
Mistral AI ha decidido Mistral Pequeño 4un nuevo maniquí de la tribu Mistral Small diseñado para consolidar varias capacidades previamente separadas en un solo objetivo de despliegue. El equipo de Mistral describe el Small 4 como su primer maniquí que combina las funciones asociadas con Mistral Pequeño para seguir instrucciones, Extraordinario para razonar, Pixtral para la comprensión multimodal, y Devstral para codificación agente. El resultado es un maniquí único que puede funcionar como asistente militar, maniquí de razonamiento y sistema multimodal sin privación de cambiar de maniquí entre flujos de trabajo.
Edificación: 128 expertos, activación escasa
Arquitectónicamente, Mistral Small 4 es un Mezcla de expertos (MoE) maniquí con 128 expertos y 4 expertos activos por token. El maniquí tiene 119B parámetros totalescon 6 mil millones de parámetros activos por tokeno 8B incluyendo capas de incrustación y salida.
Contexto liberal y soporte multimodal
El maniquí soporta una Ventana de contexto de 256klo que supone un brinco significativo para casos prácticos de uso de ingeniería. La capacidad de contexto liberal importa menos como emblema de marketing y más como simplificador eficaz: reduce la privación de fragmentación agresiva, orquestación de recuperación y poda de contexto en tareas como examen de documentos extensos, exploración de bases de código, razonamiento de múltiples archivos y flujos de trabajo agentes. Mistral posiciona el maniquí para Chat militar, codificación, tareas de agencia y razonamiento engorroso.con entradas de texto e imagen y salida de texto. Eso coloca a Small 4 en la categoría cada vez más importante de modelos de propósito militar que se prórroga que manejen tareas empresariales con mucho jerigonza y visualmente basadas en una superficie API.
Razonamiento configurable en tiempo de inferencia
Una osadía de producto más importante que el recuento de parámetros brutos es la comienzo de esfuerzo de razonamiento configurable. Small 4 expone una solicitud por solicitud reasoning_effort parámetro que permite a los desarrolladores cambiar la latencia por un razonamiento más profundo en el momento de la prueba. En la documentación oficial, reasoning_effort="none" se describe como que produce respuestas rápidas con un estilo de chat equivalente a Mistral Pequeño 3.2mientras reasoning_effort="high" está destinado a un razonamiento más deliberado, paso a paso, con una verbosidad comparable a la susodicho. Extraordinario modelos. Esto cambia el patrón de implementación. En extensión de enrutar entre un maniquí rápido y un maniquí de razonamiento, los equipos de progreso pueden surtir un único maniquí en servicio y variar el comportamiento de inferencia en el momento de la solicitud. Esto es más íntegro desde una perspectiva de sistemas y más practicable de ordenar en productos donde solo un subconjunto de consultas positivamente necesita un razonamiento costoso.
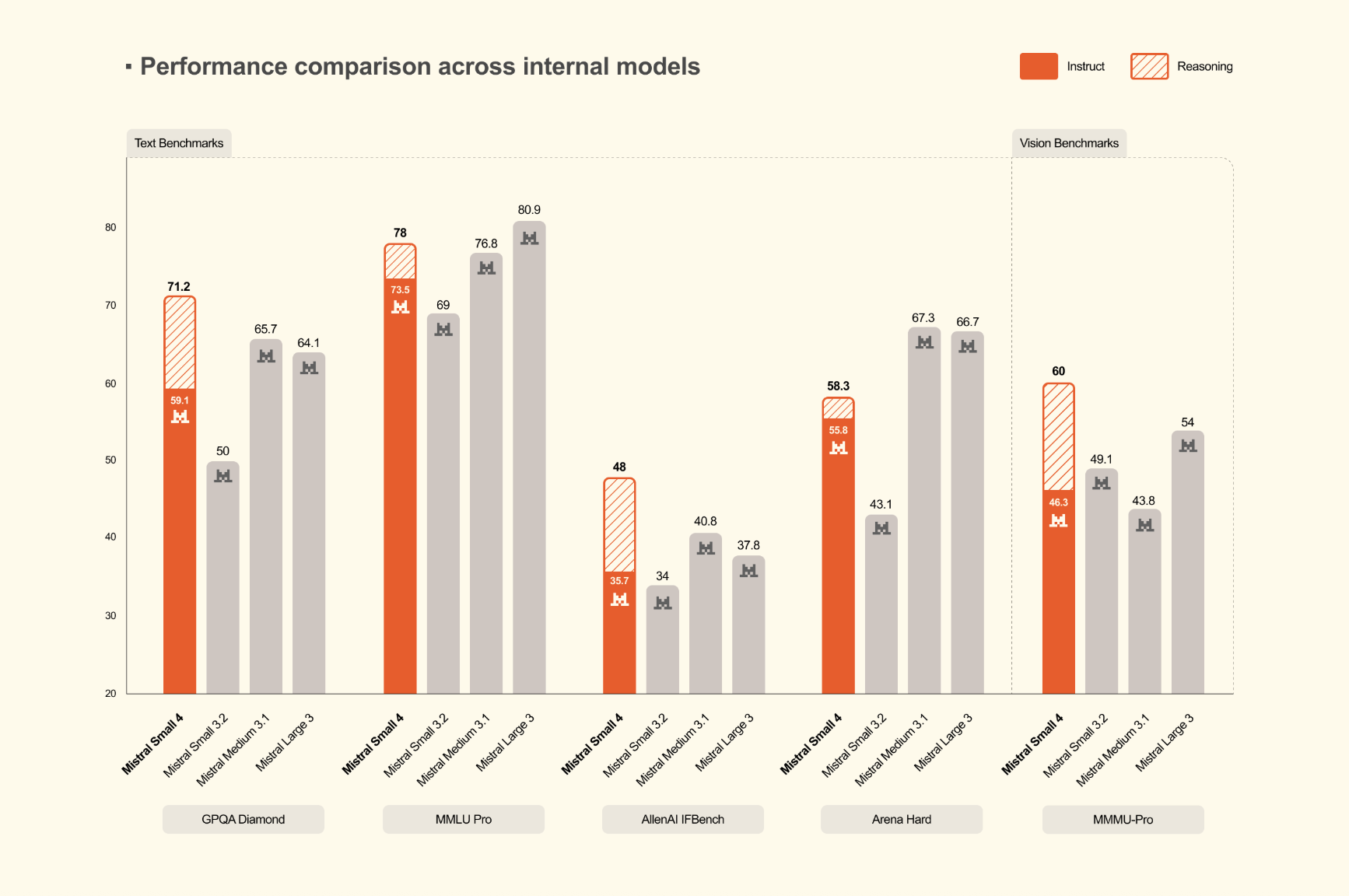
Declaraciones de rendimiento y posicionamiento del rendimiento
El equipo de Mistral todavía enfatiza la eficiencia de la inferencia. Small 4 ofrece un Reducción del 40% en el tiempo de finalización de un extremo a otro en una configuración de latencia optimizada y 3 veces más solicitudes por segundo en una configuración de rendimiento optimizado, los dos medidos contra Mistral Pequeño 3. Mistral no presenta Small 4 simplemente como un maniquí de razonamiento más amplio, sino como un sistema destinado a mejorar la peculio de implementación bajo cargas de servicio reales.
Resultados de remisión y eficiencia de producción
En cuanto a los puntos de remisión de razonamiento, el tiro de Mistral se centra tanto en la calidad como en la eficiencia de la producción. El equipo de investigación del Mistral informa que Mistral Small 4 con razonamiento iguala o excede GPT-OSS 120B al otro flanco de AA LCR, Porción de códigos en vivoy OBJETIVO 2025al tiempo que genera resultados más breves. En los números publicados por Mistral, Small 4 puntúa 0,72 en AA LCR con 1,6K caracteresmientras que los modelos Qwen requieren 5,8 000 a 6,1 000 caracteres para un rendimiento comparable. En Porción de códigos en vivoel equipo de Mistral afirma que Small 4 supera a GPT-OSS 120B mientras produce 20% menos de producción. Estos son resultados publicados por la empresa, pero destacan una métrica más ejercicio que la puntuación de remisión por sí sola: rendimiento por token generado. Para cargas de trabajo de producción, resultados más cortos pueden achicar directamente la latencia, el costo de inferencia y los gastos generales de examen posterior.
Detalles de implementación
Para el autohospedaje, Mistral brinda orientación sobre infraestructura específica. La empresa enumera un objetivo minúsculo de implementación de 4x NVIDIA HGX H100, 2x NVIDIA HGX H200o 1x NVIDIA DGX B200con configuraciones más grandes recomendadas para un mejor rendimiento. La maleable maniquí en HuggingFace enumera el soporte en todos vllm, fogata.cpp, SGLangy Transformadoresaunque algunos caminos están señalizados trabajo en progresoy vllm es la opción recomendada. El equipo de Mistral todavía proporciona una imagen de Docker personalizada y señala que las correcciones relacionadas con la llamamiento de herramientas y el examen del razonamiento aún se están actualizando. Este es un detalle útil para los equipos de ingeniería porque aclara que existe soporte, pero algunas piezas aún se están estabilizando en la pila de servicios de código destapado más amplia.
Conclusiones esencia
- Un maniquí unificado: Mistral Small 4 combina capacidades de instrucción, razonamiento, codificación multimodal y agente en un solo maniquí.
- Diseño escaso de MoE: se utiliza 128 expertos con 4 expertos activos por tokenapuntando a una mejor eficiencia que los modelos densos de tamaño total similar.
- Soporte de contexto liberal: El maniquí soporta una Ventana de contexto de 256k y acepta entradas de texto e imagen con salida de texto.
- El razonamiento es configurable: Los desarrolladores pueden ajustar
reasoning_efforten el momento de la inferencia en extensión de enrutar entre modelos rápidos y de razonamiento separados. - Enfoque de implementación abierta: Se publica bajo apache 2.0 y soportes que sirven a través de pilas como vllmcon múltiples variantes de puntos de control en Hugging Face.
Comprobar Polímero de maniquí en HF y Detalles técnicos. Por otra parte, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 120.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora todavía puedes unirte a nosotros en Telegram.