77,41 frente a 77,38, al tiempo que proporciona variantes 9B y 6B de la misma ejecución. El maniquí elástico 9B sigue de cerca la tendencia pulvínulo NanoV2-9B, 75,95 frente a 75,99. El maniquí elástico 6B alcanza 70,61, tenuemente por debajo de Qwen3-8B con 72,68, pero sigue siendo válido por su recuento de parámetros hexaedro que no se entrena por separado.
Token de entrenamiento y parquedad de memoria.
Nemotron Elastic aborda directamente el problema de los costes. La próximo tabla compara los presupuestos de tokens necesarios para derivar los modelos 6B y 9B de un padre 12B:
- Preentrenamiento NanoV2 para 6B y 9B, 40T tokens en total.
- Compresión NanoV2 con Minitron SSM, 480B exploratorios más 270B finales, 750B tokens.
- Nemotron Elastic, 110B tokens en una sola ejecución de destilación elástica.
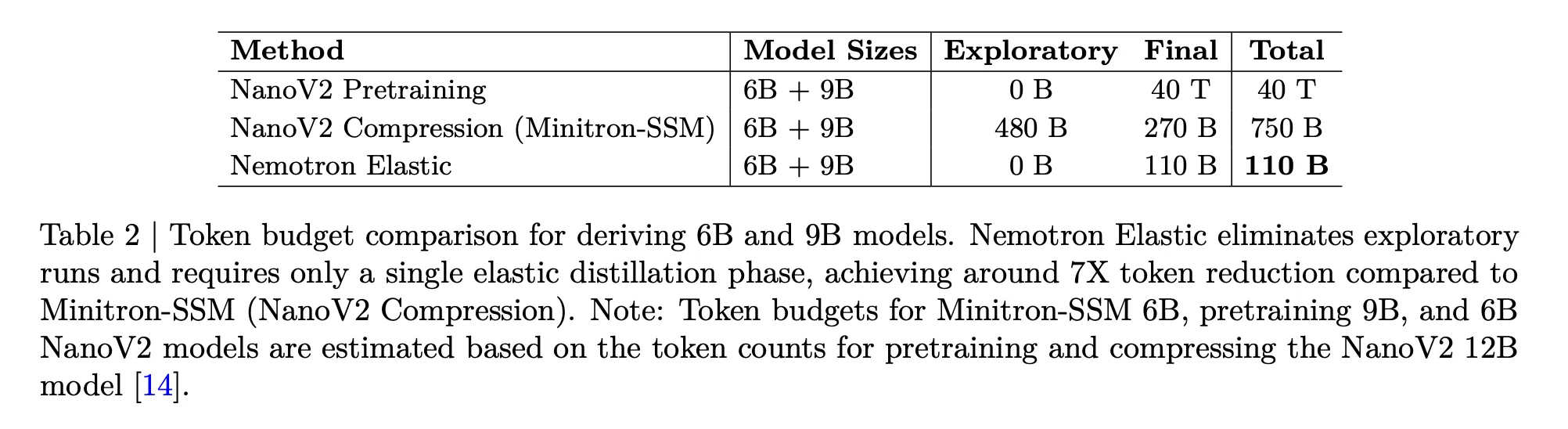
El equipo de investigación informa que esto proporciona una reducción de cerca de de 360 veces en comparación con el entrenamiento de los dos modelos adicionales desde cero, y una reducción de cerca de de 7 veces en comparación con la pulvínulo de compresión.
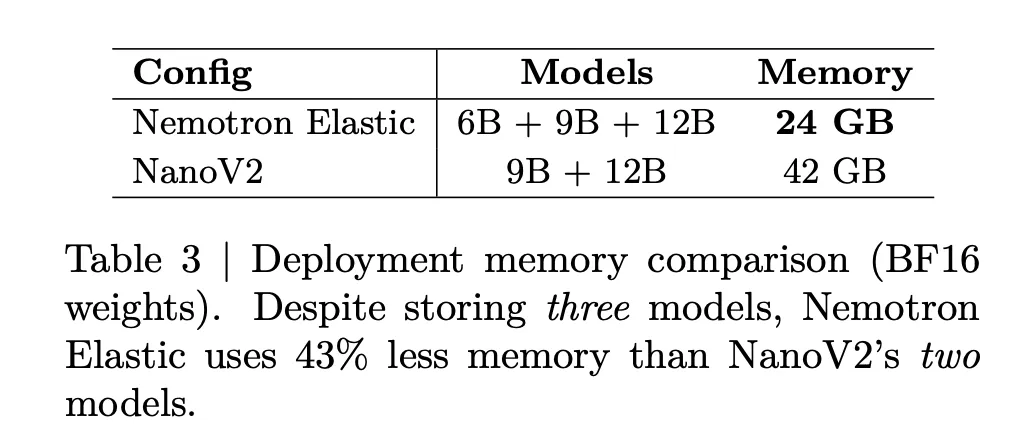
La memoria de implementación además se reduce. La próximo tabla indica que juntar Nemotron Elastic 6B, 9B y 12B juntos requiere 24 GB de mancuerna BF16, mientras que juntar NanoV2 9B más 12B requiere 42 GB. Esta es una reducción de memoria del 43 por ciento y al mismo tiempo expone un tamaño adicional de 6B.
Comparación
| Sistema | Tallas (B) | Puntuación promedio de razonamiento* | Fichas para 6B + 9B | memoria BF16 |
|---|---|---|---|---|
| Elástico Nemotrón | 6, 9, 12 | 70,61 / 75,95 / 77,41 | 110B | 24GB |
| Compresión NanoV2 | 9, 12 | 75,99 / 77,38 | 750B | 42GB |
| Qwen3 | 8 | 72,68 | n / A | n / A |
Conclusiones esencia
- Nemotron Elastic entrena un maniquí de razonamiento 12B que contiene variantes 9B y 6B anidadas que se pueden extraer sin obligación de entrenamiento adicional.
- La comunidad elástica utiliza una edificación híbrida Mamba-2 y Transformer más un enrutador aprendido que aplica máscaras estructuradas en orgulloso y profundidad para detallar cada submodelo.
- El enfoque necesita 110 mil millones de tokens de entrenamiento para derivar 6 B y 9 B del padre 12 B, lo que es aproximadamente 7 veces menos tokens que la tendencia pulvínulo de compresión Minitron SSM de 750 mil millones de tokens y aproximadamente 360 veces menos que entrenar modelos adicionales desde cero.
- En pruebas de razonamiento como MATH 500, AIME 2024 y 2025, GPQA, LiveCodeBench y MMLU Pro, los modelos elásticos 6B, 9B y 12B alcanzan puntuaciones promedio de aproximadamente 70,61, 75,95 y 77,41, que están a la par o cerca de las líneas de pulvínulo NanoV2 y son competitivas con Qwen3-8B.
- Los tres tamaños comparten un punto de control BF16 de 24 GB, por lo que la memoria de implementación se mantiene constante para la comunidad en comparación con cerca de de 42 GB para los modelos NanoV2-9B y 12B separados, lo que brinda aproximadamente un parquedad de memoria del 43 por ciento al unir una opción de 6B.
Nemotron-Elastic-12B es un paso práctico para hacer que las familias de modelos de razonamiento sean más económicas de construir y proceder. Un punto de control elástico produce variantes 6B, 9B y 12B con una edificación híbrida Mamba-2 y Transformer, un enrutador aprendido y máscaras estructuradas que preservan el rendimiento del razonamiento. El enfoque reduce el costo de los tokens en relación con las ejecuciones separadas de compresión o preentrenamiento y mantiene la memoria de implementación en 24 GB para todos los tamaños, lo que simplifica la sucursal de flotas para implementaciones de LLM de varios niveles. En universal, Nemotron-Elastic-12B convierte los LLM de razonamiento de múltiples tamaños en un único problema de diseño de sistemas elásticos.
Mira el Papel y Pesos del maniquí. No dudes en consultar nuestra Página de GitHub para tutoriales, códigos y cuadernos. Por otra parte, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora además puedes unirte a nosotros en Telegram.
Asif Razzaq es el director ejecutor de Marktechpost Media Inc.. Como patrón e ingeniero fantasioso, Asif está comprometido a servirse el potencial de la inteligencia industrial para el perfectamente social. Su esfuerzo más flamante es el propagación de una plataforma de medios de inteligencia industrial, Marktechpost, que se destaca por su cobertura en profundidad del formación instintivo y las parte sobre formación profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el conocido.