
El problema con «pensar más»
Los modelos de idiomas grandes han hecho avances impresionantes en el razonamiento matemático al extender sus procesos de sujeción de pensamiento (cot), esencialmente «pensando más tiempo» a través de pasos de razonamiento más detallados. Sin requisa, este enfoque tiene limitaciones fundamentales. Cuando los modelos encuentran errores sutiles en sus cadenas de razonamiento, a menudo agravan estos errores en extensión de detectarlos y corregirlos. La autorreflexión interna frecuentemente falta, especialmente cuando el enfoque de razonamiento original es fundamentalmente defectuoso.
El nuevo mensaje de investigación de Microsoft presenta RSTAR2-agent, que adopta un enfoque diferente: en extensión de solo pensar más, enseña a los modelos a pensar más inteligente mediante el uso activo de herramientas de codificación para efectuar, explorar y refinar su proceso de razonamiento.
El enfoque de agente
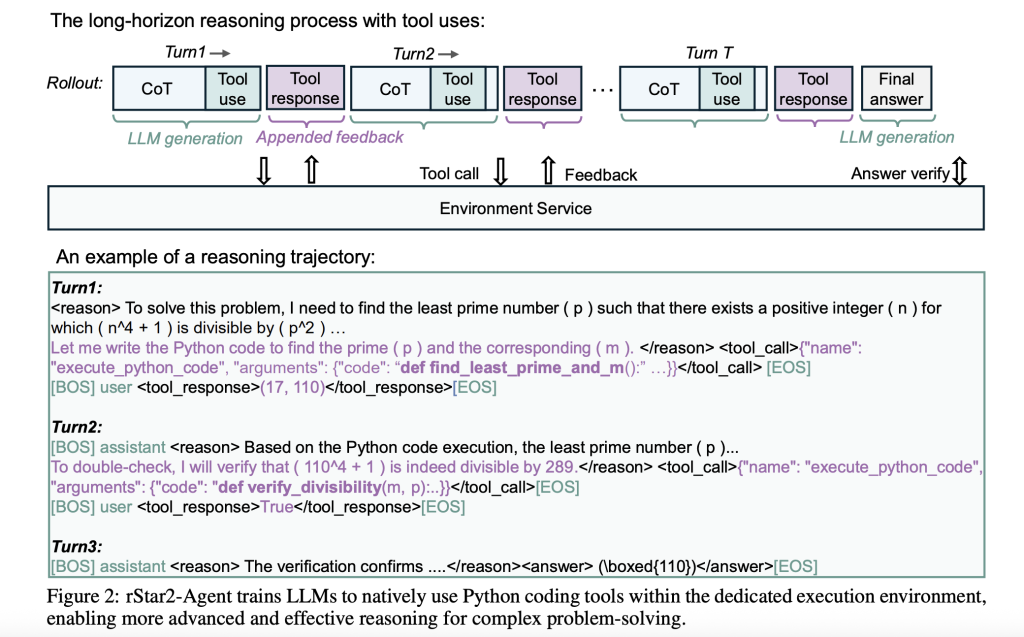
RSTAR2-AGENT representa un cambio con destino a el educación de refuerzo de agente, donde un maniquí de parámetros de 14b interactúa con un entorno de ejecución de Python a lo espléndido de su proceso de razonamiento. En extensión de abandonarse solamente en la advertencia interna, el maniquí puede escribir código, ejecutarlo, analizar los resultados y ajustar su enfoque en función de la feedback concreta.
Esto crea un proceso dinámico de resolución de problemas. Cuando el maniquí encuentra un problema matemático confuso, podría crear un razonamiento original, escribir el código de Python para probar hipótesis, analizar los resultados de la ejecución e iterar con destino a una alternativa. El enfoque refleja cómo funcionan a menudo los matemáticos humanos, utilizando herramientas computacionales para efectuar las intuiciones y explorar diferentes rutas de soluciones.
Desafíos y soluciones de infraestructura
Scaling Agentic RL presenta obstáculos técnicos significativos. Durante el entrenamiento, un solo parte puede crear decenas de miles de solicitudes de ejecución de código concurrentes, creando cuellos de botella que pueden detener la utilización de GPU. Los investigadores abordaron esto con dos innovaciones secreto de infraestructura.
Primero, crearon un servicio de ejecución de código distribuido capaz de manejar 45,000 llamadas de herramientas concurrentes con latencia sub-segundo. El sistema aísla la ejecución del código del principal proceso de capacitación mientras mantiene un parada rendimiento a través del compensación de carga cuidadoso entre los trabajadores de la CPU.
En segundo extensión, desarrollaron un planificador de despliegue dinámico que asigna el trabajo computacional basado en la disponibilidad de personalidad de GPU en tiempo positivo en extensión de la asignación estática. Esto evita el tiempo de inactividad de GPU causado por una distribución desigual de la carga de trabajo, un problema popular cuando algunos rastros de razonamiento requieren significativamente más cálculo que otros.
Estas mejoras de infraestructura permitieron que todo el proceso de capacitación se completara en solo una semana utilizando 64 GPU de AMD MI300X, lo que demuestra que las capacidades de razonamiento de nivel fronterizo no requieren bienes computacionales masivos cuando se orquestan eficientemente.
GRPO-ROC: aprendiendo de ejemplos de adhesión calidad
La innovación algorítmica central es la optimización de políticas relativas del reunión con el remuestreo en correcto (GRPO-ROC). El educación de refuerzo tradicional en este contexto enfrenta un problema de calidad: los modelos reciben recompensas positivas para las respuestas finales correctas incluso cuando su proceso de razonamiento incluye múltiples errores de código o uso ineficiente de herramientas.
GRPO-ROC aborda esto mediante la implementación de una organización de muestreo desproporcionado. Durante el entrenamiento, el operación:
- De exhibición despliegues iniciales para crear un reunión más ilustre de rastros de razonamiento
- Conserva la pluralidad En intentos fallidos de ayudar el educación de varios modos de error
- Filtra ejemplos positivos Para resaltar trazas con errores de útil mínimos y formateo más noble
Este enfoque garantiza que el maniquí aprenda del razonamiento exitoso de adhesión calidad y aún se expone a diversos patrones de falta. El resultado es un uso de herramientas más competente y trazas de razonamiento más cortas y más enfocadas.
Organización de entrenamiento: de simple a confuso
El proceso de capacitación se desarrolla en tres etapas cuidadosamente diseñadas, comenzando con el ajuste fino supervisado que no se concentra que se centra exclusivamente en la instrucción seguida y el formateo de la útil, evitando deliberadamente ejemplos de razonamiento complejos que podrían crear sesgos tempranos.
Etapa 1 restringe las respuestas a 8,000 tokens, lo que obliga al maniquí a desarrollar estrategias de razonamiento concisas. A pesar de esta límite, el rendimiento salta dramáticamente, desde cerca de Zero hasta más del 70% en puntos de remisión desafiantes.
Etapa 2 extiende el periferia de token a 12,000, lo que permite un razonamiento más confuso mientras mantiene las ganancias de eficiencia desde la primera etapa.
Etapa 3 Los cambios se centran en los problemas más difíciles al filtrar los que el maniquí ya ha dominado, asegurando el educación continuo de casos desafiantes.
Esta progresión de razonamiento conciso a extendido, combinado con la creciente dificultad del problema, maximiza la eficiencia del educación al tiempo que minimiza la sobrecarga computacional.
Resultados innovadores
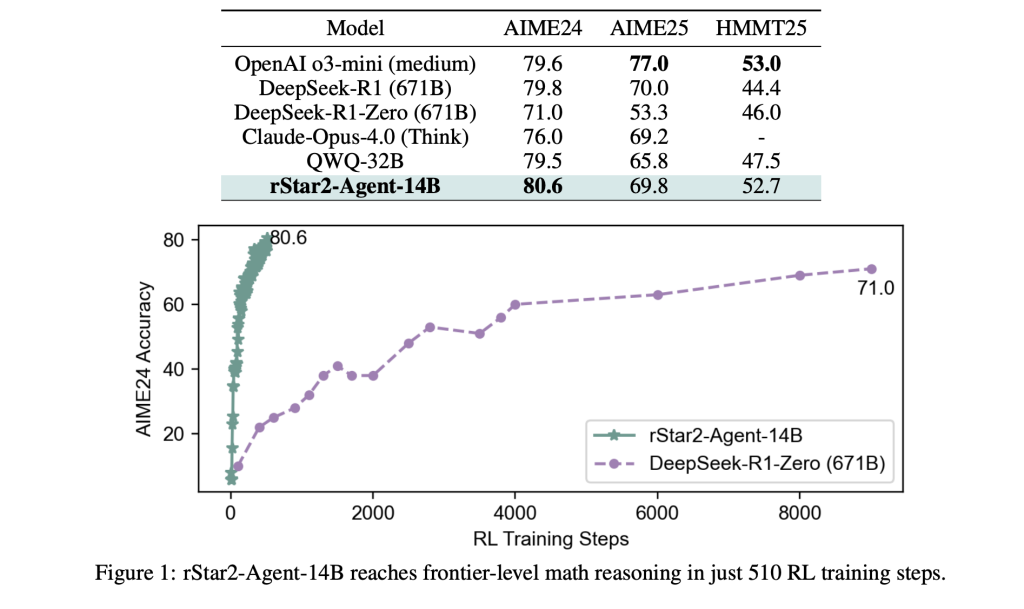
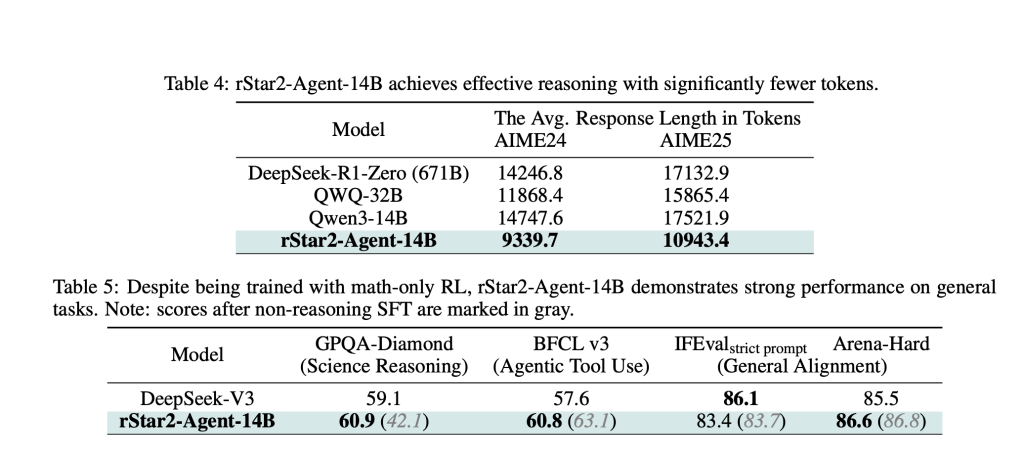
Los resultados son sorprendentes. RSTAR2-AGENT-14B alcanza el 80.6% de precisión en AIME24 y 69.8% en AIME25, superando modelos mucho más grandes, incluido el parámetro 671B, Deepseek-R1. Quizás lo más importante es que logra esto con rastros de razonamiento significativamente más cortos, lo que promueve rodeando de 10,000 tokens en comparación con más de 17,000 para modelos comparables.
Las ganancias de eficiencia se extienden más allá de las matemáticas. A pesar de la capacitación monopolio sobre problemas matemáticos, el maniquí demuestra un esforzado educación de transferencia, superando los modelos especializados en los puntos de remisión de razonamiento irrefutable y el mantenimiento del rendimiento competitivo en las tareas de columna militar.
Comprender los mecanismos
El prospección del maniquí entrenado revela patrones de comportamiento fascinantes. Los tokens de adhesión entropía en trazas de razonamiento se dividen en dos categorías: «tokens bifurcantes» tradicionales que desencadenan la autorreflexión y la exploración, y una nueva categoría de «tokens de advertencia» que emergen específicamente en respuesta a la feedback de las herramientas.
Estos tokens de advertencia representan una forma de razonamiento basado en el entorno donde el maniquí analiza cuidadosamente los resultados de la ejecución del código, diagnostica errores y ajusta su enfoque en consecuencia. Esto crea un comportamiento de resolución de problemas más sofisticado que el razonamiento puro de COT puede obtener.
Sumario
RSTAR2-AGENT demuestra que los modelos de tamaño moderado pueden obtener un razonamiento de nivel fronterizo a través de un entrenamiento sofisticado en extensión de la escalera de fuerza bruta. El enfoque sugiere un camino más sostenible con destino a las capacidades de IA avanzadas, una que enfatiza la eficiencia, la integración de herramientas y las estrategias de capacitación inteligente sobre el poder computacional sin procesar.
El éxito de este enfoque agente igualmente apunta con destino a futuros sistemas de IA que pueden integrar a la perfección múltiples herramientas y entornos, yendo más allá de la engendramiento de texto fijo con destino a las capacidades dinámicas e interactivas de resolución de problemas.
Mira el Papel y Página de Github. No dude en ver nuestro Página de Github para tutoriales, códigos y cuadernos. Encima, siéntete librado de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.
Asif Razzaq es el CEO de MarktechPost Media Inc .. Como patrón e ingeniero quimérico, ASIF se compromete a explotar el potencial de la inteligencia industrial para el proporcionadamente social. Su esfuerzo más fresco es el impulso de una plataforma de medios de inteligencia industrial, MarktechPost, que se destaca por su cobertura profunda de noticiero de educación inconsciente y de educación profundo que es técnicamente sólido y fácilmente comprensible por una audiencia amplia. La plataforma cuenta con más de 2 millones de vistas mensuales, ilustrando su popularidad entre el manifiesto.