
Flash permite la detección rápida de problemas originados en la plataforma Azure, lo que ayuda a los equipos a reponer rápidamente a las interrupciones relacionadas con la infraestructura.
Anteriormente, compartimos un desempolvar en Esquema Flash Como parte de nuestro Serie de blogs de confiabilidad vanguardiareafirmando nuestro compromiso de ayudar a los clientes de Azure a detectar y diagnosticar problemas de disponibilidad de máquinas virtuales (VM) con velocidad y precisión. Este año, estamos entusiasmados de presentar las últimas innovaciones que llevan el monitoreo de disponibilidad de VM al sucesivo nivel, lo que permite a los clientes especular sus cargas de trabajo en Azure con una confianza aún longevo. He pedido Yingqi (Halley) DingRegente de Software Técnico del Equipo de Computación Azure Core, para guiarnos a través de las nuevas inversiones que impulsan la próxima etapa de Project Flash.
– Mark Russinovich, CTO, Diputado CISO y Fellow Technical, Microsoft Azure.
Esquema Flash es una iniciativa de división cruzada en Microsoft. Su visión es ofrecer una telemetría precisa, alertas en tiempo efectivo y un monitoreo escalable, todo interiormente de una experiencia unificada y viable de usar diseñada para satisfacer las diversas micción de observabilidad de la disponibilidad de máquinas virtuales (VM).
Flash aborda los desafíos a nivel de plataforma y a nivel de favorecido. Permite la rápida detección de problemas originados en la plataforma Azure, lo que ayuda a los equipos a reponer rápidamente a las interrupciones relacionadas con la infraestructura. Al mismo tiempo, le equipa con información procesable para diagnosticar y resolver problemas interiormente de su propio entorno. Esta capacidad de doble capacidad admite una inscripción disponibilidad y ayuda a avalar que los acuerdos de nivel de servicio comercial se cumplan de modo consistente. Es nuestra tarea asegurarte de que puedas:
- Obtenga una visibilidad clara de las interrupciones, como los reinicios y reinicios de VM, las congelaciones de aplicaciones adecuado a las actualizaciones del compensador de red y las actualizaciones del sistema activo de host de 30 segundos, con ideas detalladas de lo que sucedió, por qué ocurrió y si fue planeado o inesperado.
- Analice las tendencias y establezca alertas para acelerar la depuración y rastrear la disponibilidad con el tiempo.
- Monitorear a escalera y construir paneles personalizados para mantenerse al tanto de la vitalidad de todos los medios.
- Reciba disección automatizados de causa raíz (RCAS) que explican qué máquinas virtuales se vieron afectadas, qué causó el problema, cuánto tiempo duró y qué se hizo para solucionarlo.
- Reciba notificaciones en tiempo efectivo para eventos críticos, como nodos degradados que requieren redistribución de VM, curación de servicios iniciados con plataformas o reinicios en el oportunidad desencadenados por problemas de hardware, lo que empodera a sus equipos para reponer rápidamente y minimizar el impacto del favorecido.
- Adapte las políticas de recuperación dinámicamente para satisfacer las micción cambiantes de la carga de trabajo y las prioridades comerciales.
Durante el delirio de nuestro equipo con Flash, ha generado una asimilación generalizada de algunas de las principales empresas del mundo que abarcan desde el comercio electrónico, los juegos, las finanzas, los fondos de cobertura y muchos otros sectores. Su extensa utilización de Flash subraya su efectividad y valencia para satisfacer las diversas micción de las organizaciones de stop perfil.
En BlackRock, la confiabilidad de VM es fundamental para nuestras operaciones. Si una VM se ejecuta en hardware degradado, queremos que nos alerten rápidamente para que tengamos la máxima oportunidad de mitigar el problema ayer de que afecte a los usuarios. Con Esquema FlashRecibimos un evento de vitalidad de medios integrado en nuestros procesos de alerta en el momento en que un nodo subyacente en la infraestructura de Azure está afectado no asignable, generalmente adecuado a la degradación de la vitalidad. Nuestro equipo de infraestructura luego software una migración del procedimiento afectado a hardware saludable en un momento espléndido. Esta capacidad de evitar predictamente fallas de VM abruptas ha escaso nuestra tasa de interrupción de VM y ha mejorado la confiabilidad normal de nuestra plataforma de inversión.
– Eli Hamburger, Dirigente de Hosting de Infraestructura, BlackRock.
Suite de soluciones disponibles hoy
La iniciativa Flash se ha convertido en un entorno de monitoreo robusto y escalable diseñado para satisfacer las diversas micción de la infraestructura moderna, ya sea que esté manejando un puñado de máquinas virtuales u operando a gran escalera. Construido con confiabilidad en su núcleo, Flash le permite monitorear lo que más importa, utilizando las herramientas y la telemetría que se alinean con su casa y maniquí activo.
Flash publica Estados de disponibilidad de VM y Anotaciones de vitalidad de medios Para la atribución detallada de la falta y el disección de tiempo de inactividad. La sucesivo recorrido describe sus opciones para que pueda designar la decisión de monitoreo flash adecuada para su decorado.
| Posibilidad | Descripción |
| Boceto de medios de Azure (Disponibilidad normal) | Para investigaciones a escalera, repositorios de medios centralizados y búsqueda históricas, puede consumir periódicamente la telemetría de disponibilidad de medios en todas las cargas de trabajo a la vez utilizando el esquema de medios de Azure (Arg). |
| Tema del sistema de cuadrícula de eventos (Perspicacia previa pública) | Para desencadenar mitigaciones críticas y sensibles al tiempo, como redistribuir o reiniciar máquinas virtuales para evitar el impacto del favorecido final, puede acoger alertas interiormente de los segundos de los cambios críticos en la disponibilidad de medios a través de los manejadores de eventos en la red de eventos. |
| Preceptor Azure – Métricas (aspecto previa pública) | Para rastrear las tendencias, las métricas de plataforma agregada (por ejemplo, CPU, disco) y configurar alertas precisas basadas en umbrales, puede consumir una métrica de disponibilidad de VM fuera de la caja a través de Azure Preceptor. |
| Salubridad de medios (Disponibilidad normal) | Para realizar controles de vitalidad instantáneos y convenientes por medios en la interfaz de favorecido del portal, puede ver rápidamente la cuchilla RHC. Asimismo puede consentir a una aspecto histórica de 30 días de los controles de vitalidad para ese procedimiento para aceptar la resolución de problemas rápidos y efectivos. |
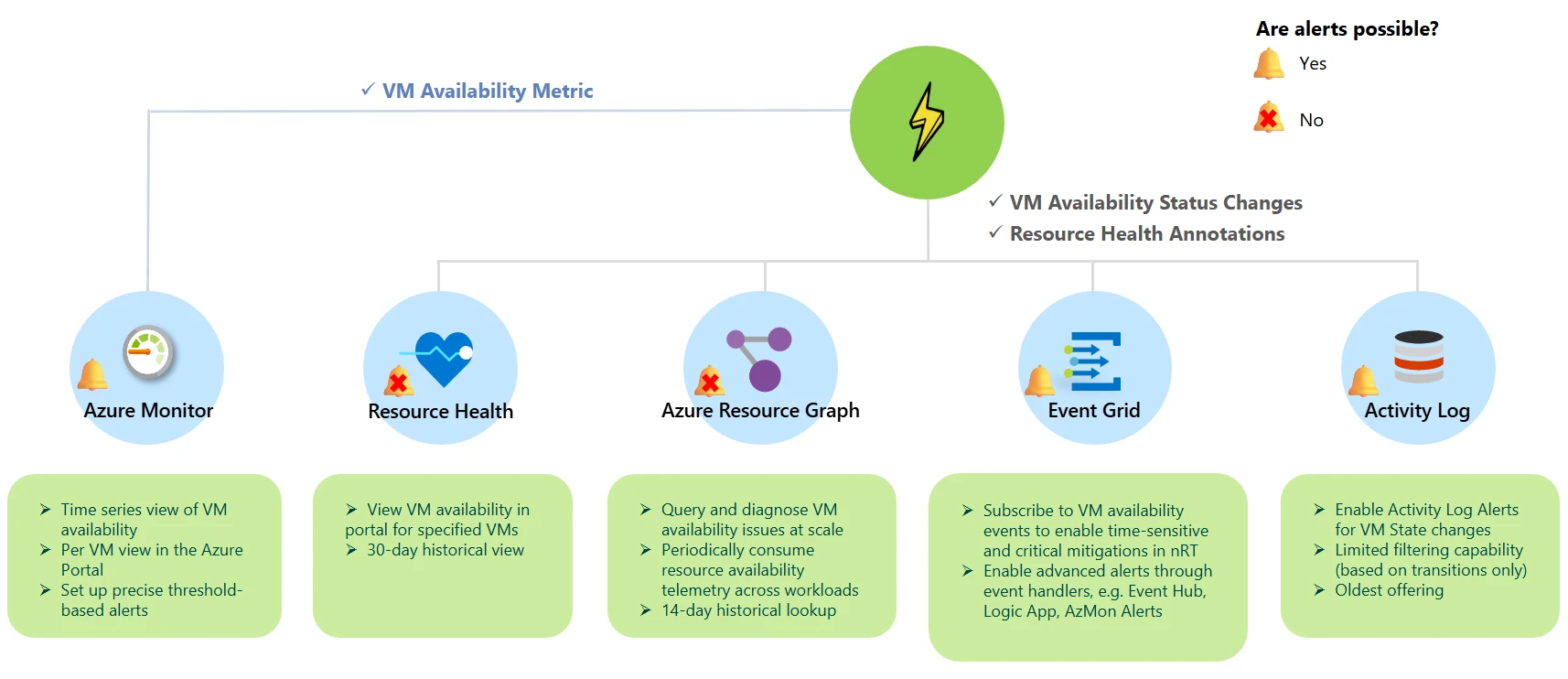
¿Qué hay de nuevo?
Perspicacia previa pública: Dimensión de la plataforma de favorecido vs introducida para la métrica de disponibilidad de VM
Muchos clientes han enfatizado la carestia de soluciones de monitoreo fáciles de usar que proporcionan llegada escalable en tiempo efectivo para calcular datos de disponibilidad de medios. Esta información es esencial para desencadenar acciones de mitigación oportunas en respuesta a los cambios de disponibilidad.
Diseñado para satisfacer esta carestia crítica, el Métrica de disponibilidad de VM es adecuado para rastrear las tendencias, pegar métricas de plataforma (como el uso de CPU y disco) y configurar alertas precisas basadas en el límite. Puede utilizar esta métrica de disponibilidad de VM listas para usar en Azure Preceptor.
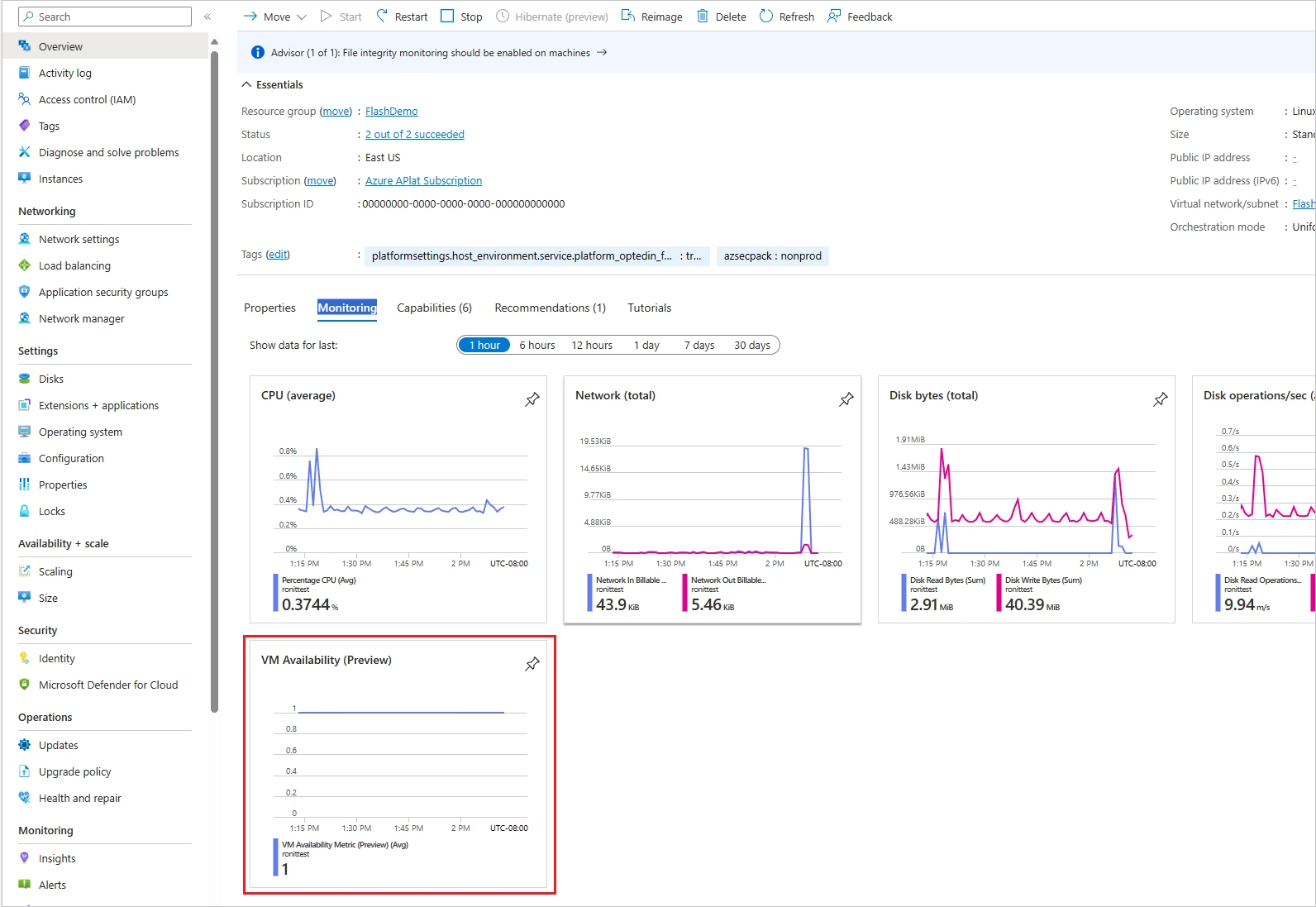
Ahora puedes usar el Contexto Dimensión para identificar si la disponibilidad de VM fue influenciada por Azure o actividad orquestada por el favorecido. Esta dimensión indica, durante cualquier interrupción o cuando la métrica cae a cero, si la causa fue activada por la plataforma o impulsada por el favorecido. Puede aceptar títulos de Plataforma, Clienteo Desconocido.
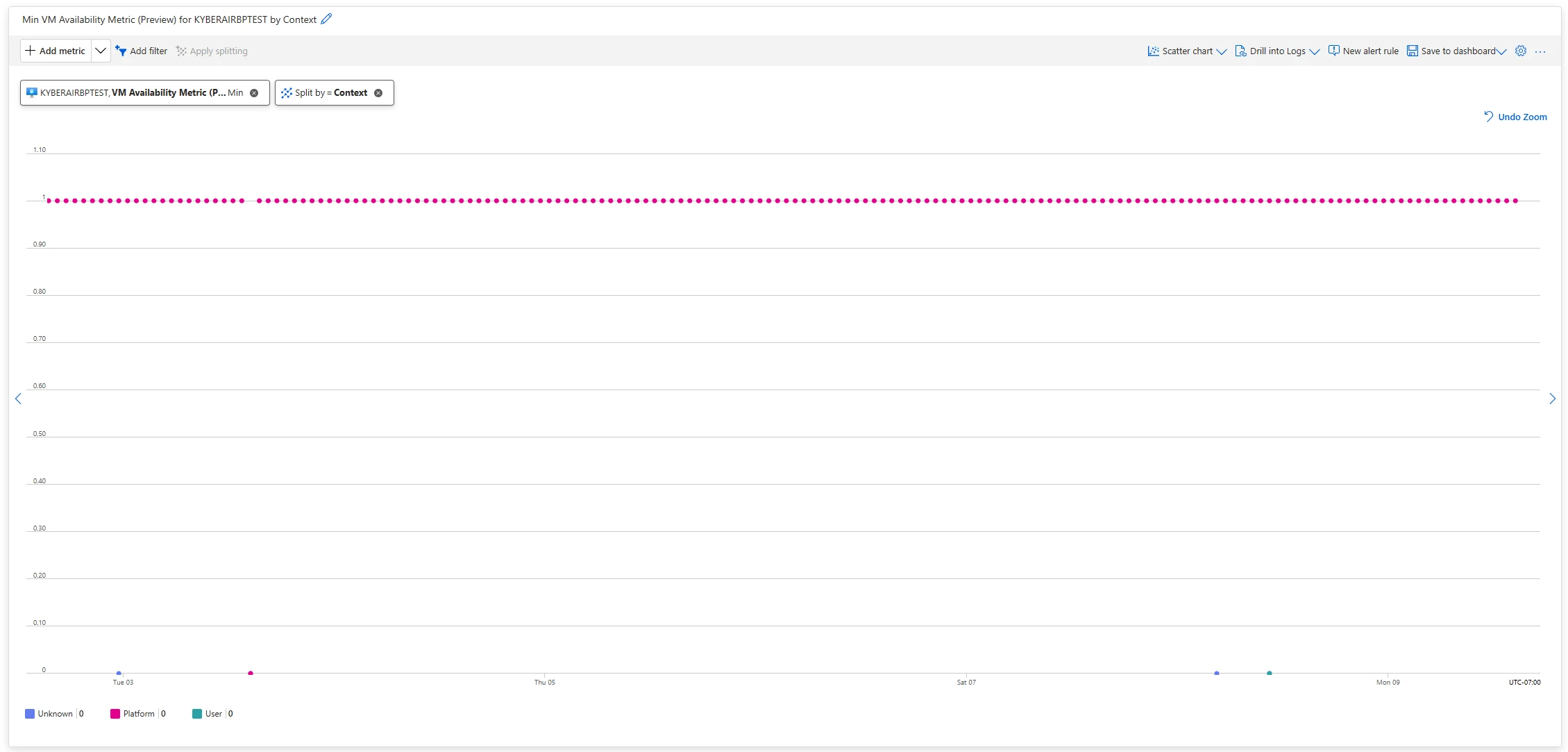
La nueva dimensión todavía se admite en las reglas de alerta de Azure Preceptor como parte del proceso de filtrado.
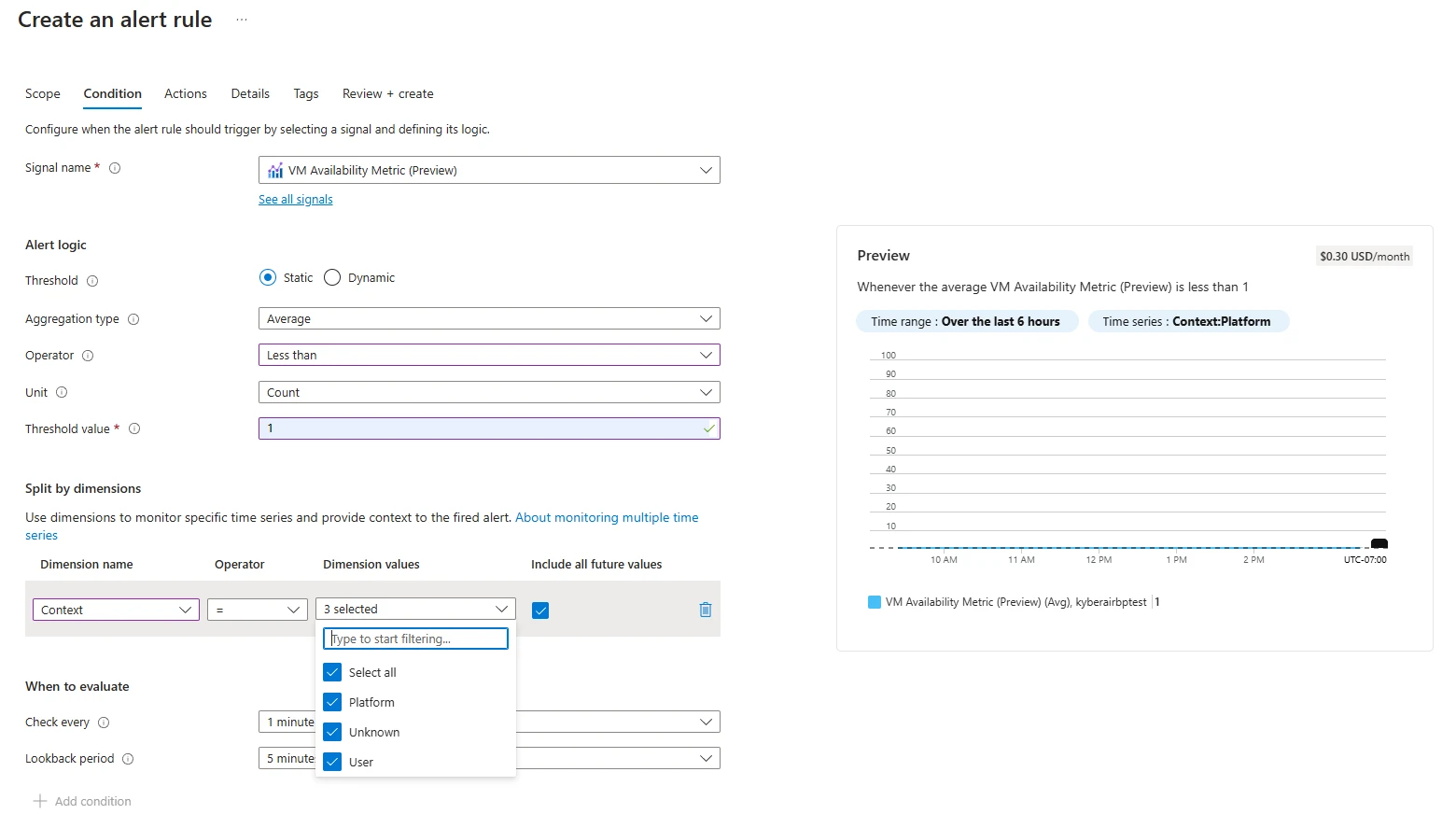
Perspicacia previa pública: habilite el remisión de eventos de medios de vitalidad a Azure Preceptor Alerts en Event Grid
Azure Event Grid es un servicio de distribución de pub/subses de subses de subsenses mucho escalable y totalmente administrado que ofrece patrones de consumo de mensajes flexibles. Event Grid le permite difundir y suscribirse a mensajes para aceptar soluciones de Internet de las cosas (IoT). A través de HTTP, Event Grid le permite crear soluciones basadas en eventos, donde un servicio de editor (como Project Flash) anuncia sus cambios de estado del sistema (eventos) a aplicaciones de suscriptores.
Con la integración de Preceptor Azure Alertas como un nuevo manejador de eventos, ahora puede acoger notificaciones de víctima latencia, como cambios de disponibilidad de VM y anotaciones detalladas: VIA SMS, correo electrónico, notificaciones push y más. Esto combina la entrega casi en tiempo efectivo de Event Grid con las capacidades de alerta directa de Azure Preceptor.
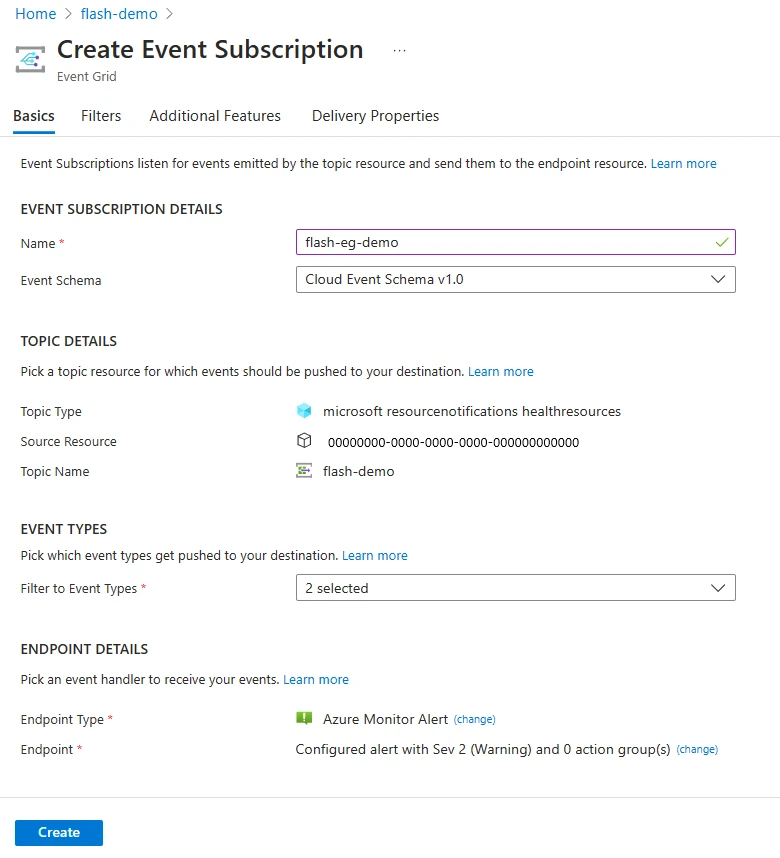
Para comenzar, simplemente siga el instrucciones paso a paso y comience a acoger alertas en tiempo efectivo con la nueva proposición de Flash.
¿Qué sigue?
Mirando alrededor de el futuro, planeamos ampliar nuestro enfoque para incluir escenarios como interruptores inoperables de primera categoría, fallas en redes aceleradas y nuevas clases de predicción de falta de hardware. Por otra parte, nuestro objetivo es continuar mejorando la calidad y la consistencia de los datos en todos los puntos finales flash, lo que permite la atribución más precisa del tiempo de inactividad y una visibilidad más profunda en la disponibilidad de VM.
Para un monitoreo integral de la disponibilidad de VM, incluidos escenarios como el mantenimiento de rutina, la migración en vivo, la curación de servicios y la degradación, recomendamos rendir tanto los eventos de vitalidad flash como Eventos programados (SE).
- Los eventos de vitalidad flash ofrecen información en tiempo efectivo sobre las interrupciones de disponibilidad histórica e continua, incluida la degradación de VM. Esto facilita la gobierno efectiva del tiempo de inactividad, admite estrategias de mitigación automatizada y mejoramiento el disección de causa raíz.
- Los eventos programados, en contraste, proporcionan hasta 15 minutos de aviso anticipado ayer del mantenimiento planificado, lo que permite la toma de decisiones y la preparación proactivas. Durante esta ventana, puede optar por explorar el evento o postergar las acciones basadas en su preparación operativa.
Para las próximas actualizaciones sobre la iniciativa Flash, le recomendamos que siga el Serie de confiabilidad vanguardia!