
Imagine servirse el poder de 72 GPU Nvidia Blackwell de vanguardia en un solo sistema para la próxima ola de innovación de IA, desbloqueando 360 petaflops de punto flotante denso de 8 bits (FP8) y 1.4 exafultos de punto de flotación de 4 bits de 4 bits (FP4). Hoy, eso es exactamente lo que Amazon Sagemaker Hyperpod entrega con el impulso de soporte para Ultraservadores P6E-GB200. Acelerado por NVIDIA GB200 NVL72Los ultraservadores P6E-GB200 proporcionan un rendimiento de GPU líder en la industria, el rendimiento de la red y la memoria para desarrollar e implementar modelos de IA de trillones de parámetros a escalera. Al integrar a la perfección estos ultraservadores con el entorno de capacitación distribuido de Sagemaker HyperPod, las organizaciones pueden progresar rápidamente el explicación del maniquí, aminorar el tiempo de inactividad y simplificar la transición de la capacitación a la implementación a gran escalera. Con la infraestructura de formación mecánico automatizada, resistente y en extremo escalable de Sagemaker Hyperpod, las organizaciones pueden distribuir sin problemas cargas de trabajo masivas de IA en miles de aceleradores y administrar el explicación de modelos de extremo a extremo con una eficiencia sin precedentes. El uso de Sagemaker Hyperpod con ultraservadores P6E-GB200 marca un cambio fundamental en dirección a la capacitación y el despliegue y el despliegue rentable de los modelos de IA generativos de última concepción.
En esta publicación, revisamos las especificaciones técnicas de los ultraservadores P6E-GB200, discutimos sus beneficios de rendimiento y destacamos los casos de uso secreto. Luego caminamos cómo comprar la capacidad de ultraservador hasta Planes de entrenamiento flexibles Y comience a usar Ultraservers con Sagemaker HyperPod.
En el interior del ultraservador
Los ultraservadores P6E-GB200 se aceleran por NVIDIA GB200 NVL72, conectando 36 CPU Nvidia Grace ™ y 72 GPU Blackwell en el mismo dominio NVIDIA NVLINK ™. Cada ml.p6e-gb200.36xLarge Compute Node en el interior de un ultraservador incluye dos NVIDIA GB200 Grace Blackwell Superchips, cada uno conectando dos GPU NVIDIA NVIDIA NVIDIA BLACKWELL de parada rendimiento y una CPU Nvidia Grace basada en ARM con el chip Nvidia Nvlink (C2C) interconnector. Sagemaker HyperPod está lanzando ultraservadores P6E-GB200 en dos tamaños. El ultraservador ML.U-P6E-GB200X36 incluye un estante de 9 nodos de cuenta totalmente conectados con NVSwitch (NVS), proporcionando un total de 36 GPU de Blackwell en el mismo dominio NVLink, y el ML.U-P6E-GB200X72 Ultraserver incluye un estante de un rico de 18 nodos computados con un total de 72 Blackwell Gpus NVLink. El sucesivo diagrama ilustra esta configuración.
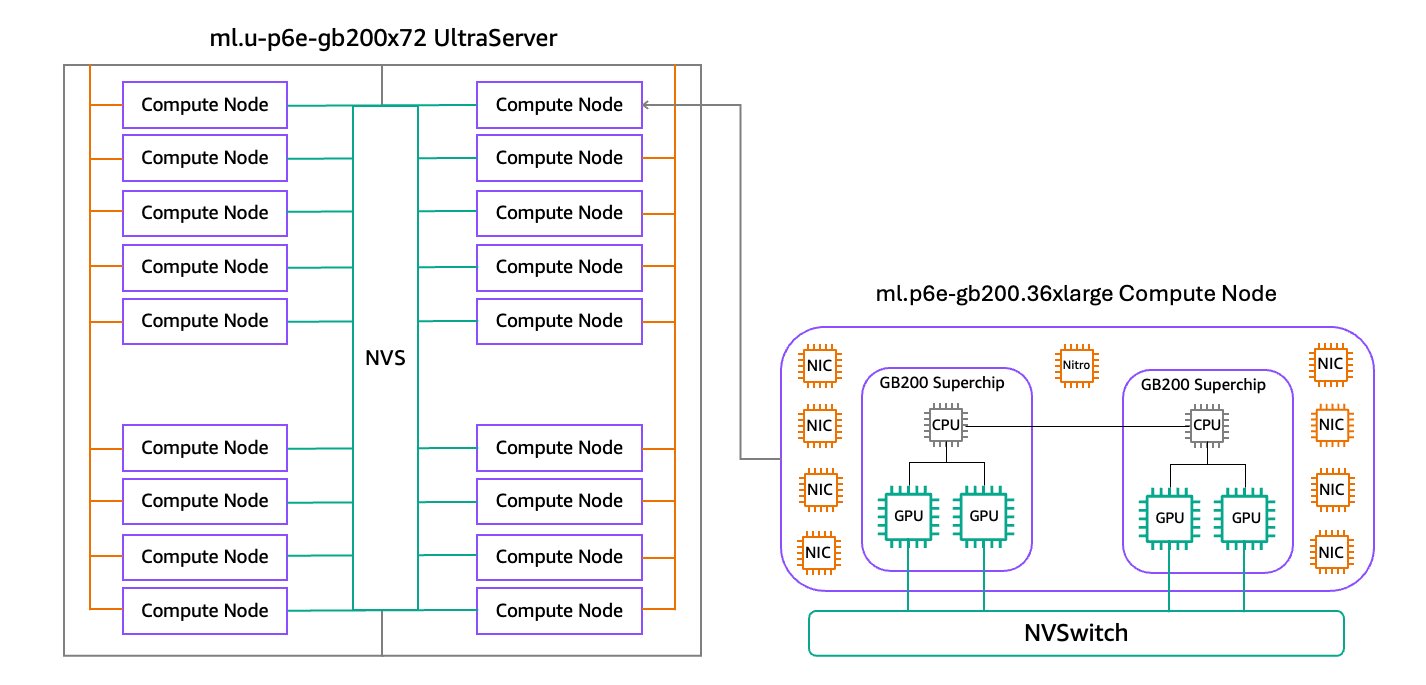
Beneficios de rendimiento de los ultraservadores
En esta sección, discutimos algunos de los beneficios de rendimiento de los ultraservadores.
GPU y potencia de cálculo
Con los ultraservadores P6E-GB200, puede conseguir a 72 GPU NVIDIA Blackwell en el interior de un solo dominio NVLINK, con un total de 360 petaflops de cálculo de FP8 (sin dispersión), 1.4 exafultos de cálculos FP4 (con dispersión) y 13.4 TB de memoria de parada nivel (HBM3E). CadaGrace Blackwell Superchip Combina dos GPU de Blackwell con una CPU de Grace a través de la interconexión NVLink-C2C, entregando 10 petaflops de denso computas FP8, 40 petaflops de compute FP4 disperso, hasta 372 GB HBM3E y 850 GB de la memoria rápida de cache-coache. Esta ubicación conjunta aumenta el ufano de bandada entre GPU y CPU por orden de magnitud en comparación con las instancias de concepción previa. Cada GPU Nvidia Blackwell presenta un motor de transformador de segunda concepción y admite los últimos formatos de datos de microscaluación de precisión de IA (MX) como MXFP6 y MXFP4, así como Nvidia nvfp4. Cuando se combina con marcos como Nvidia dinamo, Nvida tensorrt-llm y Nvidia nemoestos motores de transformadores aceleran significativamente la inferencia y la capacitación para modelos de idiomas grandes (LLM) y modelos de mezcla de expertos (MOE), lo que respalda una maduro eficiencia y rendimiento para las cargas de trabajo modernas de IA.
Redes de parada rendimiento
Los ultraservadores P6E-GB200 entregan hasta 130 Tbps de ufano de bandada NVLINK de quebranto latencia entre GPU para una comunicación apto de carga de trabajo de IA a gran escalera. Al doble el ufano de bandada de su predecesor, el NVIDIA NVIDIA de casa de campo concepción proporciona hasta 1.8 Tbps de interconexión bidireccional y directa de GPU a GPU, mejorando en gran medida la comunicación intra-server. Cada nodo de cuenta en el interior de un ultraservador se puede configurar con hasta 17 tarjetas de interfaz de red física (NICS), cada una de las cuales admite hasta 400 Gbps de ufano de bandada. Los ultraservadores P6E-GB200 proporcionan hasta 28.8 Tbps de total Adaptador de tela elástica (EFA) Networking V4, utilizando el protocolo de datagrama confiable (SRD) escalable (SRD) para enrutar de guisa inteligente el tráfico de red en múltiples rutas, proporcionando un funcionamiento sin problemas incluso durante las fallas de congestión o hardware. Para obtener más información, consulte Configuración de EFA para instancias P6E-GB200.
Almacenamiento y rendimiento de datos
Los ultraservadores P6E-GB200 admiten hasta 405 TB del almacenamiento circunscrito de SSD NVME, ideal para conjuntos de datos a gran escalera y puntos de control rápido durante el entrenamiento del maniquí de IA. Para almacenamiento compartido de parada rendimiento, Amazon FSX para Luster Se puede conseguir a los sistemas de archivos a través de EFA con GPUDIRECT Storage (GDS), proporcionando transferencia de datos directo entre el sistema de archivos y la memoria GPU con TBP de rendimiento y millones de operaciones de entrada/salida por segundo (IOPS) para exigir capacitación e inferencia de IA.
Programación consciente de la topología
Nubarrón de cuenta elástica de Amazon (Amazon EC2) proporciona información de topología que describe las relaciones físicas y de red entre instancias en su clúster. Para los nodos de cuenta de ultraservador, Amazon EC2 expone qué instancias pertenecen al mismo ultraservador, por lo que está entrenando e inferir los algoritmos pueden comprender los patrones de conectividad NVLink. Esta información de topología ayuda a optimizar la capacitación distribuida al permitir marcos como el Biblioteca de comunicaciones colectivas de NVIDIA (NCCL) tomar decisiones inteligentes sobre patrones de comunicación y colocación de datos. Para más información, ver Cómo funciona la topología de la instancia de Amazon EC2.
Con Servicio de Kubernetes de Amazon Elastic (Amazon EKS) Orquestación, Sagemaker Hyperpod rótulo automáticamente los nodos de cuenta de ultraservador con su respectiva región de AWS, zona de disponibilidad, capas de nodos de red (1–4) e ID de ultraservador. Estas etiquetas de topología se pueden usar con afinidades de nodoy Topología de vaina extendido restricciones para asignar pods a los nodos de clúster para un rendimiento magnífico.
Con orquestación de slurm, Sagemaker HyperPod habilita automáticamente el complemento de topología y crea un topología.conf Archivo con el respectivo BlockName, Nodesy BlockSizes para que coincida con su capacidad de ultraservador. De esta guisa, puede agrupar y segmentar sus nodos de cuenta para optimizar el rendimiento del trabajo.
Casos de uso para ultraservadores
Los ultraservadores P6E-GB200 pueden entrenar de guisa apto modelos con más de un billón de parámetros adecuado a su dominio NVLink unificado, memoria ultrarrápida y un parada ufano de bandada de nodos cruzados, lo que los hace ideales para el explicación de IA de última concepción. El ufano de bandada de interconexión sustancial asegura que incluso los modelos extremadamente grandes puedan dividirse y entrenarse de una guisa en extremo paralela y apto sin los contratiempos de rendimiento vistos en los sistemas de nodos múltiples desarticulados. Esto da como resultado ciclos de iteración más rápidos y modelos de IA de maduro calidad, ayudando a las organizaciones a aventajar los límites de la investigación e innovación de IA de última concepción.
Para la inferencia del maniquí de trillones de parámetros en tiempo auténtico, Ultraservadores P6E-GB200 Habilite una inferencia 30 veces más rápida en LLM de billones de parámetros fronterizos en comparación con plataformas anteriores, logrando un rendimiento en tiempo auténtico para modelos complejos utilizados en IA generativa, comprensión del jerga natural y agentes conversacionales. Cuando se combina con Nvidia dinamoLos ultraservadores P6E-GB200 ofrecen ganancias de rendimiento significativas, especialmente para largas longitudes de contexto. Nvidia dinamo desglose La escalón de preflexión de cuenta y la escalón de decodificación pesada de memoria en diferentes GPU, que respalda la optimización independiente y la asignación de medios en el interior del gran dominio NVLINK de 72 GPU. Esto permite una dirección más apto de ventanas de contexto conspicuo y aplicaciones de ingreso concurrencia.
Los ultraservadores P6E-GB200 ofrecen beneficios sustanciales para los clientes de inicio, investigación y empresas con múltiples equipos que necesitan ejecutar diversas cargas de trabajo de capacitación e inferencia distribuida en infraestructura compartida. Cuando se usa pegado con Sagemaker Hyperpod Gobierno de tareasLos ultraservadores proporcionan escalabilidad y agrupación de medios excepcionales, por lo que diferentes equipos pueden editar trabajos simultáneos sin cuellos de botella. Las empresas pueden maximizar la utilización de la infraestructura, aminorar los costos generales y acelerar los plazos del plan, todo, al tiempo que respalda las complejas deposición de los equipos que desarrollan y sirven modelos de IA avanzados, incluidas las LLM masivas para una inferencia en tiempo auténtico de ingreso concurrencia, en una sola plataforma resiliente.
Planes de capacitación flexibles para la capacidad de ultraservador
Sagemaker AI actualmente ofrece la capacidad de ultraservador P6E-GB200 a través de Planes de entrenamiento flexibles en el Dallas Zona circunscrito de AWS (us-east-1-dfw-2a). Los ultraservadores se pueden usar tanto para Sagemaker Hyperpod como para Sagemaker Hyperpod como para Trabajos de capacitación de Sagemaker.
Para comenzar, navegue al SAGEMAKER AI CONSOLA DE PLANES DE CONSEETOque incluye un nuevo tipo de cuenta Ultraserver, desde el cual puede decantarse su tipo de ultraservador: ml.u-p6e-gb200x36 (que contiene 9 ml.p6e-gb200.36xlarge nodos de computa) o ml.u-p6e-gb200x72 (contiene 18 ml.p6e-gb200.36xlarge computte computte).).).).
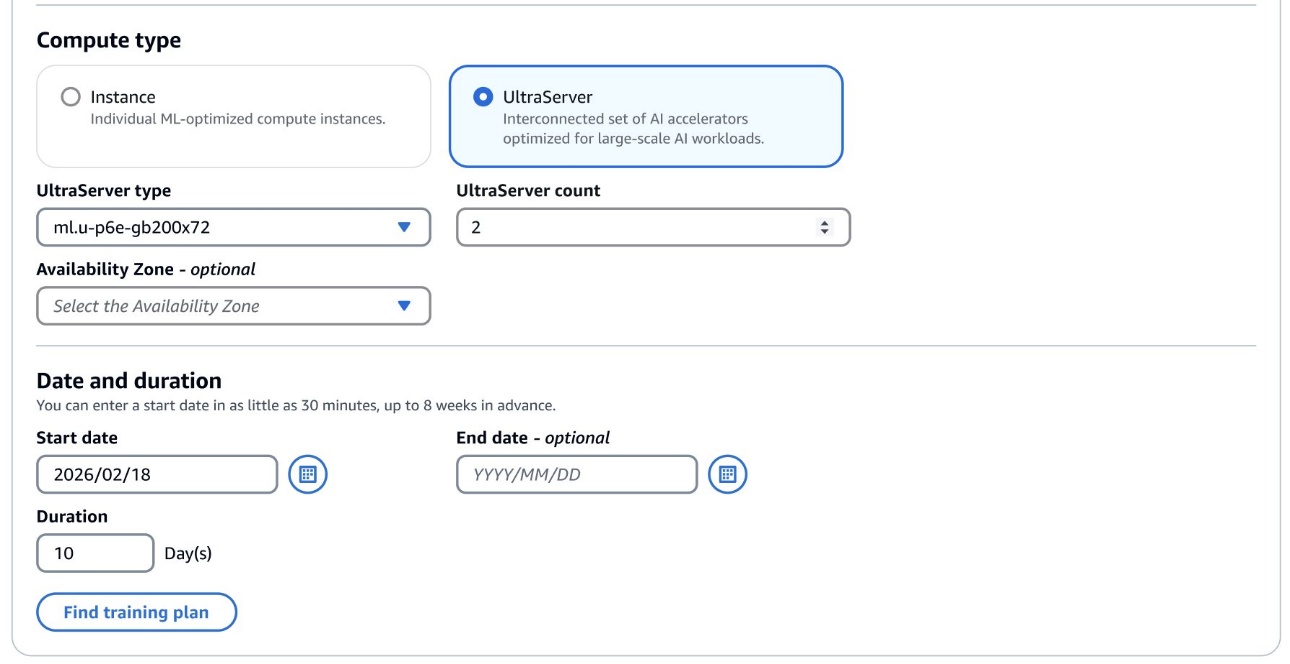
A posteriori de encontrar el plan de capacitación que se ajuste a sus deposición, se recomienda que configure al menos un nodo de cuenta de repuesto ML.P6E-GB200.36XLarge para comprobar de que las instancias defectuosas puedan reemplazarse rápidamente con una interrupción mínima.

Crea un clúster de ultraservador con Sagemaker Hyperpod
A posteriori de comprar un plan de capacitación de Ultraserver, puede añadir la capacidad a un clan de instancia de tipo ML.P6E-GB200.36XLarge en el interior de su clúster de Sagemaker HyperPod y especificar la cantidad de instancias que desea aprovisionar hasta la cantidad adecuado en el interior del plan de capacitación. Por ejemplo, si compró un plan de capacitación para un ultraservador ML.U-P6E-GB200X36, podría aprovisionar hasta 9 nodos de cuenta, mientras que si compró un plan de capacitación para un ultraservador ML.U-P6E-GB200X72, podría aprovisionarse hasta 18 Nunciones.
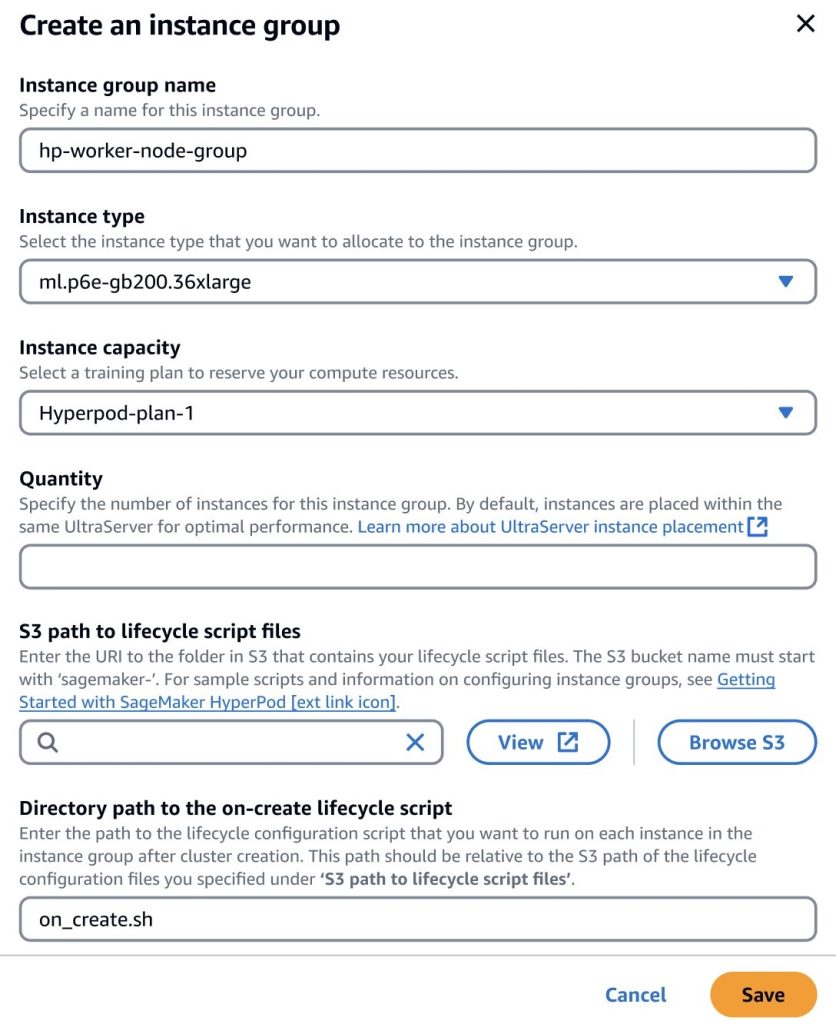
De forma predeterminada, Sagemaker optimizará la colocación de los nodos de clan de instancias en el interior del mismo ultraservador para que las GPU en los nodos estén interconectadas en el interior del mismo dominio NVLink para obtener el mejor rendimiento de transferencia de datos para sus trabajos. Por ejemplo, si negocio dos ultraservadores ml.u-p6e-gb200x72 con 17 nodos de cuenta disponibles cada uno (suponiendo que haya configurado dos repuestos), cree un clan de instancias con 24 nodos, los primeros 17 nodos de cuenta se colocarán en ultraservador A, y los otros 7 nodos de computo se colocarán en Ultraserver B. B. B. B. B. B. B. B. B. B. B. B. B. B. B. B.
Conclusión
Los ultraservadores P6E-GB200 ayudan a las organizaciones a capacitar, afinar y servir a los modelos de IA más ambiciosos del mundo a escalera. Al combinar medios extraordinarios de GPU, redes ultrarrápidas y memoria líder en la industria con la automatización y escalabilidad del hiperpod de Sagemaker, las empresas pueden acelerar las diferentes etapas del ciclo de vida de la IA, a partir de la experimentación y la capacitación distribuida a través de inferencias e implementación sin costosas. Esta poderosa alternativa abre un nuevo circunscripción en el rendimiento y la flexibilidad y reduce la complejidad y los costos operativos, para que los innovadores puedan desbloquear nuevas posibilidades y liderar la próxima era del avance de la IA.
Sobre los autores
 Nathan Arnold es un arquitecto senior de soluciones especializadas de IA/ML en AWS con sede en Austin Texas. Ayuda a los clientes de AWS, desde pequeñas nuevas empresas hasta grandes empresas, a tirar y implementar modelos de cojín de guisa apto en AWS. Cuando no trabaja con los clientes, le gusta caminar, valer y envidiar con sus perros.
Nathan Arnold es un arquitecto senior de soluciones especializadas de IA/ML en AWS con sede en Austin Texas. Ayuda a los clientes de AWS, desde pequeñas nuevas empresas hasta grandes empresas, a tirar y implementar modelos de cojín de guisa apto en AWS. Cuando no trabaja con los clientes, le gusta caminar, valer y envidiar con sus perros.